⚾ 야구 선수 연봉 예측 과제
📝 과제 진행하면서 고민했던 부분들
고민 1. 선발은 뭐고 마무리는 뭘까?
선발 > 마무리 인식
선발선수는 이닝이 높다. -> 이닝이 뭔데?
-> 한 투수의 모든 이닝을 합쳐서 가장 많이 아웃카운트를 잡은 투수가 이닝 순위 1등
투수가 뭔지 헷갈려서 일단 사전조사부터 했다.
네이버 동영상백과 :https://terms.naver.com/entry.naver?docId=2446958&cid=51673&categoryId=51690
야구에서 공격 팀의 타자에게 공을 던지는 선수
아웃카운트 : 공격측 플레이어 몇 사람을 아웃시켰는가를 셈하는 수치. 공격측 플레이어 세사람을 아웃시키면 두 팀은 공수의 임무를 교대.
즉 선발투수가 마무리투수보다 공격플레이어 아웃을 더 많이 시킨다는 인식?
고민 2. 한 선수의 여러 년도 데이터들이 있는데, 어느 것을 가져올까?
- 1983년 ~ 1988년 사이 선수의 데이터는 Best 데이터만 사용
- 해당 모든 년도의 데이터를 가져와 gruopby로 agg평균을 사용할까 생각했지만 연봉지표를 보니 연봉이 3년만에 두 배로 뛰거나 하는 차이가 있었다
- 다른 선수들 또한 연봉 변동이 크게 있는 편이라 Best 데이터를 가져와 사용하기로 하였다.
- --> Best에 따라 연봉 찾기 진행중, 생각외로 연봉이 정말 찾기 힘들어 1. Best에 해당되는 데이터 2. 연봉이 있는 년도의 데이터로 우선순위를 정해 데이터 수집
- 1985년을 중심으로 해당 년도와 되도록 가까운 년도로 데이터를 수집하려 하였다
- 1980년대 연봉정보가 드문드문 있어서 년도의 표시가 의미없을것 같아 년도 표시는 생략
- 소속된 팀에 따라서 연봉 차이도 있는 것처럼 보인다.
- 야구는 관심없던 분야라 전혀 모르겠지만 일단 컬럼 하나하나 검색해서 의미있어보이는 컬럼만 가져와 사용하였다.(주관적 판단)
📝 과제 진행과정
데이터 수집 -> info() 확인 -> 필요로 하는 컬럼만 남기고 DataFrame 생성 -> int형 데이터 float형으로 변환 -> 1980년도와 2010년도 컬럼 맞춰주기
팀 feature를 어떻게 처리해야 할까?
선형회귀를 위해 라벨 인코딩보다는 one-hot-encoing을 사용, 트리계열에서는 상관없다
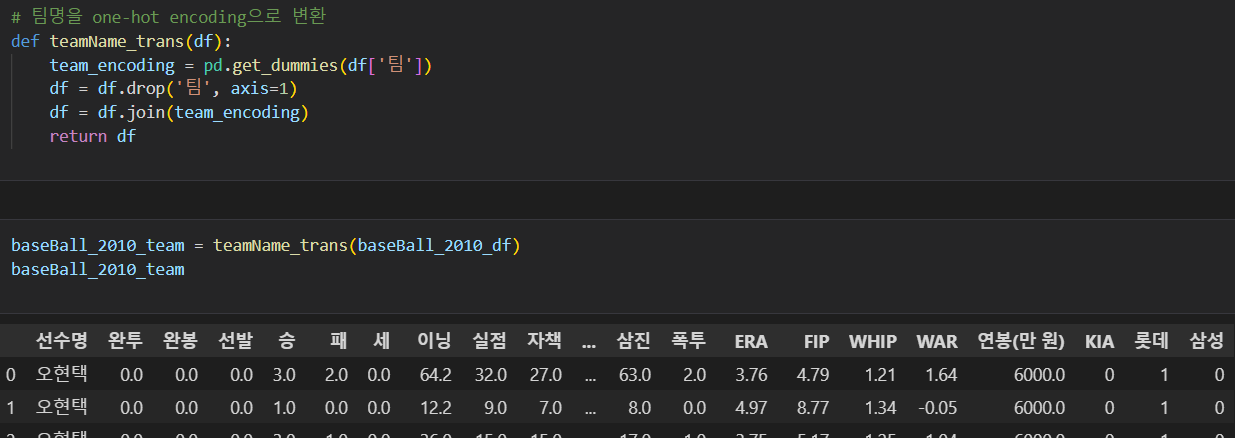

- 아무래도 팀 컬럼이 다른것이 신경쓰인다
OSL로 팀 feature가 중요한 것인지 알아보자
- KIA, 롯데, 삼성의 회귀 계수가 -3.63e+04, -3.448e+04, -2.835e+04 로 유의미해 보이지 않는다.
