GAN의 기본정보
생성 모델 → 실존하지는 않지만 있을 법한 이미지를 생성할 수 있는 모델
GAN에서 다루고자하는 모든 데이터
→ 확률분포를 가지고 있는 RV(random variable)
- 확률분포를 알면 그 데이터의 예측 기대값, 데이터의 분산을 알 수 있음
- 데이터의 통계적 특성을 분석 가능
→ 주어진 확률분포를 따르도록 데이터를 임의생성
→데이터는 확률분포를 구할 때 사용한 원데이터와 유사한 값을 가짐
즉. 확률분포를 모델링할 수 있게 되면, 원데이터와 확률분포를 공유하는 무한히 많은 새로운 데이터를 생성할 수 있음을 의미
- G(생성자)와 D(판별자)가 경쟁적으로 학습
- 진짜/가짜 구별 못하도록 하는게 최종 목표
- G는 원데이터의 확률분포를 알아내려고 노력
- 학습이 종료된 이후에는 원데이터의 확률 분포를 따르는 새로운 데이터를 만듬
(D는 더이상 분류해도 의미가 없는 0.5라는 확률값을 뱉어냄)
(0.5면 D가 의미가 없음)
G(생성자)
latent code(잠재적인 코드)를 가지고 해당 데이터를 가지고 training 데이터가 되도록 학습
특정 Training 데이터가 되도록 스스로 변화하며 학습
D(판별자)
input 데이터가 들어갔을 때, 해당 input 값이 어떤 것인지 Classify
진짜(1)인지 가짜(0) 인지를 output으로 줌
따라서 G의 목적은
D(G(z)) = 1 을 만족 시키는 것
(만든 데이터를 D에 넣었을 때 1(진짜)라고 결과가 나오는 것)
Loss function(손실 함수)
최적화를 통해 G와 D를 동시에 훈련
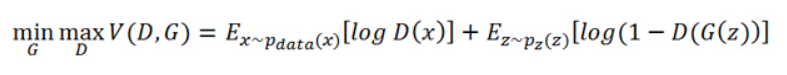
x = 진짜 데이터
z = 가짜 데이터 (G가 생성함)
손실 함수는 생성자의 손실 함수, 판별자의 손실 함수의 형태를 가짐.
→ 둘다 이진 크로스 엔드로피 손실 함수
생성 모델(G) 입장에서 V(D, G)의 이상적인 결과
G가 D가 구별해내지 못할 정도 잘 생성해야함
첫번째 항: D가 구별해내는 것에 대한 항, G의 성능에 의해 결정 X → 무시
- pdata(x)는 실제 데이터의 분포
- Ex는 pdata(x) 분포에서 가져온 실제 데이터 x에 대한 기대값
- D(x)는 판별자가 실제 데이터 x를 진짜로 정확히 판별하는 확률
- 첫 번째 항은 실제 데이터를 판별자에 입력하여 실제 데이터를 진짜로 판별하도록 유도
두번째 항: G가 생성해낸 데이터 → D를 속일 수 있는 데이터라고 가정 → D(G(z)) = 1
-
pz(z)는 잠재 공간의 분포
- 잠재 공간은 생성자(G)의 입력으로 사용되는 공간
- 생성자는 이 공간에서 잠재 벡터(z)를 샘플링하여 가짜 데이터를 생성
- 잠재 공간은 생성자(G)의 입력으로 사용되는 공간
-
z는 잠재 벡터(랜덤 노이즈)
- 특정한 분포로 가정될 수 있음(유니폼, 가우시안..등 등)
- 랜덤 노이즈
- 얼룩말 학습할 때, 얼룩말의 무늬나 색상을 다양하게 생성하기 위해 활용할 수 있음
-
Ez는 pz(z) 분포에서 가져온 잠재 벡터 z에 대한 기대값
-
G(z)는 생성자가 잠재 벡터 z를 입력으로 받아 생성한 가짜 데이터
-
D(G(z))는 판별자가 가짜 데이터 G(z)를 진짜로 정확히 판별하지 못하는 확률
-
두 번째 항은 생성자를 통해 생성된 가짜 데이터를 판별자가 가짜로 정확히 판별하도록 유도
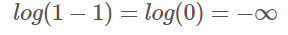
G 입장에서 얻을 수 있는 이상적인 결과, 최솟값은 '마이너스 무한대'
→G의 목적은 D(G(z)) = 1 을 만족 시키는 것이기 때문에
D 입장에서 가장 이상적인 결과
반대로 D 입장에서 가장 이상적인 결과는 log(1-0)=log1=0
→ D가 모든 가짜 데이터를 구별한다면 D(G(z)) = 0
(+ 모든 진짜 데이터를 진짜라고 구별한다면 logD(x)=1)
( x는 진짜 데이터 )
