파일을 업로드 하다가 아쉬운 점이 있었습니다. 업로드가 잘 되어도, 복제가 실패하면 결국에 실패한다는 것 입니다. 그래서 의문이 들었습니다.
“원본엔 잘 저장됐는데, 복제가 실패했다고 사용자한테 실패를 돌리는 게 맞나?”
거기다 복제가 끝날 때까지 응답을 무작정 기다리게 하는 것도 조금 찜찜했습니다.
이번 글에서는 기존 업로드 흐름의 문제점을 짚어보고, 속도와 실패율을 줄이는 것을 목표로 개선해나가는 과정을 담았습니다.
1. 기존 방식의 흐름과 문제점
1.1 기존 방식의 작동 흐름
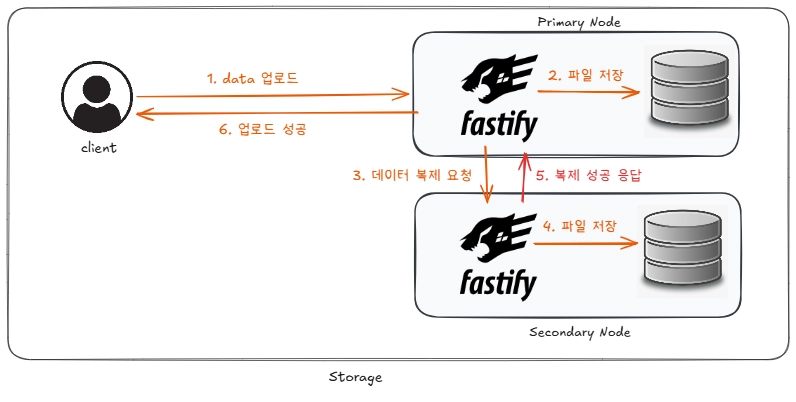
현재 파일을 업로드하는 전반적인 흐름은 위와 같습니다.
1. 사용자는 URL로 파일을 업로드한다.
2. Primary Node에서 요청을 받아 DISK에 파일을 저장한다.
3. Secondary Node 에게 복제를 요청한다
4. Secondary Node 가 이를 받아 DISK에 파일을 저장한다
5. 복제 성공 응답을 Primary Node에게 전달한다
6. Primary Node가 이를 받아 Client 에게 성공 응답을 전달한다즉, 2개의 DISK 모두 저장이 완료되었을 때에만 성공 응답을 반환하게 됩니다.
export async function uploadFileWithConcurrentReplication(
request: FastifyRequest<{ Querystring: PresignedQuery }>,
replicationQueue: ReplicationQueueRepository,
): Promise<FileInfo> {
const { bucket, objectKey } = request.query;
const bodyStream = request.body;
request.log.info({ objectKey }, "PUT request received");
// 유효성 검사
validatePresignedUrlRequest(request.query, "PUT");
validateReplicationBodyStream(bodyStream);
// stream 분기 처리
const storageStream = new PassThrough();
const replicationStream = new PassThrough();
bodyStream.pipe(storageStream);
bodyStream.pipe(replicationStream);
// 복제 요청
const replicationPromise = replicateToSecondary(
bucket,
objectKey,
replicationStream,
replicationQueue,
request.log,
);
// DISK 쓰기
const filePath = await saveStreamToStorage(bucket, objectKey, storageStream);
const fileInfo = await collectStreamFileInfo(
bucket,
objectKey,
filePath,
mimetype,
);
// 복제 완료 대기
await replicationPromise;
request.log.info({ fileInfo }, "파일 업로드 성공");
return fileInfo;
}위 코드는 두 저장 작업을 모두 완료한 후에만 성공 응답을 반환하도록 설계하였습니다. 이는 Primary와 Secondary 2개의 DISK에 파일을 모두 저장하여 안정성을 보장하려는 의도였습니다.
1.2 현재 로직 개선 포인트 분석
1.2.1 분석 1: 응답 시점에 따른 소요시간 개선 포인트
현재 처리 방식을 시간 그래프로 나타내면 아래 그림과 같습니다.