- --> 팀 컬럼 제거하자!!

데이터 다루기 전에 먼저 경향을 확인해보자
-
컬럼별 boxplot
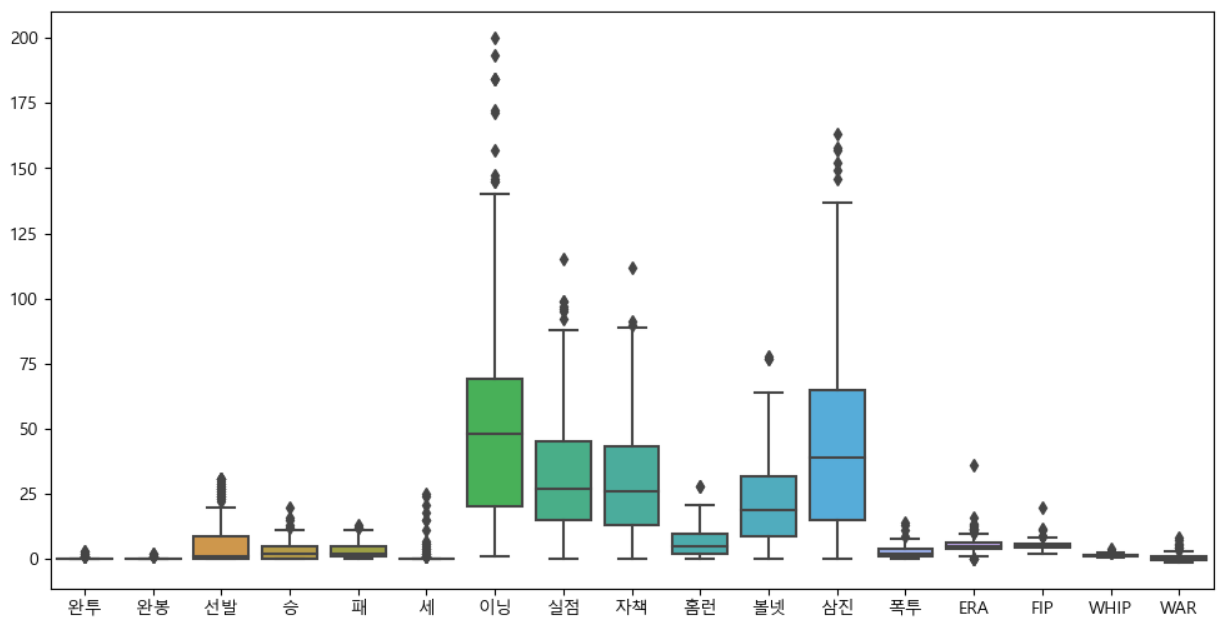
-
연봉 boxplot, 히스토그램
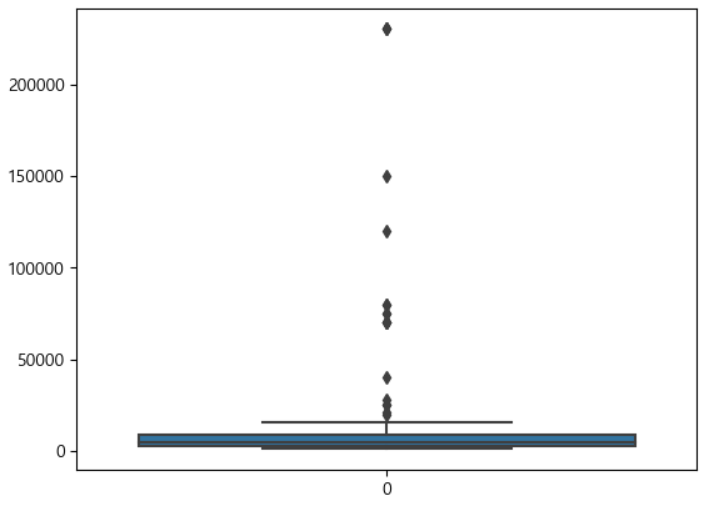
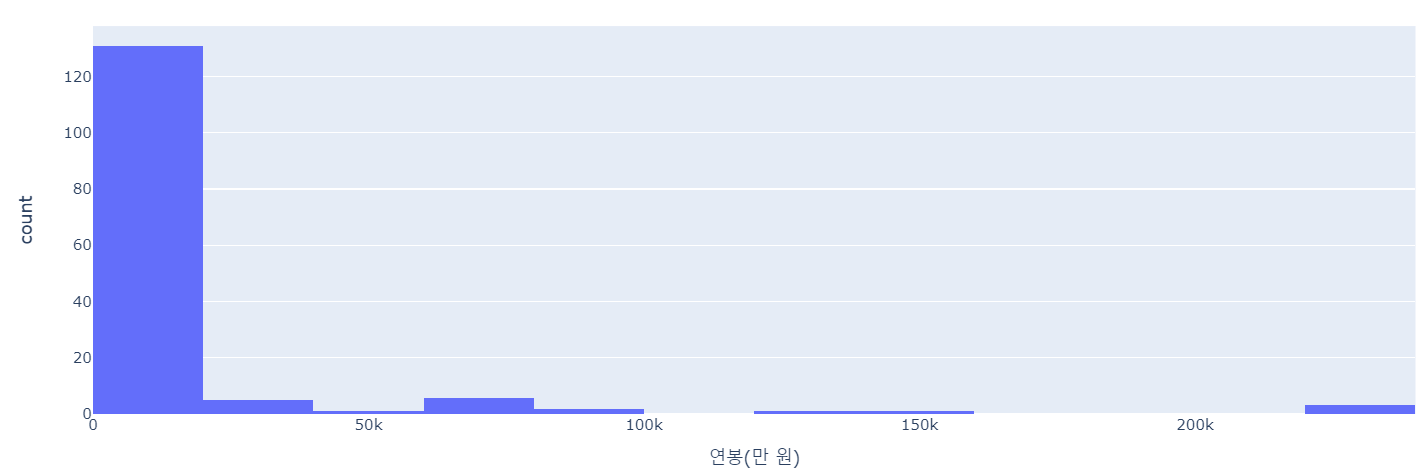
- 이상치값이 많이 보인다
- --> 이상치의 영향을 최소로 받는 RobustScaler 적용을 해보자
