기준모델(Baseline Model)
예측 모델을 구체적으로 만들기 전에 가장 간단하고 직관적이면서 최소한의 성능을 나타내는 기준이 되는 모델
문제별 기준모델
- 분류문제 : 타겟의 최빈 클래스
- 회귀문제 : 타겟의 평균값
- 시계열회귀문제 : 이전 타임스탬프의 값
predict = df[target].mean() # 평균을 예측값으로 지정
errors = predict - df[target] # 예측값과 샘플값의 차이
mean_absolute_error = errors.abs().mean() # MAE 계산# 선형 회귀 시각화
import seaborn as sns
sns.regplot(x = df[feature], y = df[target])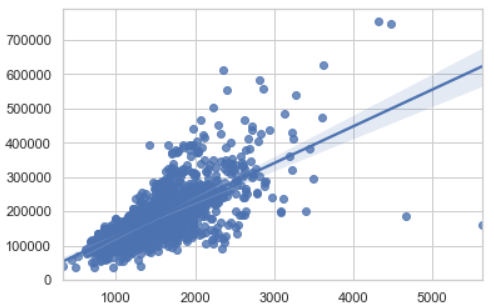
모델 데이터 구조
특성 데이터(feature)와 타겟 데이터(target)로 나누어 준다
특성행렬은 주로 X로 표현하고 보통 2차원 행렬이다
(주로 Numpy행렬이나 Pandas 데이터프레임으로 표현)
타겟배열은 주로 y로 표현하고 보통 1차원 형태이다
(주로 Numpy배열이나 Pandas 시리즈로 표현)

단순 선형 회귀(Simple Linear Regression)
fit() 메소드를 사용하여 모델을 학습
predict() 메소드를 사용하여 새로운 데이터를 예측
from sklearn.linear_model import LinearRegression
model = LinearRegression()
feature = ['F'] # df에 있는 어떤 특성과 타겟으로 나누기
target = ['T']
X_train = df[feature]
y_train = df[target]
model.fit(X_train, y_train) # 모델 학습
X_test = [[2000]]
y_pred = model.predict(X_test) # test데이터를 모델을 통해 예측
# 특성의 값이 2000일 때 예측값 = y_pred선형회귀모델의 계수(Coefficients)
계수 model.coef
절편 model.intercept
단순선형회귀식

AI/Data Science