1. 하이퍼파라미터(hyperparameter) 튜닝
- 입력 데이터 정규화(Normalizing)
신경망에서는 정규화가 무조건 필요하지는 않다
신경망이 수치형 데이터를 받으면 자체적으로 적절한 가중치를 학습하기 때문
정규화를 해주면 학습을 빠르게 해주고, 최적화 과정에서 지역 최적점(local optimum)에 빠질 위험을 줄인다
1. Baby sitting
- 100% 수작업으로 파라미터를 수정
- 학계에서 논문을 출간할 수 있을 정도로 놀라운 정확도를 보여주는 하이퍼파라미터의 수치를 찾아내기 위해 쓰는 방법
- 이를 위해서 실험자의 경험이나 도메인 지식이 필요하기도 하다
2. Grid search
- 하이퍼파라미터마다 탐색할 지점을 정해주면 모든 지점에 해당하는 조합을 알아서 수행
- 범위를 너무 많이 설정하면 끝나지 않을 수도 있다
ex) 5개의 파라미터에 대해 각각 5개의 지점을 지정해주면 총 5^5=3125번의 모델 학습을 진행 + 5번의 교차검증까지 하면 3125 * 5 = 15625번 학습 수행 / 1번 학습에 10분이면 3달반 - 모델 성능에 보다 직접적인 영향을 주는 하이퍼파라미터가 따로 있기 때문에 굳이 많은 파라미터 조정을 시도할 필요는 없다
3. Random search
- 지정된 범위 내에서 무작위로 모델을 돌려본 후 최고 성능의 모델을 반환
시도횟수를 정해줄 수 있기 때문에 grid search에 비해 적은 횟수로 끝마칠 수 있음 - grid search에서는 파라미터의 중요도가 모두 동등하다고 가정
random search는 상대적으로 중요한 하이퍼 파라미터에 대해서는 탐색을 더 하고, 덜 중요한 하이퍼 파라미터에 대해서는 실험을 덜 하도록 한다
4. Bayesian Methods
- baby sitting 이나 grid search 등의 방식에서는 탐색 결과를 보고 결과 정보를 다시 새로운 탐색에 반영하면 성능을 더 높일 수 있다
- 베이지안 방식은 이전 탐색 결과 정보를 새로운 탐색에 활용하는 방법
파라미터 탐색 효율을 높일 수 있다
2. 튜닝 가능한 하이퍼파라미터
- 배치 크기(batch_size)
- 반복 학습 횟수(에포크, training epochs)
- 옵티마이저(optimizer)
- 학습률(learning rate)
- 활성화 함수(activation functions)
- Regularization(weight decay, dropout 등)
- 은닉층(Hidden layer)의 노드(Node) 수
1. 배치 크기(Batch size)
- 순전파/역전파를 통해 모델의 가중치를 업데이트 할 때마다 매iteration 마다 몇 개의 입력 데이터를 볼지를 결정하는 파라미터
- 배치 사이즈를 너무 크게 하면 한번에 많은 데이터에 대한 loss를 계산해야 한다는 단점
- 가중치 업데이트가 빠르게 이루어지지 않고 주어진 epoch 안에 충분한 횟수의 iteration을 확보할 수 없다
- 파라미터가 굉장히 많은 모델에 큰 배치 사이즈를 적용하면 메모리를 초과해 버린다
- 반대로 배치 사이즈를 너무 작게 설ㄹ정하면 학습 시간이 오래걸리고 노이즈가 많이 발생한다
(일반적으로 배치 사이즈는 32~512 사이의 2의 제곱수로 결정, 케라스 배치사이즈의 기본값은 32)
※ 이미지 처리에서 32이하의 배치 사이즈를 잘 설정하면 일반화 성능을 높일 수 있다
2. 옵티마이저(optimizer)
- adam 이라는 옵티마이저가 꽤 좋은 성능을 보장하기 때문에 많이 사용
- 모든 경우에 좋은 옵티마이저란 없다
- 데이터셋에 따라 적절한 옵티마이저를 설정해야 한다
- 어떤 옵티마이저를 선택하는지에 따라서 최적의 하이퍼 파라미터 값이 달라진다. 그래서 옵티마이저를 다르게 해줄 때마다 적절한 학습률(learning rate)과 모멘텀(momentum) 등을 다르게 설정해줘야 한다
3. 학습률(Learning rate, lr)
- 옵티마이저에서 지정해 줄 수 있는 하이퍼파라미터 중 하나
- 케라스의 기본 학습률은 0.001로 설정되어 있다
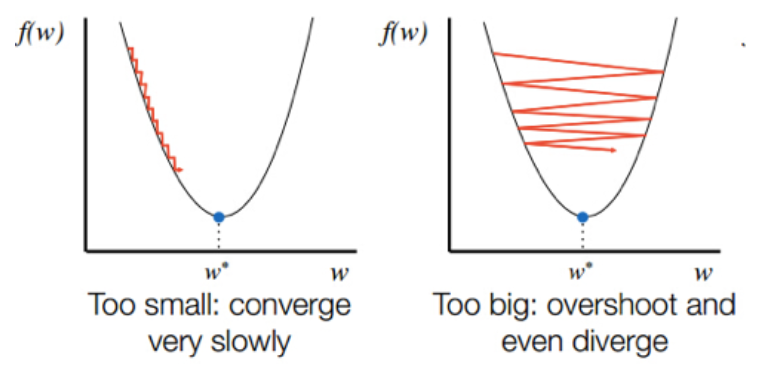
- 학습률이 너무 높으면 경사 하강 과정에서 발산하면서 모델이 최적값을 찾을 수 없다
- 반대로 너무 낮게 설정하면 최적점에 이르기까지 너무 오래 걸리거나 주어진iteration 내에서 모델이 수렴하는데 실패한다
ex) [0.001, 0.01, 0.1, 0.2, 0.3, 0.5]정도로 넓은 범위에서 크기 순으로 튜닝해보고 만약 0.1이 가장 좋은 성능이였다면 [0.05, 0.08, 0.1, 0.12, 0.15]정도로 시도한다 - 학습률을 조정하면 최적값에 도달할 수 있는 iteration의 횟수 역시 변경된다
그래서 학습률을 튜닝할 때에는 epoch의 횟수도 함께 튜닝해주는 것이 좋다
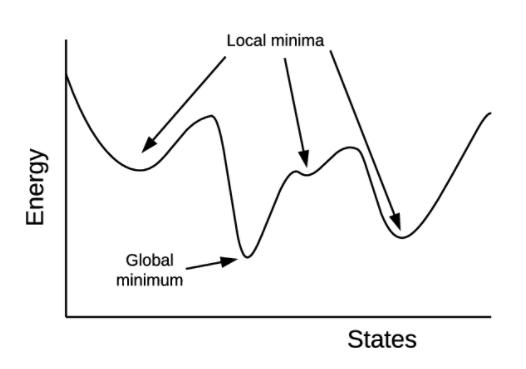
4. 모멘텀(momentum)
- 옵티마이저에 관성을 부여하는 하이퍼파라미터
- 이전 iteration에서 경사 하강을 한 정도를 새로운 iteration에 반영한다
- 지역 최저점에 빠지지 않을 수 있도록 한다
5. 가중치 초기화(Network weight initialization)
- 초기 가중치를 어떻게 설정할 지를 결정하는 가중치 초기화는 신경망에서 매우 중요하다
- 초기화 방법 : init_mode = ['uniform', 'lecun_uniform', 'normal', 'zero', 'glorot_normal', 'glorot_uniform', 'he_normal', 'he_uniform']

AI/Data Science