1. 개요
1.1 이 글의 목적
이 글은 Secondary Node 복제 재시도 로직 개선 시리즈의 2편입니다. 1편에서는 복제 실패 시 사용자에게 재업로드를 요구하던 기존 방식의 문제를 살펴보고, 실패 로그를 SQLite에 저장하여 주기적으로 재복제를 시도하는 방식을 도입하는 과정을 다뤘습니다.
하지만 1편에서 해결하지 못한 ‘트래픽이 몰리는 시점에 재복제 로직을 보낼 수 있다는 문제’가 남아있습니다.
이를 해결하기 위해 재복제 요청을 보내기 전에 Secondary Node의 현재 작업량을 확인하고, 여유로울 때만 재복제 요청을 전송하는 방식을 도입하였습니다.
이번 글에서는 그 설계와 구현 과정을 담았습니다.
먼저 트래픽을 확인할 수 있는 여러 지표들을 알아보고, Node js에서 작업 큐로 작업의 수를 만드는 과정에서 직면한 한계를 작성하였습니다. 이후 Stream 수를 기반으로 작업량을 판단하는 방식을 도입하였습니다. 마지막으로는 부하 테스트를 통해 적정 트래픽 기준을 설정하는 과정을 작성하였습니다.
2. 서버 트래픽 확인하기
2.1 서버 트래픽 확인 종류
서버의 트래픽을 어떤 값으로 판단할지 고민해보았습니다.
- DISK 사용량 : 복제 요청은 DISK 쓰기 작업입니다. 따라서 DISK 사용량을 바탕으로 트래픽을 판단할 수 있습니다.
- 최근 N 초간 요청 수 : 최근 N시간 동안 서버가 받은 요청 수를 기준으로 판단하는 방법입니다.
- 작업큐 :
secondary Node에 얼마나 많은 요청 작업들이 작업 중 인지를 바탕으로 확인하는 방법이 있습니다.
2.2 DISK 사용량
DISK 사용량을 바탕으로 트래픽을 확인하는 방법은 구현이 간단합니다. OS 자체에서 지원해주는 DISK 사용량, 대기 큐 등을 사용하여 쉽게 구현할 수 있습니다.
하지만 문제가 있는데, “DISK 사용량은 낮지만, 여러 작업이 대기 중인 경우” 는 판단하기 어렵습니다. 이를 보완하기 위해 CPU, 메모리 사용량을 같이 볼 수 있겠지만, 이들을 종합하여 병목으로 볼 기준점을 찾기가 어렵다고 생각합니다.
결론적으로 DISK 사용량만으로는 서버에 트래픽이 몰려있는지를 확인할 서브 자료로 사용할 수는 있지만, 이것만으로 분명히 확인할 수는 없다고 ****판단하였습니다.
2.3 작업큐
보통 서버 병목은 처리해야 할 작업의 수가 많아질 때 발생합니다. 따라서 현재 얼마나 많은 작업을 진행/대기 중 인지를 추적한다면, 서버의 부하 상태를 파악할 수 있다고 판단했습니다.
물론 트래픽이 몰리지 않았어도 DISK 병목이 생길 수도 있습니다. 다른 Application을 하나의 컴퓨터에 동시에 띄운다면 그럴 수 있겠습니다. 하지만 Secondary Node 서버에는 단 1개의 프로세스(모니터링이 있지만 부하가 크지 않다고 판단하였습니다)만이 동작하고, 이 서버에서 처리하는 대부분의 작업들은 DISK 읽기/쓰기입니다. 그리고 복제 요청 역시 DISK 쓰기 작업에 해당합니다.
따라서 Secondary Node 서버에서 발생하는 DISK 병목의 원인은 사실상 작업 대기큐에 쌓인 작업 수와 관련이 있으므로, 작업 대기큐의 크기를 확인하는 것만으로도 현재 DISK에 얼마나 부하가 걸려 있는지를 충분히 예측할 수 있다고 판단하였습니다.
3. 작업 대기큐 설계하기
3.1 작업 대기큐를 설계하는데 직면한 문제
Node JS 언어 자체의 특징 때문에 작업 대기큐를 설계하기가 많이 어려웠습니다. 그 이유는 단순하게 작업들을 대기큐에 넣어, 한번에 하나의 작업을 빼서 처리하기 어려운 구조였기 때문입니다. 현재 Fastify 서버에서 DISK 쓰기는 하나의 작업을 모두 완료한 뒤에 다음 작업을 처리하는 것이 아닌, 병렬적으로 나누어서 진행됩니다.