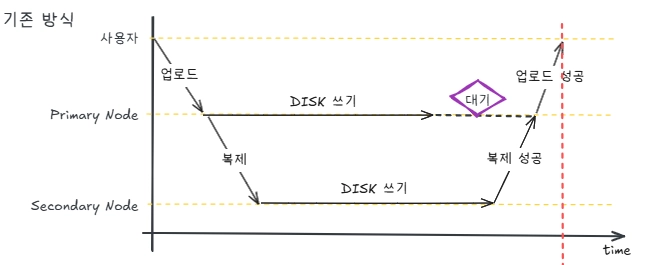
2개의 DISK에 모두 쓰기가 완료되는 시점에 성공 응답이 반환됩니다. 비동기적으로 쓰기 처리를 하지만, 복제가 완료될 때까지 대기 해야한다는 문제가 있습니다.
이러한 대기 시간을 줄인다면, 사용자가 받을 응답 속도를 더 높일 수 있을 것 같습니다.
1.2.2 분석 2: 복제 실패 시, 재업로드 개선 포인트
현재 2개의 DISK에 저장하게 되는데, 흐름 상 저장이 실패할 수 있는 지점은 2가지입니다.
- Primary Node에 저장 실패 (원본)
- Secondardy Node에 저장 실패 (복제본)
데이터가 원본에 저장되지 않았다면 실패 응답을 받는 것이 납득이 됩니다. 아예 저장되지 않았으니 사용자는 다시 업로드를 해야하기 때문입니다.
하지만 원본에 데이터가 잘 저장되었는데, 사용자가 실패로 처리해야하는 부분에 아쉬움을 느꼈습니다.
‘원본은 잘 저장되었으니, 원본을 복제해서 다시 시도하면 되는거 아니야?'
'굳이 사용자 불편하게 처음부터 업로드를 시켜야해?’
이러한 문제를 서버에 저장되어있는 ‘원본’을 이용하여 해결하고 싶다는 생각이 들었습니다.
1.3 결론
결론적으로 현재 문제와 해결하고싶은 사항을 요약하자면 다음과 같습니다.
- 복제 대기시간을 줄여, 사용자가 받는 응답 속도 향상시키기
- 복제만 실패할 경우, 사용자가 재업로드를 해야하는 불편함 개선하기
2. 해결 방안
2.1 방안 1: 즉각 retry

가장 무난하게 떠올릴 수 있었던 방법은 복제 요청이 실패했을 경우, 즉각적으로 복제 요청을 시도하는 방식입니다. 구현이 간단하여 쉽게 도입할 수 있다는 장점이 있습니다.
하지만 2가지 우려사항이 있습니다.
- N번 재시도 후 모두 실패하면 그 이후에는 재시도를 하지 않는다는 점 : 즉, 데이터가 Secondary에 저장되지 않은 상태로 남겨질 수 있어 완전한 복제 보장이 불가능합니다.
- 사용자가 받을 응답 시간이 느려짐 : 복제를 재시도하는 동안 사용자는 응답을 하염없이 기다려야합니다.
따라서 현재 문제의 해결책으로는 부족하다고 판단했습니다.
2.2 방안 2: 업로드와 복제 처리 분리하기
업로드와 복제 처리를 분리하기
현재 업로드의 문제점은 복제 요청이 업로드 요청에 포함되어있기 때문에 발생한 것입니다. 따라서 복제가 실패하면 업로드 요청도 실패하고, 복제가 완료되지 않으면 업로드 요청도 완료되지 않습니다. 그래서 업로드와 복제를 분리해서 처리하는 방법을 생각했습니다.
사용자가 업로드 요청을 보내면, 복제 요청 정보를 별도로 저장하는 것 까지 처리하고, 복제처리는 업로드 요청과 별도로 처리하는 것입니다.
이렇게 된다면, 복제 성공/실패 여부에 상관없이, 원본이 저장된다면 사용자는 성공 응답을 받을 수 있습니다.
