머신러닝
1.머신러닝 Scikit Learn

:Scikit-learn : 다양한 분류, 회귀, 그리고 서포트 벡터 머신, 랜덤 포레스트, 그라디언트 부스팅, k-평균, DBSCAN을 포함한 클러스터링 알고리즘
2022년 11월 28일
2.머신러닝 모델링 과정중 random_state의 의미
호출할 때마다 동일한 학습/테스트용 데이터 세트를 생성하기 위해 주어지는 난수. 어떤 값을 넣든 상관없다.
2022년 11월 28일
3.머신러닝 Accuracy까지의 과정
총 6단계
2022년 11월 29일
4.Hisplot - seaborn 데이터 시각화
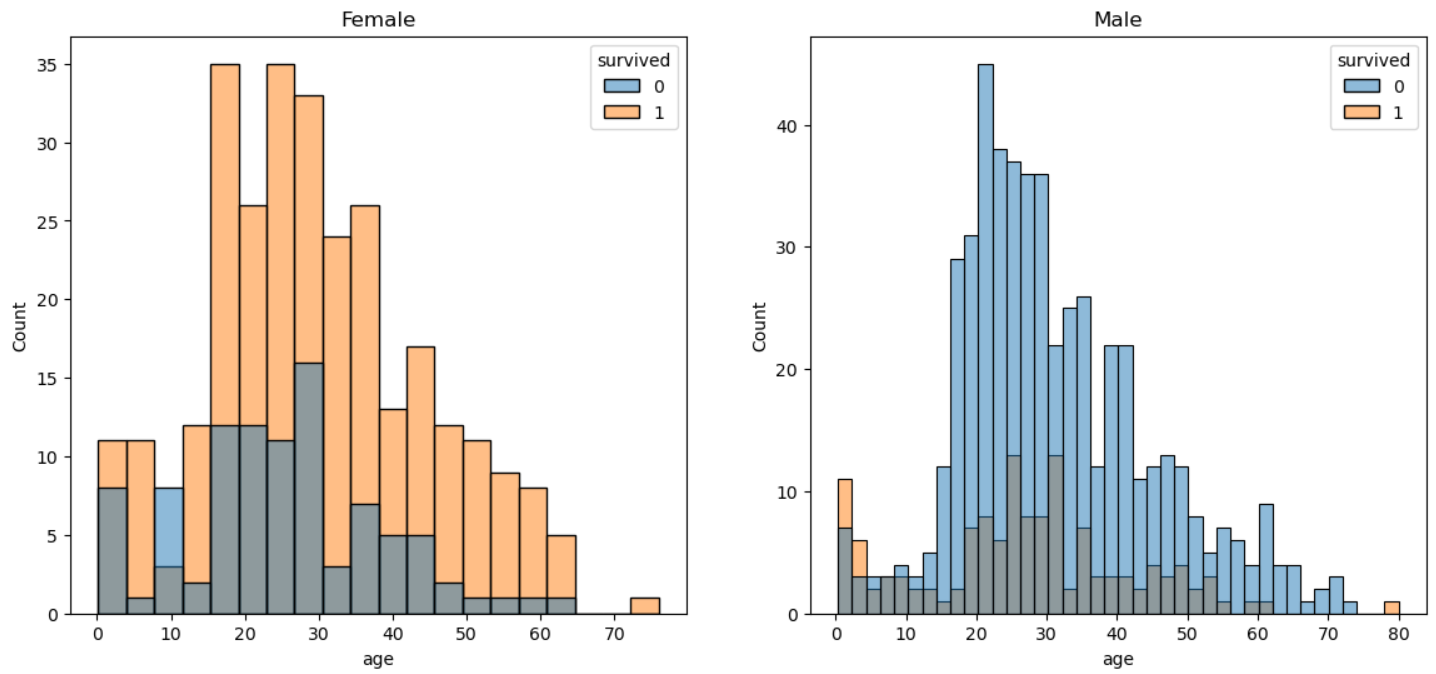
머신러닝2 EDA3 📝 강의안에서 사용한 distplot이 'distplot' is a deprecated function and will be removed in a future version.으로 떠서 hisplot을 이용해 시각화를 해 보았다.
