G(생성 모델)의 목적
내가 닮고자 하는 data의 분포와 가장 유사하도록 Generator의 분포를 형성
data의 분포 : Pdata
Generator의 분포 :Pg
따라서 Pdata와 Pg의 거리를 최소로 만들어 주는 것 (최상의 경우)
(두 확률 분포를 완전히 같게 만들어)
Pdata = Pg
그렇다면
Pdata와 G의 분포가 일치할 때 전역 최적이며, 그때 Pdata= Pg 여야 함
- Algorithm1을 수행했을 시 Converge(수렴) 해야함
Pdata= Pg인 해를 실제로 찾을 수 있는 가?
어떤 파라미터가 모든 경우를 통틀어 최적인 경우를 전역 최적(global optimum)
최적점에서는 기울기가 항상 0
더 이상 줄어들 오차가 없음
[증명]
Proposition 1
어떤 고정된 G(생성자)에 대하여 최적의 D(판별자)는 다음과 같다.
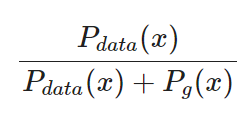
GAN의 V(D, G)는 다음과 같음
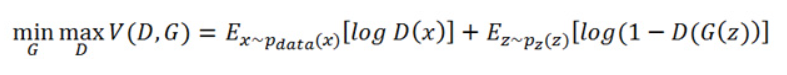
1단계
G(생성자)가 고정됐다고 가정
- min 대신 arg
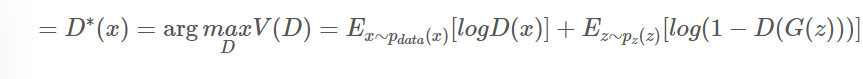
D*(x)는 optimal D를 뜻함
- Pz(z)를 Pg(x)로 바꾸기
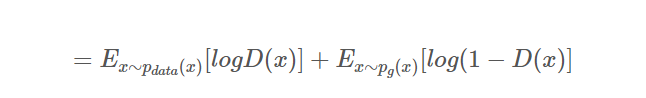
Z를 Pz에서 샘플링해 생성자에 주고 생성자가 생성한 가짜 이미지는 Pg를 따르게 됨.
-> X를 Pg에서 샘플링 하는 것
2단계
Expectation(기댓값)의 정의 사용
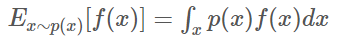
기댓값의 정리를 사용하여 적분식으로 바꾼 V(D, G)는
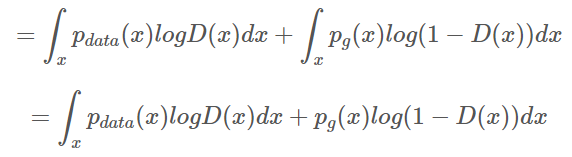
3단계
G(생성자)는 고정 되었고
D(판별자)는 max로 가기 때문에
아래 식을 최대화 해야한다
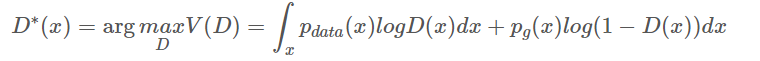
적분식을 최대화 == 적분 안의 식을 최대화
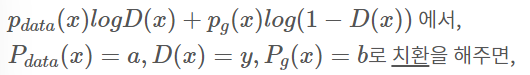
alogy + blog(1-y)
위 식을 미분하여 y=0인 지점을 구하면
y=a/a+b
따라서 Proposition 1이 성립한다.