응답 시간 개선
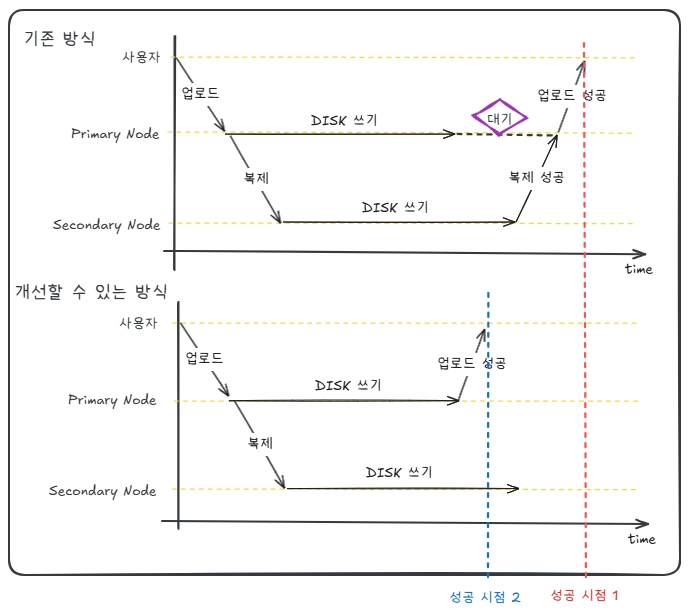
기존에는 복제가 끝날 때까지 응답을 대기시켜뒀는데, 이 방식에서는 복제를 기다리지 않고 바로 성공 응답을 반환하여, 사용자의 응답속도도 향상시킬 수 있습니다.
복제가 실패하는 경우에는?
위 방식에서는 복제가 실패하는 경우, 사용자는 다시 업로드를 하지 않습니다. 따라서 완전한 복제를 보장하기 위한 방법이 필요합니다.
이를 위해 복제 정보를 저장하여, 만약 복제가 실패하더라도 언제든 다시 시도할 수 있게 만들어 보장할 수 있습니다. 그렇게되면 언젠가는 반드시 복제가 완료되고, 복제 실패로 인한 데이터 유실을 방지할 수 있습니다.
결과적으로 앞서 언급했던 두 가지 문제, 복제 실패 보장과 응답 속도 개선을 동시에 해결할 수 있는 방법입니다.
3. 복제 정보를 통한 복제 요청 구조 설계하기
이를 위해 다음 조건이 필요합니다.
- 복제 요청 정보들을 별도로 저장해야한다
- 주기적으로 복제를 호출할 수 있어야 한다
3.1 처리 흐름
그림으로 표현하면 다음 처리 흐름을 갖겠습니다.
복제 요청 - 초기 시도
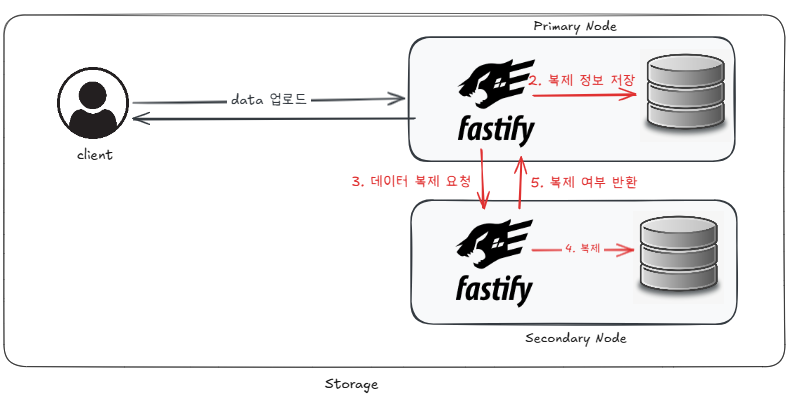
처리 흐름
1. Primary Node가 복제 실패 응답을 받는다
2. 실패한 요청에 대한 정보를 별도로 저장한다
3. 이후 Secondary Node 서버에 복제를 다시 요청한다복제 요청 - 실패 시 처리
만약 복제가 실패하더라도, 다음 방식으로 반복하여 복제 시도가 가능합니다.
