1. Distributed Representation(분산 표현)
단어 자체를 벡터화하는 방법
분포가설 : “비슷한 위체에서 등장하는 단어들은 비슷한 의미를 가진다”
비슷한 의미를 지닌 단어는 주변 단어 분포도 비슷하다
- Word2Vec, fastText 는 벡터로 표현하고자 하는 타겟 단어가 해당 단어 주변 단어에 의해 결정
- 단어 벡터를 이렇게 정하는 이유는 분포가설 때문
① 원-핫 인코딩 : 단어를 쉽게 벡터화하는 방법
I am a student
I : [1 0 0 0] am : [0 1 0 0] a : [0 0 1 0] student : [0 0 0 1]- 단점 : 단어간 유사도를 구할 수 없다
- 단어간 유사도를 구할 때 코사인 유사도(cosine similarity)를 사용
- 원핫인코딩을 한 두 벡터의 내적은 항상 0이어서 코사인 유사도를 구해도 0이다 (따라서 두 단어 사이의 관계를 전혀 알 수 없다)
② 임베딩(Embedding)
단어를 고정 길이의 벡터, 차원이 일정한 벡터로 나타내기 때문에 '임베딩'이다
ex) [0.04227, -0.0033, 0.1607, -0.0236, ...] 연속적인 값
2. Word2Vec
단어를 벡터로(Word to Vector) 나타내는 임베딩 방법
특정 단어 양 옆에 있는 두 단어의 관계를 활용하기 때문에 분포가설을 잘 반영한다
CboW / Skip-gram
- CBoW(Continuous Bag-of-Words) : 주변 단어에 대한 정보를 기반으로 중심 단어의 정보를 예측하는 모델
- Skip-gram : 중심단어의 정보를 기반으로 주변 단어의 정보를 예측하는 모델(skip-gram의 성능이 조금 더 좋다)
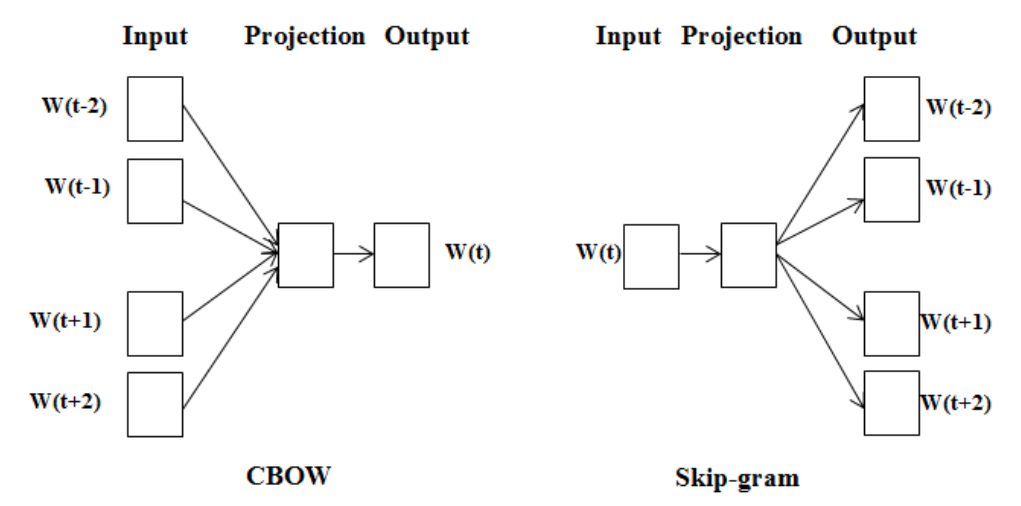
- Word2Vec(skip-gram)모델의 구조
- 입력 : Word2Vec의 입력은 원-핫 인코딩된 단어 벡터
- 은닉층 : 임베딩 벡터의 차원수 만큼의 노드로 구성된 은닉층이 1개인 신경망
- 출력층 : 단어 개수 만큼의 노드로 이루어져 있으며 활성화 함수로 소프트맥스를 사용
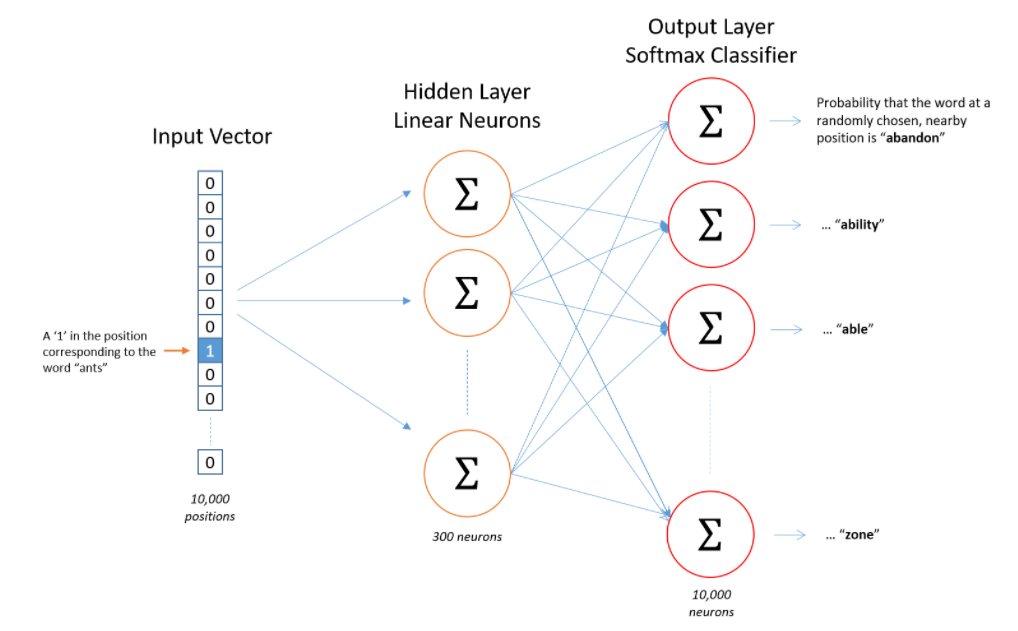
ex) 10000개의 단어에 대해서 300차원의 임베딩 벡터를 구함
입력층 10000 position, 은닉층 300뉴런, 출력층 10000뉴런
- Word2Vec(skip-gram) 학습을 위한 학습 데이터 디지인
window 사이즈가 2인 Word2Vec 이므로 중심 단어 옆에 있는 2개 단어에 대해 단어쌍을 구성