train, test data 나누기
2010년도 선형회귀분석
- Pipeline을 사용해 RobustScaler와 LinearRegression 적용
모델평가
RMSE of Train Data : 25456.699763097145
RMSE of Test Data : 28756.447532185804
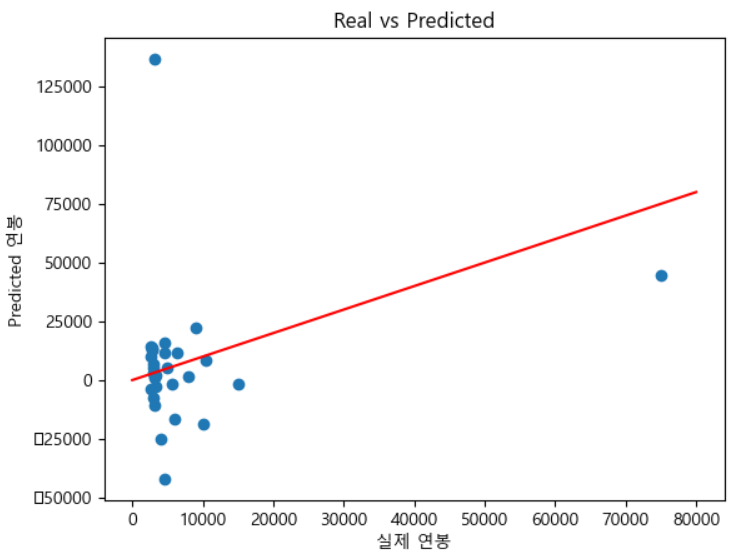 - 잘 맞지 않는다.