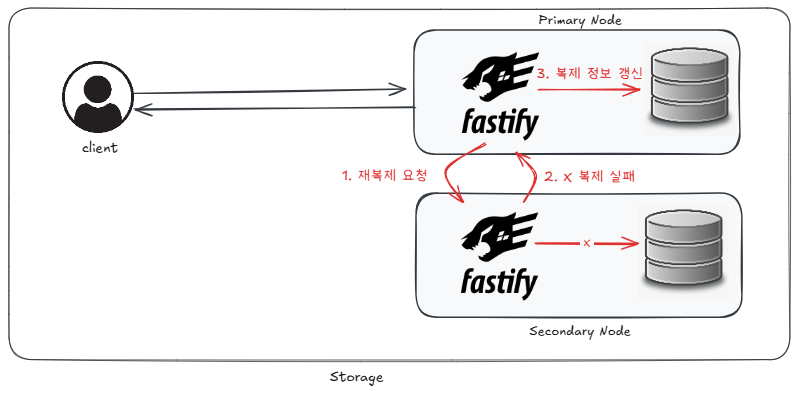
1. 복제 요청 정보를 통해 재복제 요청을 전달한다.
2. 재복제 실패
3. 실패한 복제 요청에 대해 정보를 갱신한다3.2 복제 요청 정보 저장
재복제 요청을 다시 전송하기 위해 필요한 데이터들을 저장해야합니다.
3.2.1 DISK에 저장하기
이를 DISK에 저장할지, Memory에 저장할지 고민했습니다. 메모리의 경우 서버가 종료되면 같이 종료되기에, 안정성에 문제가 있다고 판단하여, 확실한 복제 보장을 위해 DISK에 저장하기로 하였습니다.
3.2.2 저장 방식 선택하기 - SQLite
다음으로 JSON과 같은 파일로 저장할지, DB를 사용하여 저장할지를 고민하였습니다.
JSON으로 저장한다면 간단히 구현할 수 있다는 장점이 있지만, 동시성 충돌을 제어하기가 어렵다고 판단했습니다. 해당 로컬에서만 사용하는 정보이므로, embedded DB를 사용하려고 했습니다.
주기적으로 재복제를 호출해야하므로, 시간 정보 또한 담을 필요가 있는데, RocksDB의 경우에는 시간순 조회 및 값 갱신에 적합하지 않다고 판단하여 sqlite을 선택하였습니다.
3.2.3 저장 필드
- bucket, objectKey : 식별하는데 필요한 값 (파일 이름)
- retryCount : 복제 요청 시도 횟수
- nextRetryAt : 다음 복제를 시도할 시간
- status : 재시도 여부 상태
- 이 밖의 로그 및 에러 확인 용도의 필드
위 내용들을 바탕으로 초기 요청 실패 시, sqlite를 사용하여 데이터를 저장하는 코드를 구현하였습니다.
export async function uploadFile(
request: FastifyRequest<{ Querystring: PresignedQuery }>,
replicationQueue: ReplicationQueueRepository,
): Promise<FileInfo> {
const { bucket, objectKey } = request.query;
const bodyStream = request.body;
request.log.info({ objectKey }, "PUT request received");
validatePresignedUrlRequest(request.query, "PUT");
validateReplicationBodyStream(bodyStream);
const filePath = await saveStreamToStorage(bucket, objectKey, bodyStream);
const fileInfo = await collectStreamFileInfo(
bucket,
objectKey,
filePath,
mimetype,
);
request.log.info({ fileInfo }, "[FileUPload] 파일 업로드 성공");
// 복제할 정보를 저장하기
return fileInfo;
}복제 정보를 SQLite에, 원본을 DISK에 성공적으로 저장하면, 사용자에게 성공 응답을 반환합니다.
Primary에 파일이 저장된 상태이므로, Secondary 복제는 서버가 자동으로 보장하는 방식입니다. 다만 재복제가 완료되기 전까지는 Primary 장애 시 데이터가 유실될 수 있다는 위험은 남아있습니다.
3.3 주기적으로 재요청을 보내는 방법
한번에 재복제 요청이 몰리게 되면, secondary Node 서버에 무리가 갈 수 있습니다. 따라서 한번에 BATCH_SIZE 만큼만 재복제 요청을 전달합니다. BATCH_SIZE는 10로 설정하였습니다.
또한 각 실패한 복제 요청 처리의 주기를 10*2^시도횟수 로 설정하고, 최대 대기 시간을 1시간+a으로 설정하였습니다. 요청이 몰렸을 때, 겹치지 않게 하기 위해서 서로 다른 주기로 설정 하였습니다.
