1. 손실함수 혹은 오차 함수
문제의 종류에 따라 함수를 선택해야 한다
종류는 크게 2가지 : 평균 제곱을 기반으로 하는 손실함수 / 엔트로피를 기반으로 하는 손실함수
- 평균 제곱을 기반으로 하는 손실함수
- MSE / RMSE / MAE / R-Squared
- 엔트로피를 기반으로 하는 손실함수
- BCE(binary crossentropy), CCE(categorical crossentropy)
2. 과적합을 방지하기 위한 방법 (Regularization Strategies)
신경망은 매개변수가 매우 많은 복잡한 모델이어서 훈련데이터에 쉽게 과적합 되는 경향이 있다
1. 조기종료(early stopping)
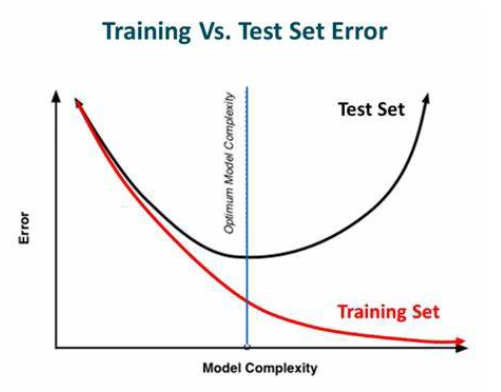
- 학습 데이터에 대한 손실을 계속 줄어들지만 검증 데이터셋에 대한 손실은 증가한다면 학습을 종료
from tensorflow.keras.datasets import fashion_mnist
# 데이터 불러오기
(X_train, y_train), (X_test, y_test) = fashion_mnist.load_data()
# 데이터 정규화
X_train = X_train / 255.
X_test = X_test /255.
# 기본적인 신경망
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
import keras, os
# 모델 구성
model = Sequential([
Flatten(input_shape=(28, 28)),
Dense(10, activation='softmax')
])
model.compile(optimizer='adam'
, loss='sparse_categorical_crossentropy'
, metrics=['accuracy'])
# 변수 설정
batch_size = 30
epochs_max = 1
# 학습시킨 데이터를 저장시키기 위한 코드
checkpoint_filepath = "FMbest.hdf5"
# overfitting을 방지하기 위해서 학습 중 early stop을 수행
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', min_delta=0, patience=10, verbose=1)
# Validation Set을 기준으로 가장 최적의 모델을 찾기
save_best = tf.keras.callbacks.ModelCheckpoint(
filepath=checkpoint_filepath, monitor='val_loss', verbose=1, save_best_only=True,
save_weights_only=True, mode='auto', save_freq='epoch', options=None)
# 모델 학습
model.fit(X_train, y_train, batch_size=batch_size, epochs=epochs_max, verbose=1,
validation_data=(X_test,y_test),
callbacks=[early_stop, save_best])
# 체크포인트에 저장된 가중치들을 불러들이기
model.load_weights(checkpoint_filepath)
# best model을 이용한 테스트 데이터 예측 정확도 재확인
model.predict(X_test[0:1])
test_loss, test_acc = model.evaluate(X_test, y_test, verbose=1)2. 가중치 감소(weight decay)
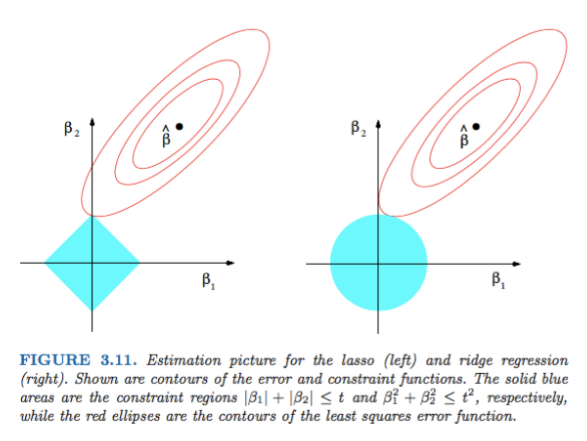
- 가중치의 값이 클 때 주로 과적합이 발생
- 가중치 감소에서는 손실함수에 가중치와 관련된 항을 추가하여 값이 너무 커지지 않도록 조정
- 가중치 항을 어떻게 추가할지에 따라 L1 Regularization / L2 Regularization 로 나뉜다(Ridge, Lasso와 동일 개념)
from tensorflow.keras import regularizers
# 모델 구성
model = Sequential([
Flatten(input_shape=(28, 28)),
Dense(64,
kernel_regularizer=regularizers.l2(0.01), # L2 Regularization
activity_regularizer=regularizers.l1(0.01)), # L1 Regularization