- 잘 맞지 않는다.
corr() 변수들의 상관관계 살펴보기
1980년대를 2010년대 데이터와 매핑
- 문제는 "최동원 선수가 현역 선수라면 연봉이 얼마일까"이므로 최동원 선수의 능력치는 그대로여야 할 것이다.
- --> 최동원선수가 그 당시에 얼마나 유능한 선수였더라도 현역과 비교해서 능력이 떨어지면 연봉도 하락할 것이기 때문
- 만약 명성에 따른 연봉이었다면 그 당시 선수들&현역선수들의 능력치 평준화 비교가 들어갔었겠지만
- 능력치를 그대로 설정했다면 달라질 것은 연봉 뿐이다.
- 따라서 그대로 선형회귀를 돌려도 될 것 같다.
- 물가상승을 고려해 연봉 계산을 해보니 1985년 -> 2018년 : 8100 -> 27159.3 (만 원)
- 물가상승 배수 : 3.353
- 참고: CPI 소비자 물가지수
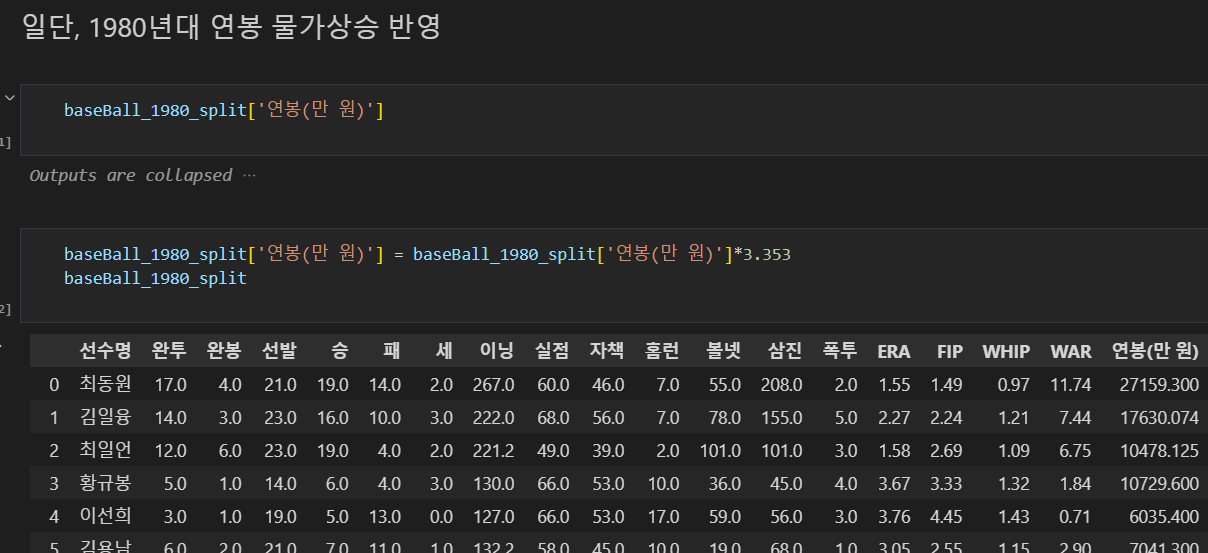 - 이제 이 1980 데이터셋은 test용으로 남겨두고, 2010 데이터셋으로 다시 되돌아가 보자
- 이제 이 1980 데이터셋은 test용으로 남겨두고, 2010 데이터셋으로 다시 되돌아가 보자
2010년도 회귀분석에서 다중공선성 확인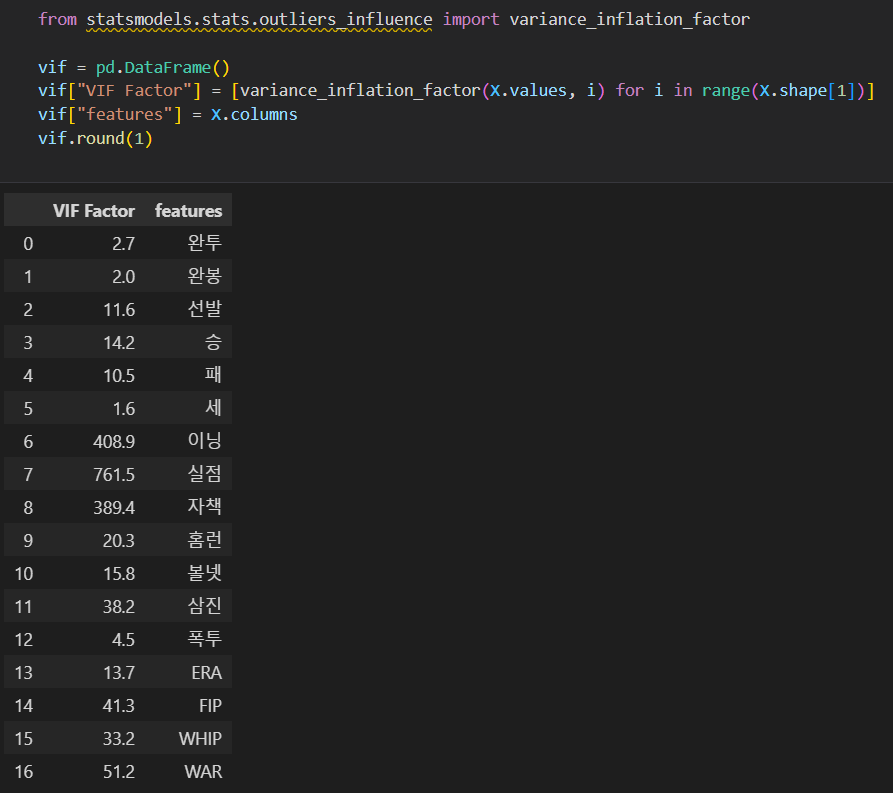
- VIF가 높은 ['이닝', '실점', '자책'] 제거
다시 train, test 데이터 나누기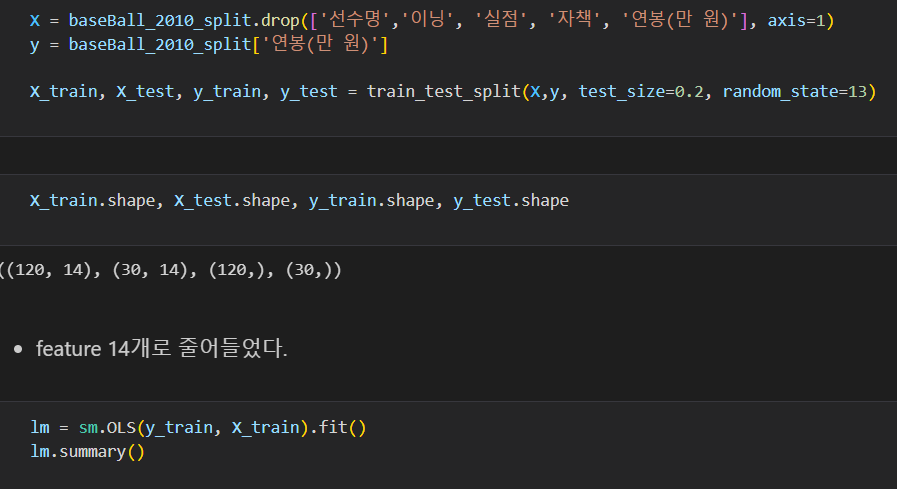