만약 Secondary Node가 장시간 복구되지 않는 경우에는 재복제 요청이 무한히 반복할 수 있습니다. 따라서 최대 시도 횟수(retryCount)를 두어 재시도의 제한을 두도록 처리했습니다. 최대 시도 횟수는 15로 설정하였습니다.
async function tryReplications(
replicationQueue: ReplicationQueueRepository,
log: FastifyBaseLogger,
): Promise<void> {
// secondary node health 체크
const idle = await isSecondaryNodeIdle(log);
if (!idle) return;
// 복제 정보 가져오기
const replicationObjects = replicationQueue.fetchRetryBatch(BATCH_SIZE);
// 가져온 정보를 바탕으로 복제 시도
for (const row of replicationObjects) {
const { bucket, objectKey } = row;
try {
await replicateToSecondary(bucket, objectKey, log);
} catch (err) {
// 재복제 실패 시, 다시 등록
replicationQueue.updateOnRetryFailure(
bucket,
objectKey,
errorType,
errorMessage,
);
// 로그
continue;
}
// 복제 성공 시, 복제 정보 삭제
replicationQueue.deleteOnSuccess(bucket, objectKey);
}
}일정 주기마다 위의 retryFailedReplications 함수를 호출하여, 데이터 복제 로직을 실행합니다.
3.4 적용 결과
초기 업로드 시
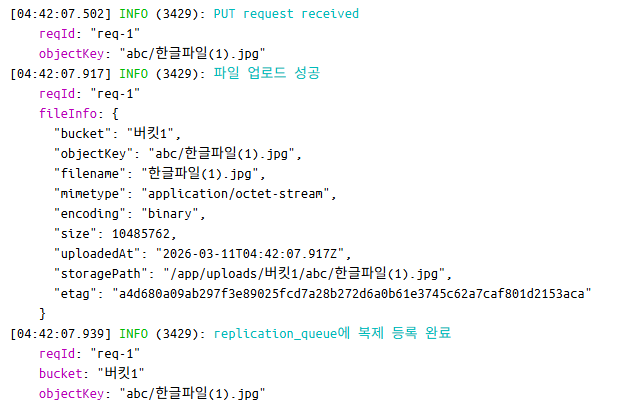

주기적으로 호출하는 retryWorker에서 복제를 처리합니다
복제 실패 시

복제가 실패했을 때, 주기적으로 재복제 로직이 자동으로 실행되도록 하였습니다.
서버가 꺼졌다 켜지는 경우
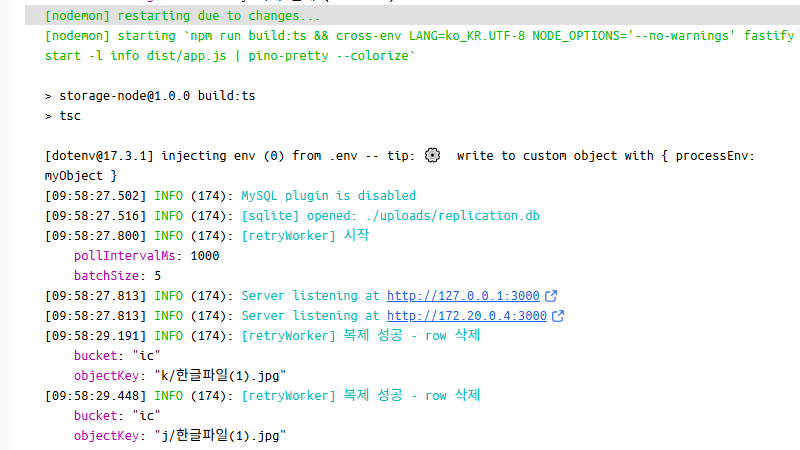
실패 정보를 메모리가 아닌 DISK의 SQLite에 저장했기 때문에, 서버가 꺼졌다 켜지는 경우에도 동일하게 재복제 로직이 실행됩니다.