Dense(10, activation='softmax')
])
model.compile(optimizer='adam'
, loss='sparse_categorical_crossentropy'
, metrics=['accuracy'])
# 모델 학습
model.fit(X_train, y_train, batch_size=30, epochs=1, verbose=1,
validation_data=(X_test,y_test))3. 가중치 제한(weight constraint)
- 특정 가중치를 제거하거나 범위를 수동으로 제한하는 방법
(유사 방법으로 Weight Decusion and Weight Restriction이 있다)
from tensorflow.keras.constraints import MaxNorm
# 모델 구성
model = Sequential([
Flatten(input_shape=(28, 28)),
Dense(64,
kernel_regularizer=regularizers.l2(0.01),
activity_regularizer=regularizers.l1(0.01),
kernel_constraint=MaxNorm(2.)), # 가중치 제한
Dense(10, activation='softmax')
])
model.compile(optimizer='adam'
, loss='sparse_categorical_crossentropy'
, metrics=['accuracy'])
# 모델 학습
model.fit(X_train, y_train, batch_size=30, epochs=1, verbose=1,
validation_data=(X_test,y_test))4. 드롭아웃(dropout)
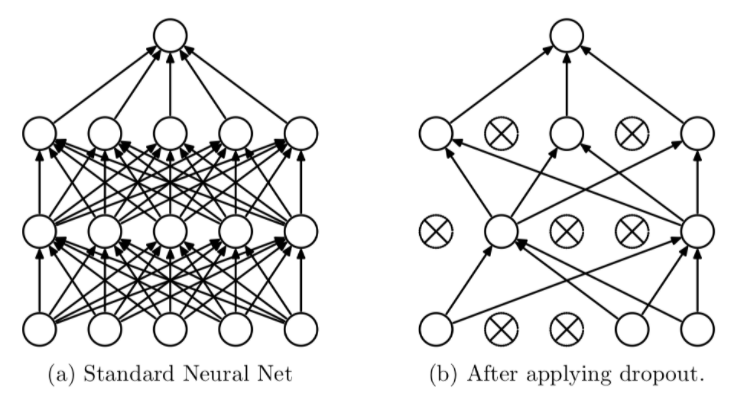
- iteration 마다 레이어 노드 중 일부를 사용하지 않으면서 학습을 진행하는 방법
- 매번 다른 노드가 학습되면서 전체 가중치가 과적합되는 것을 방지한다
- 복잡한 하나의 모델로 예측하지 않고 간단한 여러가지 모델로 예측하여 그 결과를 합쳐서 사용
from tensorflow.keras.layers import Dropout
# 모델 구성
model = Sequential([
Flatten(input_shape=(28, 28)),
Dense(64,
kernel_regularizer=regularizers.l2(0.01),
activity_regularizer=regularizers.l1(0.01),
kernel_constraint=MaxNorm(2.)),
Dropout(0.5),
# 드롭아웃(1 - 0.5만큼을 곱해서 줄임)
Dense(10, activation='softmax')
])
model.compile(optimizer='adam'
, loss='sparse_categorical_crossentropy'
, metrics=['accuracy'])
# 모델 학습
model.fit(X_train, y_train, batch_size=30, epochs=1, verbose=1,
validation_data=(X_test,y_test))3. 학습률 감소/계획(Learning rate Decay/Scheduling)
학습률 감소
# 옵티마이저의 하이퍼파라미터 조정
tf.keras.optimizers.Adam(
learning_rate=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-07, amsgrad=False,
name='Adam'
)
# 기존 모델에 적용
model.compile(optimizer=tf.keras.optimizers.Adam(lr=0.001, beta_1 = 0.89)
, loss='sparse_categorical_crossentropy'
, metrics=['accuracy'])학습률 계획
# 학습률 계획 지정 후 옵티마이저에 반영
lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate=1e-2,
decay_steps=10000,
decay_rate=0.9)
# 모델에 적용
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=lr_schedule)
, loss='sparse_categorical_crossentropy'
, metrics=['accuracy'])
AI/Data Science