4단계
최적의 D(판별자) D*을 이용해 V(D, G)를 다시 써봄
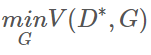
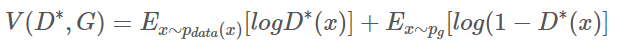
다시 기댓값 정리 이용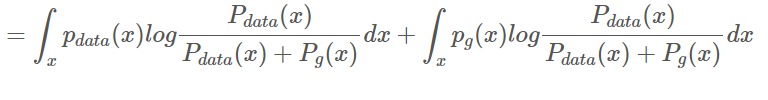
log4, -log4 더하기 (log4=2log2)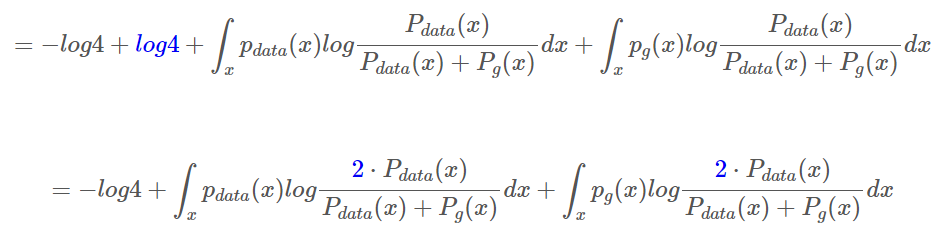
5단계
KL Divergence 사용
→어떤 두 함수의 확률분포가 얼마나 다른지 그 차이를 측정하는 식
모델 분포 간 얼마나 가까운지에 대해 정보 손실량의 기댓값
KL Divergence의 식
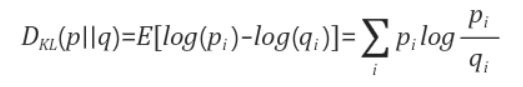
KL Divergence 사용해서 pmf를 바꿀 수 있음
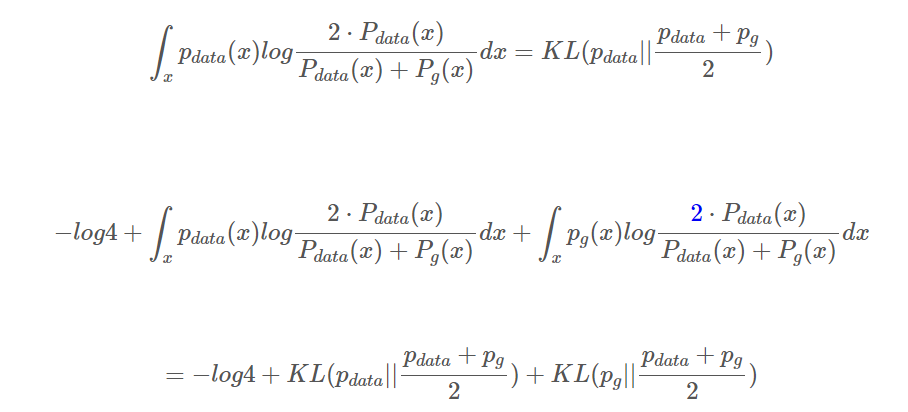
하지만 KL은 Symmetric하지 않음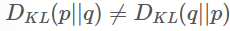
KL을 Symmetric하게 개량한 JSD를 사용한다
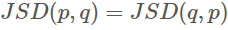
위의 식이므로 두 확률 분포의 거리로서의 역할을 할 수 있다.
JSD의 식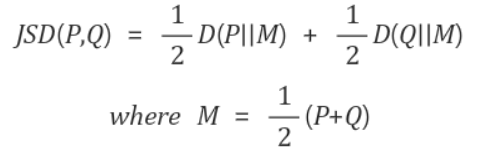
6단계
Jenson-Shannon divergence(JSD)로 다시 정리
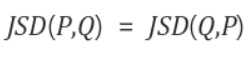
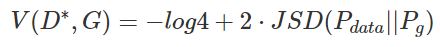
P, Q가 같을 떄 JSD는 0이 됨
두 확률 분포 사이의 거리가 0이므로(같으면 var()이 0임)
이것을 적용하여 식 도출
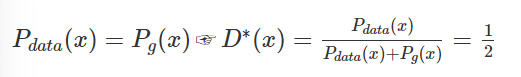
V(D, G)를 최적화 하는 것은 위 식의 값을 최소화 하는 것
(위 식에서 최적화된 D(D*)을 찾았다면 minG이기 때문에)
JSD는 Pdata와 Pg가 일치할때만 0, 그외에는 양수값
이기 때문에
V(D, G)의 전역 최적(global optimum)은 Pdata = Pg 일 때이다.
더하여 Pdata = Pg 인 경우는 unique solution(하나의 경우)이여야 한다,
ㄴ> unique solution(하나의 경우)임도 증명됨
레퍼런스
https://memesoo99.tistory.com/27