ex) "The tortoise jumped into the lake"
중심단어 The, 주변 문맥 단어 tortoise, jumped
학습 샘플 : (the, tortoise), (the, jumped)
중심 단어 : jumped / 주변 문맥 단어 : the, tortoise, into, the
학습 샘플: (jumped, the), (jumped, tortoise), (jumped, into), (jumped, the)Word2Vec으로 임베딩한 벡터 시각화
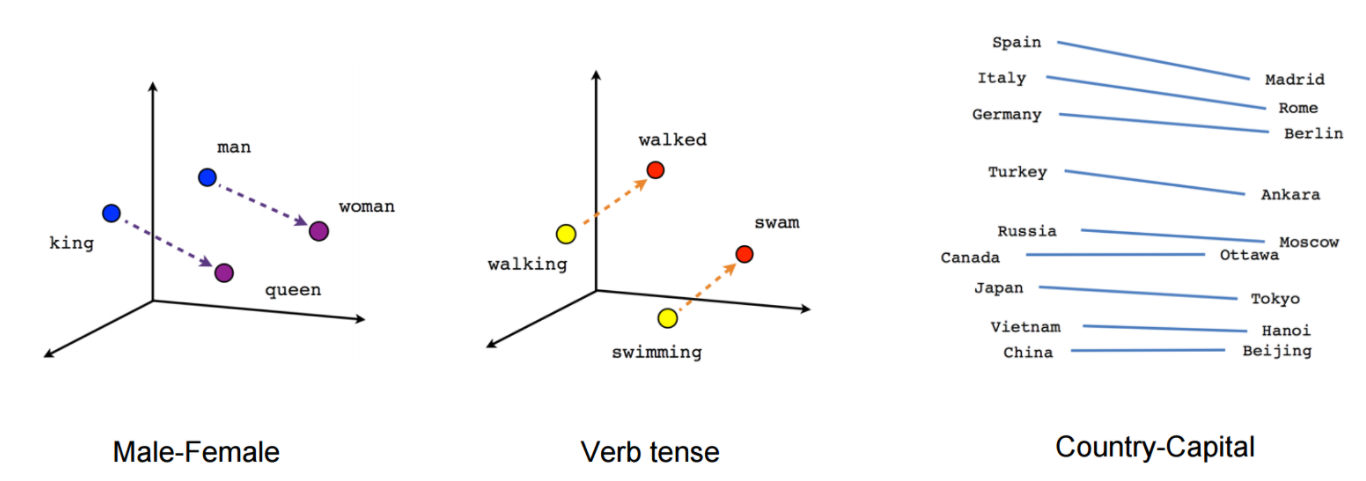
- Word2Vec을 통해 얻은 임베딩 벡터는 단어 간의 의미적, 문법적 관계를 잘 나타낸다
- 단점 : Word2Vec은 말뭉치에 등장하지 않는 단어는 벡터화 할 수 없다
!pip install gensim --upgrade
import gensim
gensim.__version__ → 4.0.1 확인
# 구글 뉴스 말뭉치
import gensim.downloader as api
wv = api.load('word2vec-google-news-300')
# 단어간 유사도 파악 genism패키지의 .similarity이용
pairs = [
('car', 'minivan'),
('car', 'bicycle'),
('car', 'airplane'),
('car', 'cereal'),
('car', 'democracy')
]
for w1, w2 in pairs:
print(f'{w1} ====== {w2}\t {wv.similarity(w1, w2):.2f}')
→ car ====== minivan 0.69
car ====== bicycle 0.54
car ====== airplane 0.42
car ====== cereal 0.14
car ====== democracy 0.08 출력
# .most_similar 메서드 / .doesnt_match메서드도 있다3. fastText
Word2Vec 방식에 철자기반의 임베딩 방식을 더해준 새로운 임베딩 방식
OOV(Out of Vocabulary)문제
- 모든 단어가 들어있는 말뭉치는 없기 때문에 Word2Vec은 말뭉치에 등장하지 않은 단어에 대해서는 임베딩 벡터를 만들지 못한다는 단점이 있다
- 기존 말뭉치에 등장하지 않는 단어가 등장하는 문제를 OOV문제라고 한다
- 적게 등장하는 단어에 대해서는 학습이 적게 일어나기 때문에 적절한 임베딩 벡터를 생성하지 못하는 것도 단점이다