- feature 14개로 줄어들었고 OLS도 다시 확인
다시 회귀모형 fit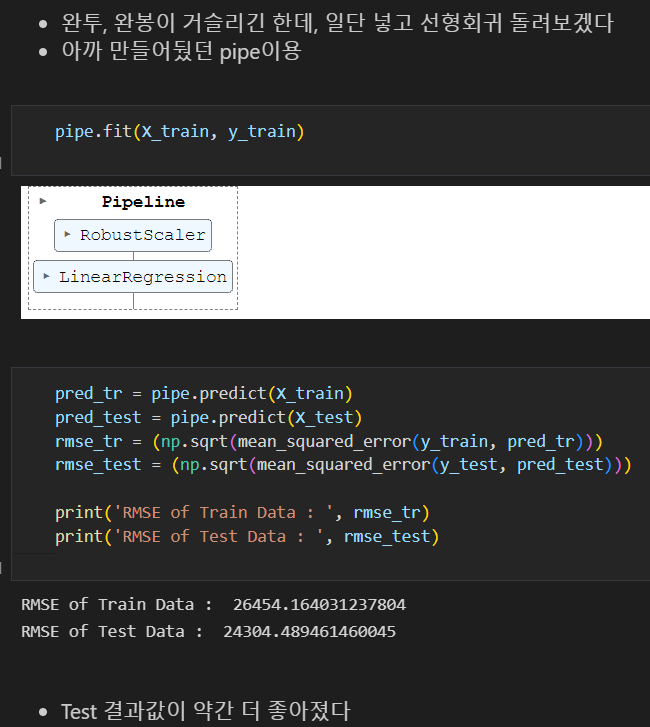
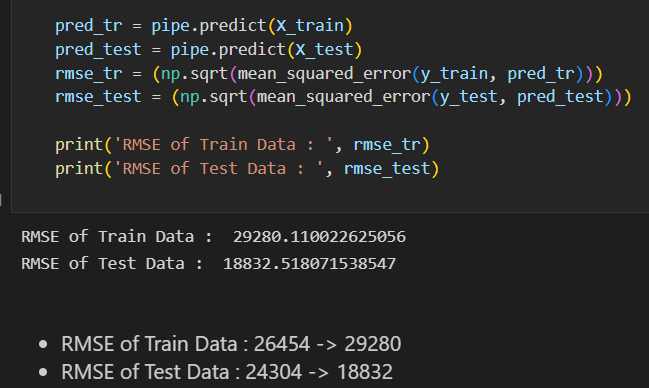
이번에는 coef와 P>|t| 참고하여 컬럼을 선택하고 다시 회귀모형 fit
현역 최동원 선수의 연봉은?
- 일단 다중공선성 확인 후의, Train과 Test의 RMSE값 차가 더 적었던 첫 번째 fit데이터를 사용
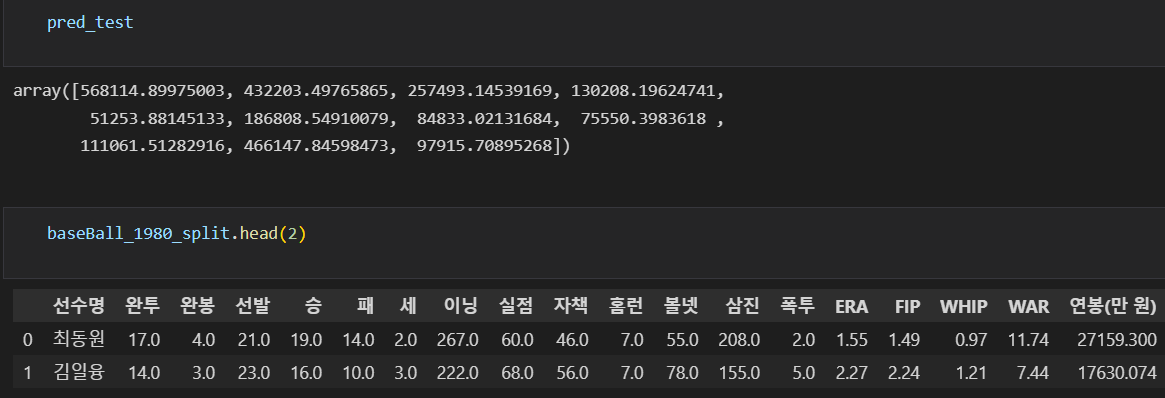
물가상승률만 반영했을때의 최동원 선수의 연봉은 27159.3(만 원) 이었으나,
선형회귀 결과 최동원 선수의 연봉은 568114.8(만 원)으로 나왔다.
