앙상블(Ensemble) 방법
한 종류의 데이터로 여러 머신러닝 학습모델(기본모델)을 만들어 그 모델들의 예측결과를 다수결이나 평균을 내어 예측하는 방법
- 랜덤포레스트는 결정트리를 기본모델로 사용하는 앙상블 방법
- 결정트리들은 독립적으로 만들어지며 각각 랜덤으로 예측하는 성능보다 좋을 경우 랜덤포레스트는 결정트리보다 성능이 좋다
※ 결정트리는 트리의 깊이에 따라 과적합되는 경향이 있다
- 이것을 앙상블 모델인 랜덤포레스트로 해결 가능
배깅(Bagging / Bootstrap Aggregating)
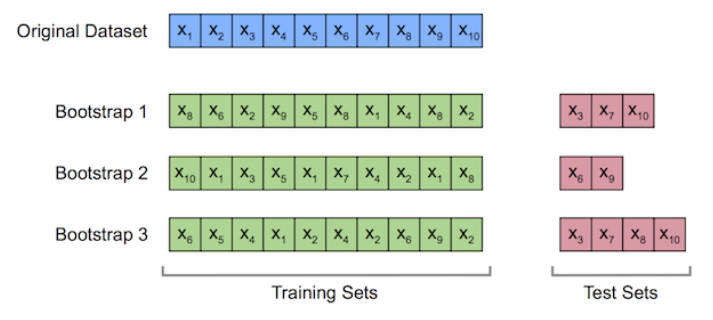
- 앙상블에 사용하는 작은 모델들은 부트스트래핑이라는 샘플링과정으로 얻은 부트스트랩세트를 사용해 학습을 한다
- 원본데이터에서 샘플링을 하는데 복원추출을 한다
(복원추출 – 샘플 하나 뽑고 기록하고 다시 돌려놓는 것)
(복원추출이기 때문에 부트스트랩세트에는 같은 샘플이 있을 수 있다)
n회 복원추출을 진행했을 때 그 샘플이 추출되지 않았을 확률
한 부트스트랩세트는 표본의 63.2%에 해당하는 샘플을 가진다
안뽑힌 36.8%이 Out of bag 샘플이며 이걸로 모델을 검증(val)한다
→ 이렇게 부트스트램세트로 만들어진 기본모델들을 합치는 과정이 Aggregation
※ 회귀문제 : 기본모델 결과들의 평균으로 결과를 냄
분류문제 : 다수결로 가장 많은 모델들이 선택한 범주로 예측
Ordinal Encoder(순서형 인코딩)
- 순서형인코딩은 범주에 숫자를 맵핑
ex) A, B, C → 1, 2, 3
범주의 종류가 많은(cardinality가 높은) 특성은 onehotencoder보다 ordinalencoder가 좋다
# 보통 설치를 해야 오류가 안난다
!pip install category_encoders
from category_encoders import OrdinalEncoder⚠️ 범주들을 순서가 있는 숫자형으로 바꾸기 때문에 순서 정보가 생긴다
범주들 사이에 분명한 순위가 있을때 전처리로 숫자를 정해주면 좋다
랜덤포레스트
-
랜덤포레스트는 기본모델들의 트리를 만들 때 무작위로 선택한 특성세트를 사용
-
결정트리에서 모든 특성(n개)을 고려하여 최적의 특성을 고르고 분할
-
랜덤포레스트에서는 특성 n개 중 일부분 k개의 특성을 선택 하고 이 k개에서 최적의 특성을 찾아내어 분할 이때 k개는 일반적으로 를 사용
from sklearn.ensemble import RandomForestClassifier※ 결정트리모델보다 상대적으로 과적합을 피할 수 있는 이유?
다르게 샘플링된 데이터로 과적합된 결정트리를 만들고 그 결과를 평균내 사용하는 모델이 랜덤포레스트
특성 중요도
- 특성들의 중요도 정보(Gini impurity)는 노드가 중요할 수록 불순도가 크게 감소한다는 사실을 이용
- 노드는 한 특성의 값을 기준으로 분리가 되기 때문에 불순도를 크게 감소하는데 많이 사용된 특성이 중요도가 올라간다
import matplotlib.pyplot as plt
pipe_ord = make_pipeline(
OrdinalEncoder(),
SimpleImputer(),
RandomForestClassifier(random_state=10, n_jobs=-1, oob_score=True)
)
# 특성 중요도(ordinal)
rf_ord = pipe_ord.named_steps['randomforestclassifier']
importances_ord = pd.Series(rf_ord.feature_importances_, X_train.columns)
# 상위 10개의 특성 시각화
n = 10
plt.figure(figsize=(10,n/4))
plt.title(f'Top {n} features with ordinalencoder')
importances_ord.sort_values()[-n:].plot.barh();※ 하이퍼파라미터
- max_depth (높은값에서 감소시키며 튜닝, 너무 깊어지면 과적합)
- n_estimators (적을경우 과소적합, 높을경우 긴 학습시간)
- min_samples_leaf (과적합일경우 높임)
- max_features (줄일 수록 다양한 트리생성, 높이면 같은 특성을 사용하는 트리가 많아져 다양성이 감소)
- class_weight (imbalanced 클래스인 경우 시도)

AI/Data Science