- fastText는 없는 단어도 꽤 높은 정확도로 두 단어의 임베딩 벡터를 구하고 유사도를 나타낼 수 있다
철자 단위 임베딩(Character level Embedding)
모델이 학습하지 못한 단어더라도 잘 쪼개서 보면 말뭉치에서 등장했던 단어를 통해 유추해 볼 수 있다
※ fastText가 Character-level(철자 단위) 임베딩을 적용하는 법 : Character n-gram
fastText는 3~6개로 묶은 character 정보(3~6grams)단위를 사용
3~6개 단위로 묶기 이전에 모델이 접두사와 접미사를 인식할 수 있도록 해당 단어 앞뒤로 <, >를 붙인다 그리고 해당 단어를 3~6개 character-level로 잘라서 임베딩을 적용한다
ex) <eating>
3grams → <ea eat ati tin ing ng>
4grams → <eat eati atin ting ing>
# 이런식으로 6grams까지 해서 벡터를 생성하고
# 18개의 character-level n-gram을 얻을 수 있다- 철자 단위 임베딩 적용하기
eating이라는 단어가 말뭉치 내에 있다면 skip-gram으로부터 학습한 임베딩 벡터에 위에서 얻은 18개의 character-level n-gram들의 벡터를 더해준다
eating이라는 단어가 말뭉치 내에 없다면 18개의 character-level n-gram들의 벡터만으로 구성한다
from pprint import pprint as print
from gensim.models.fasttext import FastText
from gensim.test.utils import datapath
corpus_file = datapath('lee_background.cor')
model = FastText(vector_size=100)
model.build_vocab(corpus_file=corpus_file)
model.train(
corpus_file=corpus_file, epochs=model.epochs,
total_examples=model.corpus_count, total_words=model.corpus_total_words,
)
ft = model.wv
# 말뭉치에 있는지 없는지 확인
print('night' in ft.key_to_index) → True
print('nights' in ft.key_to_index) → False
# 두 단어의 유사도 파악
print(ft.similarity("night", "nights")) → 0.9999918
AI/Data Science