2022년 11월 30일
5.모델 평가 RMS
MAE (Mean Absolute Error), MSE (Mean Squared Error), RMSE,,
2022년 12월 6일
6.로지스틱 회귀 slover
slover-='liblineaer'
2022년 12월 7일
7.Dataset에서 0값이 있을 때
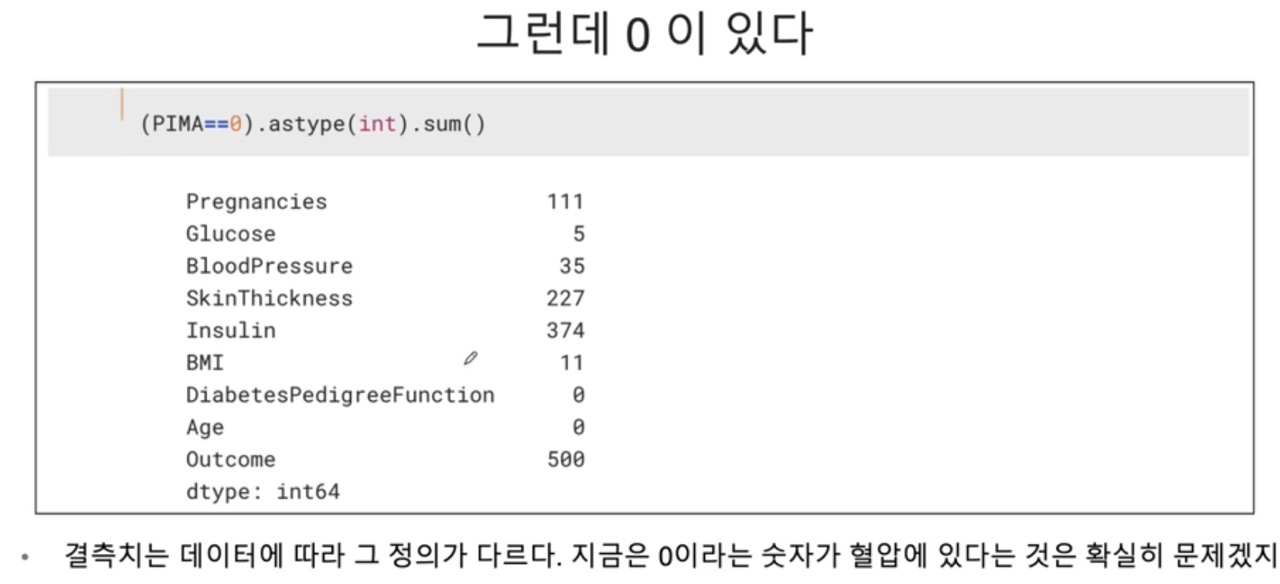
PIMA 인디언 당뇨병 예측 중..
2022년 12월 7일
8.데이터 전처리
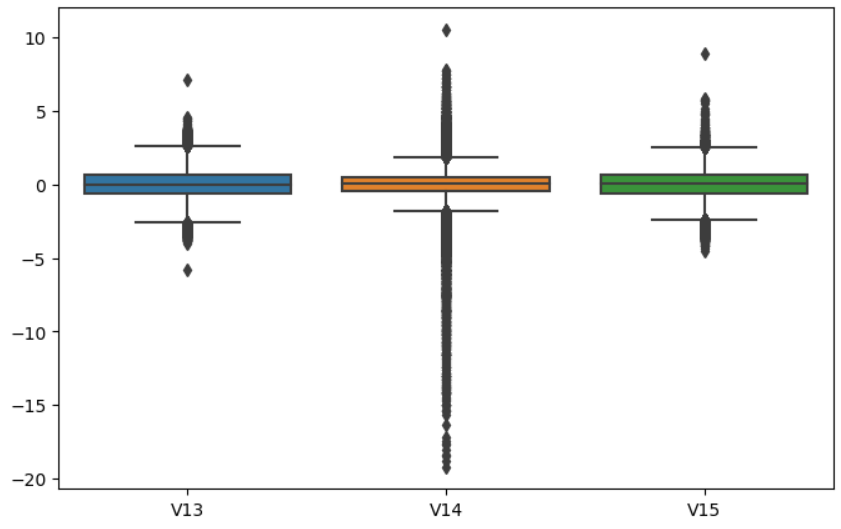
MinMaxScaler(0,1), StandardScaler(평균0, 분산1), RobustScaler(사분위수) 4. feature 선택 추출 및 가공
2022년 12월 13일
9.자연어처리 install
강의안대로 진행이 되지 않아 따로 공부하여 기록하였다.
