QSAR이란?
Construction of a mathematical model relating a molecular struture to a chemical property or biological effect by means of statistical techniques
- Link between toxicity and structures
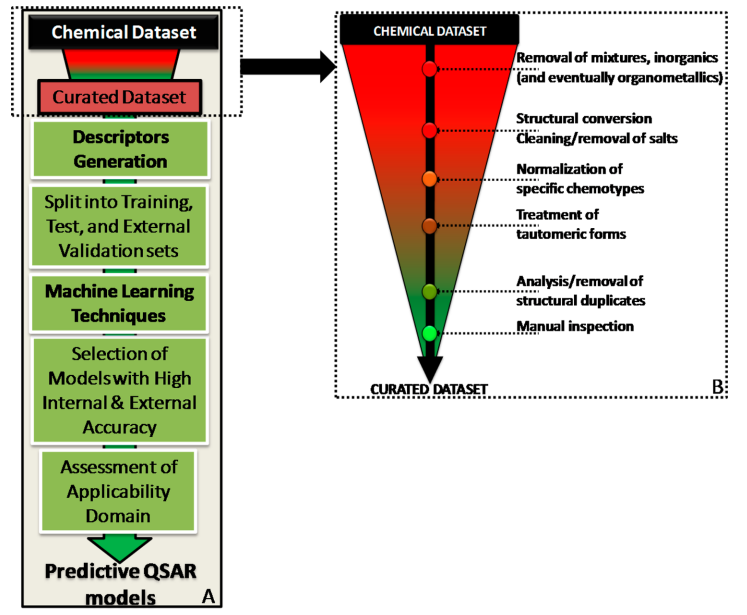
QSAR 모델링 과정
Workflow for predictive QSAR modeling
QSAR model을 통해 virtual screening & Molecluar design 수행
*curated data를 만들어주는 프로그램들도 있다. [https://jcheminf.biomedcentral.com/articles/10.1186/s13321-020-00456-1]
[https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5992871/]
removal of mixutre, inorganic : 혼합화합물 제외, 무기화합물 제외
Structural conversion cleaning/removal of salts: 염화수소 제외..?
1. Component
- 화합물 데이터 셋 : a set of chemical structures that are represented by molecular descriptors
- Activity 데이터: a set of observed 'activities' associated with the structures
-
어떤 질병 target에 binding 하는지에 대한 정보
*Any form of experimental observation, not limited to biological activites
-
- Statistical modeling method to identify the key relationship between the molecular descriptors and the activities
2. Preperation
- 'Garbage-in Garbage-out' principle : 데이터의 중요함
- There are many ways in which erroneous or misleading models cna be produced
- Data, Statistical method problems
- Checking
-
observations are consistent (preferably obtained from a single experimental source)
-
다른 assay에서 얻어진 data는 가능한한 단일 모델에 combining하면 안된다.
⇒ Data consistency checking! 서로 다른 기관에서 얻어진 데이터는 consistency가 떨어진다.
-
- data point evenly spread (데이터 구성이 골고루 되어있는지)
- We cannot be sure that what is not reported is indeed negative
3. Data spliting
- Random
- Stratified : 비율유지
- Cluster-based (scaffold split) : 데이터 similarity 를 바탕으로 클러스터링 하여 클러스터 기반으로 데이터 분리 (어떤 경우?: 구조가 좀 달라진 새로운 화합물에 대해서 얼마나 잘 예측하는지를 알아보기 위해..?)
- Temporal (for time-series prediction)
- Chembl20 (training)
- Chembl21 (test)
- 미래에 사용할 데이터에 대해서 예측하기 위해..
4. Assesing model Performance
- regression problem : MSE, MAE, pearson correlation coefficient, spearan rank correlation
- classification problem : accuracy, precision, recall, F1 score, AUC, PRC
5. Applicability domain
A QSAR model can be expected to provide predictions on compound that are represented by the structures in the training set.
적용이 가능한가?
- Distance-to-model-based metrics are perhaps the most studied and quantify the distance of a test compound from the compound in te model training set. ⇒ 가장 자주 사용
- Local error method estimated the reliability of a prediction according to the prediction error of similar compounds with know measurement
- similar compound를 가지고 prediction했을 때 결과를 통해 판단
- Bagging method use the variance of the prediction from individual model across an ensemble to indeicate the reliability of the predictions
- Sensitivity-based methods involve perturbing the input descriptors of a test compoudn to see ow it affects the model's prediction
- 모델의 structure를 약간 바꿨을 때 predictied bioactivity가 바뀌는 지를 보고 판단
6. Data size
데이터셋의 사이즈는 너무 작으면 안됨
When a dataset includes more compounds
-
Select a diverse subset of compounds
-
Cluster a dataset and build models separately for each cluster
- Applicable domain이 다른 QSAR모델이 build될수있다.
-
In case of classification or category QSAR when compounds belong to a small data number of activity classes or categories, it is possible to exclude many compounds from model development.
-
Lower limit
Continuous repose variable (activity)
the number of compounds in the traning set should be at least 20
about 10 compounds should be in each of the test and external evlaution set
Classification or category reponse variable
traing : at least 10 compounds of each class
test and external evfaluation less than 5 compounds
-
Activity values
Continuous response variable
Total range of activities: at least five times higher than the experimental error →전체 데이터 범위가 실험오류의 범위보다 5배 이상 정도 커야한다.?
No large gaps : that exceed 10%-15% of the entire range of activities between two consecutive values of activities
Classification or category QSAR
적어도 20개 compound of each class
class간 compound 개수는 같을수록 좋다.
QSAR-based virtual screening
(*Ligand-based VS)
From Chemical Library ——————— Virtual Screening ———————> Potential Hits
## in virtual screening
1. Empirical Rules
: 신약이 될 가능성이 전혀 없는것들은 걸러냄 (ex) Ro5, QED
2. Chemical Similarity Filter
: Similarity가 너무 높거나 낮아서 QSAR모델을 적용하기 어려운 것들을 filtering
3. QSAR-based Filters
4. Feasibility/Availability
: SAS(synthetic Accessibility) 등Target prediction and optimization (using QSAR)
From 이미 알려져있는 약물
약물에 대해 각각의 Target에 대한 QSAR 모델을 테스트하면, 어떤 target에 binding하는 지 알 수 있다.
Specificity를 높이고, off-target에 대한 binding affinity를 낮출 수 있도록 lead optimization 가능
출처 : LAIDD 강의