5. 결과 비교
5.1 속도 비교
20개의 5MB 파일 업로드를 기준으로 속도를 측정해봤을 때, 소요되는 시간입니다. (로컬 I/O속도 100MB/s 이상 환경에서 실시하였기 때문에 DISK 병목은 없습니다)
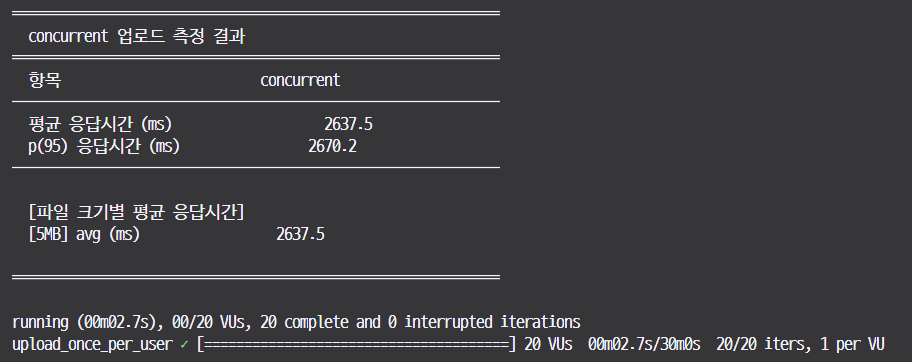
- 기존 방식 : 모두 저장 후 응답을 하는 경우, p(95) = 2670.2 ms 가 소요됩니다.
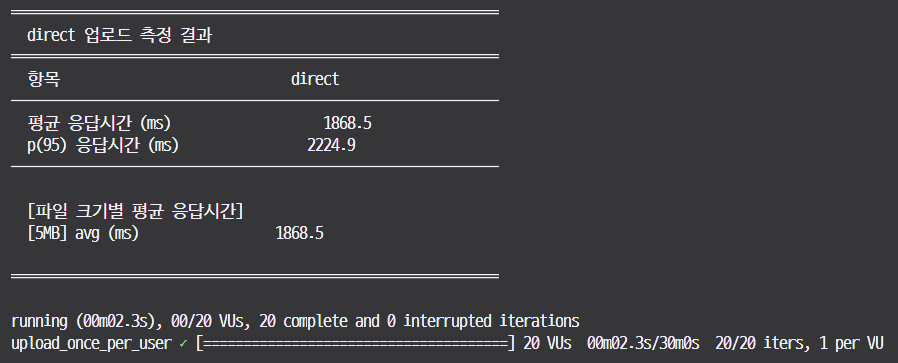
- 개선 방식 : 즉시 응답을 하는 경우, p(95) = 2224.9 ms
20개 파일 기준으로 0.4s 를 개선하였습니다.
6. 보완해야할 점
이렇게 로그를 통한 재시도 로직을 구현하였습니다. 사용자의 응답 속도는 높아졌지만, 도입으로 인한 2가지 우려사항이 생겼습니다.
문제점 1 - 데이터 동기화
만약 복제 처리가 되지 않았는데, 파일 읽기요청이 secondary 서버로 들어온다면 제대로된 파일을 반환할 수 없을 것입니다. 이를 막으려면 primary 서버로만 읽기 요청을 전달하거나, 복제 완료 여부를 확인할 수 있는 API를 별도로 두어야할 것 같습니다. (현재는 모든 요청을 primary에 전달하는 구조라 상관이 없지만, 로드밸런싱을 시키게 된다면 개선할 필요가 있을 것 같습니다)
사용자 응답 속도는 개선했지만, 추가적인 문제가 발생하여서 이러한 부분도 추후 구현 시 고려하여야 할 것 같습니다.
문제점 2 - 서버 부하
secondary 서버에 부하가 발생했는데, 계속해서 재시도 로직이 동작한다면, secondary 서버에 문제가 발생할 수 있을 것 같습니다.
이러한 부하를 막기 위해서, 서로 다른 주기로 요청이 전송되도록 설정했고, 한번에 10개의 복제로직만 수행되도록 만들었습니다. 하지만 이런 로직들은 예방의 측면이 강할 뿐이지, 트래픽이 몰렸을 때를 회피하기엔 부족하다고 생각합니다. 추후에 이 부분을 개선해볼 필요성이 있을 것 같습니다