2022년 12월 13일
10.스터디 노트
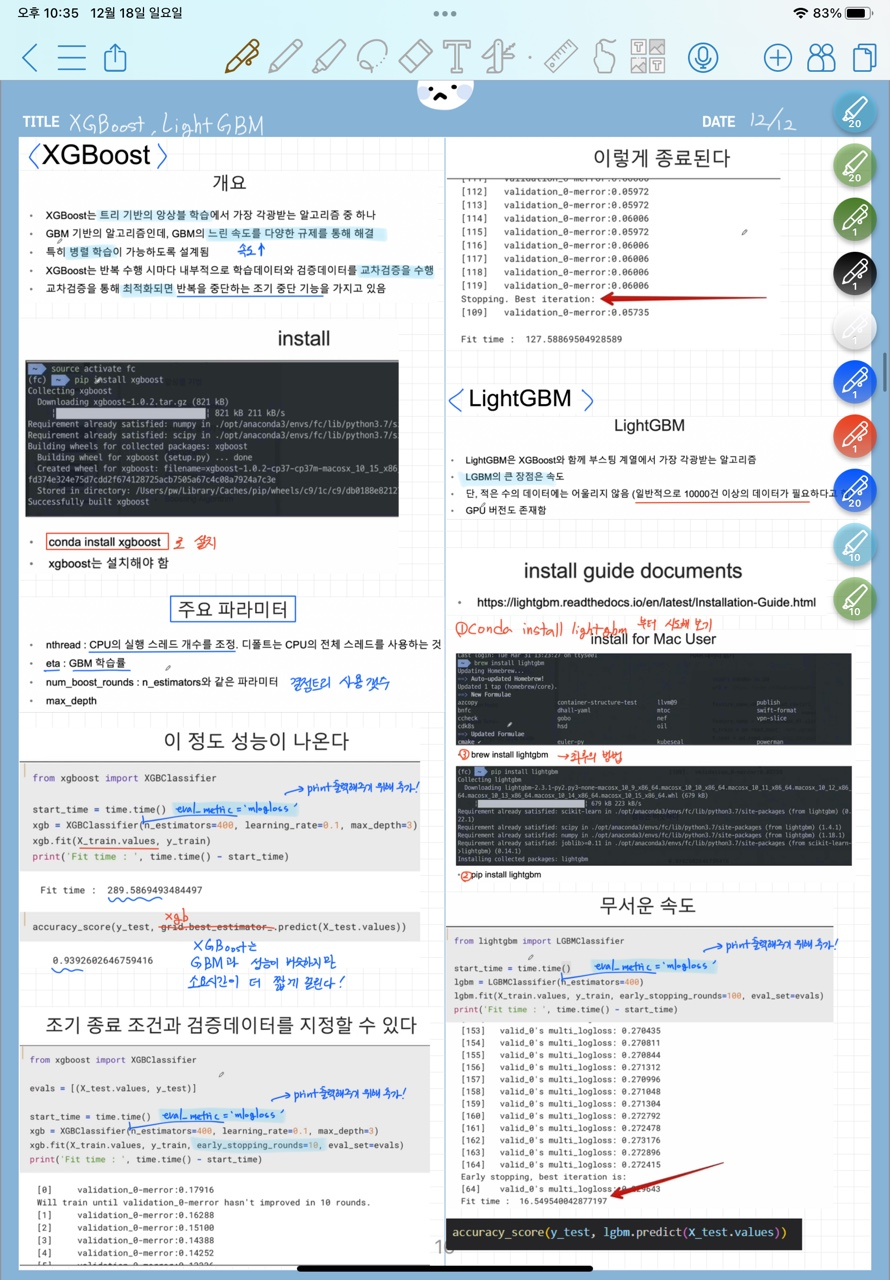
이번주는 강의와 코테와 과제 제출로 너무 바빠서 따로 스터디 노트를 정리할 여유가 없었다.대신 아이패드에 따로 정리해 두었던 공부 기록들의 일부를 올려보겠다.
2022년 12월 18일
11.predict를 위해 값 집어넣는 방법

np.array형식으로 집어넣는다!!