결과값이 너무 크다. 물가상승률 대신 다른 값을 곱해보자
- 그러고보니 데이터를 수집하면서 2010 초봉은 대략 2700~2800인 특징을 확인했다.
- 앞선 히스토그램의 결과 역시 왼쪽에 연봉 count들이 몰려있었다
- 따라서 1980의 연봉 최소값을 2700~2800으로 바꾸어 설정해 보자!
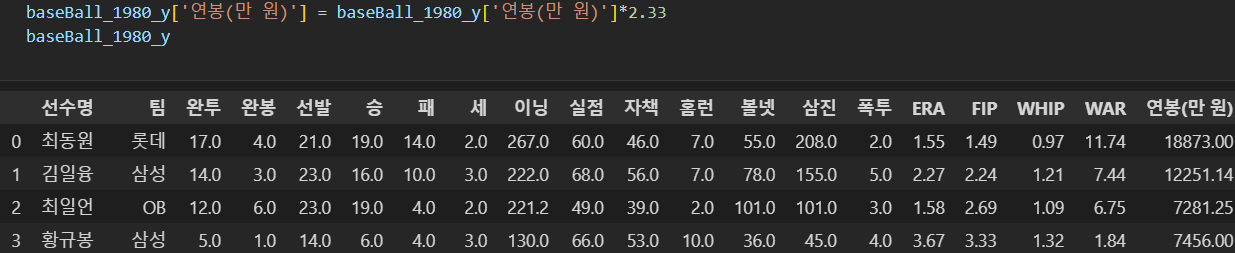
- 1200.0 * 2.33 = 약 2800
- --> 2.33배 적용하자
이번에는 데이터 합친후 데이터 나누기
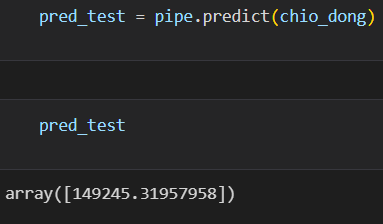
결과
- 최동원 선수 설정 연봉 : 18873(만 원)
- 선형회귀 predict 결과 연봉 : 149245(만 원)
결론
최동원 선수의 현역일 경우 연봉은 149245(만 원) 이다.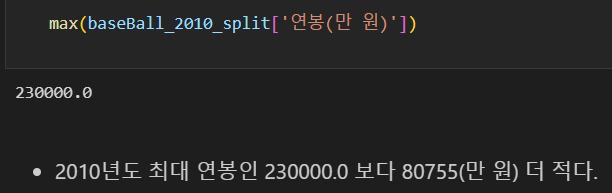
📝 후기
첫 머신러닝 과제라 그런지 이틀의 시간이 소요되었다.
배운 내용을 찾고 정리하고 주관적 판단이 들어가고 배우지 않았던 부분도 구글 검색을 통해 스스로 학습하는 시간을 가졌다.
최대한 컬럼에 대한 이해도를 높이고 회귀분석의 절차를 수학적으로 따라가려고 노력했다. 결괏값이 이상하다고 느껴지거나 납득이 되지 않으면 다시 윗 단계로 돌아가 작업하는 과정을 거쳤다. 위 코드는 내가 짠 코드의 전체가 아닌 일부분이며 전체를 작성하고 나서 나름대로 머신러닝의 흐름을 잡을 수 있는 기회가 되었다고 생각한다. 앞으로 있을 머신러닝, 딥러닝 프로젝트를 위해 꾸준한 공부를 다짐한다. 모두 수고하셨습니다~