2022년 12월 19일
12.seaborn regplot
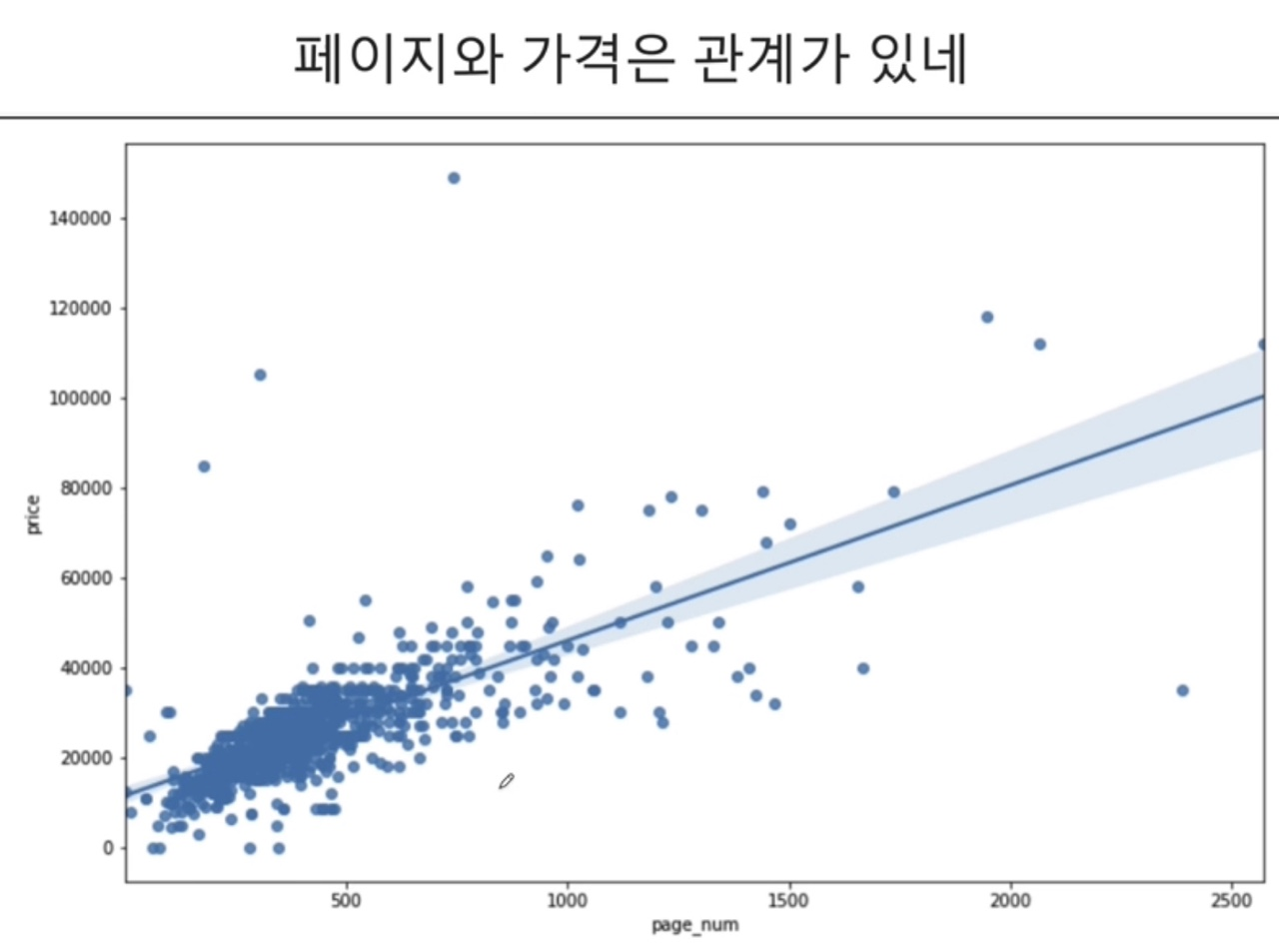
🔎 x와 y의 선형관계 파악, sns.regplot
2022년 12월 21일
13.X, y 각 하나의 변수만 가지고 reg회귀모델 만들 때

X_train.reshape(-1,1)
2022년 12월 21일
14.머신러닝 과제2 풀이
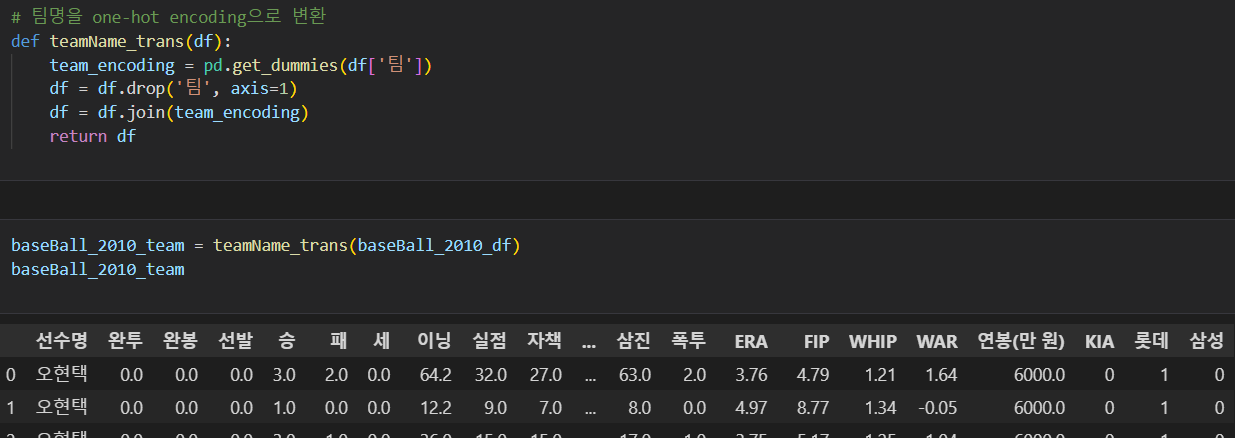
🔎 야구선수 최동원 연봉 예측 과제
2022년 12월 25일