즉, n개의 파일이 동시에 들어오면, 1→2→3→…→n 순서로 파일을 업로드 하는 것이 아니라, 청크단위로 [1~n까지 첫 번째 청크 업로드] → [1~n까지의 두 번째 청크 업로드]로 진행되게 됩니다. 모든 요청들을 조금씩 병렬적으로 처리하는 것 입니다.

예시를 들어 설명하겠습니다. A, B, C, D 작업이 있다고 하고 각 파일을 a, b, c, d 라고 해보겠습니다. 그리고 청크 번호를 n 이라고 해서 [파일이름]n이라고 하겠습니다. 그러면 4개 요청이 동시에 들어왔을 때, 위 이미지의 쓰기 처리과정을 거칩니다.
(스레드 4개 기준)
- 좌측 위가 event Loop 에 등록되는 작업입니다.
- 하단의 작업이 DISK 쓰기 작업입니다.
[a1, b1, c1, d1]가 약간의 텀이 있지만, 거의 동시에 진행 (event loop에 등록되는 시기 때문)
그러면 큐에서 작업을 뺄 때, 1개가 아닌 4개로 빼면 되는 것이 아닌가요?
라고 물어볼 수도 있습니다. 하지만 그렇게 할 수 없는데, 그 이유는 5개 이상의 작업이 들어왔을 때 역시 직렬적으로 처리되는 것이 아니라 병렬적으로 처리되기 때문입니다.
이전 예시에 E 작업만 추가하겠습니다. 5개의 작업이 들어오면, 다음처럼 처리됩니다.
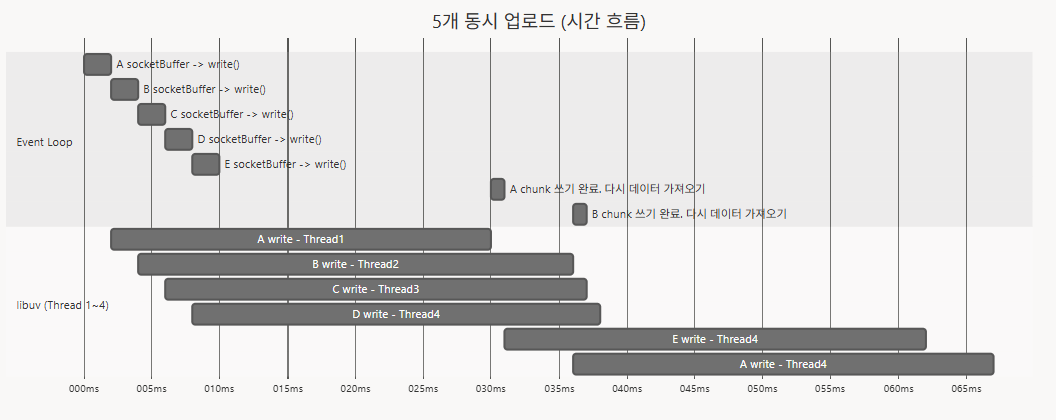
먼저 받은 4개의 작업이 완료된 뒤에, 뒤에 받은 E 작업을 진행하는 것이 아니라, A, B, C, D, E 개의 작업이 차례대로 진행하게 됩니다.
따라서 4개의 작업 단위로 큐에서 뺀다고 하더라도, 크게 의미가 없습니다. 이를 정말 큐로 막기 위해서는, Kafka와 같은 MQ를 도입하여, 별도 서버에서 받아서 앞단에서 처리해줄 필요가 있을 것 같습니다.
3.2 실제로 측정하여 가설 검증하기
위에서 이론적으로 예측한 내용이 실제 결과와 다를 수 있습니다. 왜냐하면 제가 JS, libuv 전문가도 아니고, 이전에 실제 검증 결과가 예상과 달랐던 상황 때문에 삽질을 많이 한 경험이 있습니다. 그 아픈 경험을 다시 하지 않으려면 반드시 실제 측정을 바탕으로 가설을 검증해야한다고 생각합니다.
3.2.1 실제 측정 방식
측정할때에는 다음 과정으로 이론을 검증 해보았습니다.
4개의 10MB 파일과 2개의 1MB 업로드 요청을 진행합니다. 각각을 순서대로 [A, B, C, D], [E, F] 라고 하겠습니다. 이론이 맞다면, ABCD가 먼저 서버 작업에 들어갔음에도 불구하고 E, F가 우선적으로 작업 완료처리가 되어야합니다. 즉, 작업 완료의 순서가 E, F, A, B, C, D 가 되어야합니다. 청크단위로 병렬처리가 되기 때문에 1MB 파일이 우선적으로 처리되어야하고 10MB 파일은 더 이후에 처리되기 때문입니다.
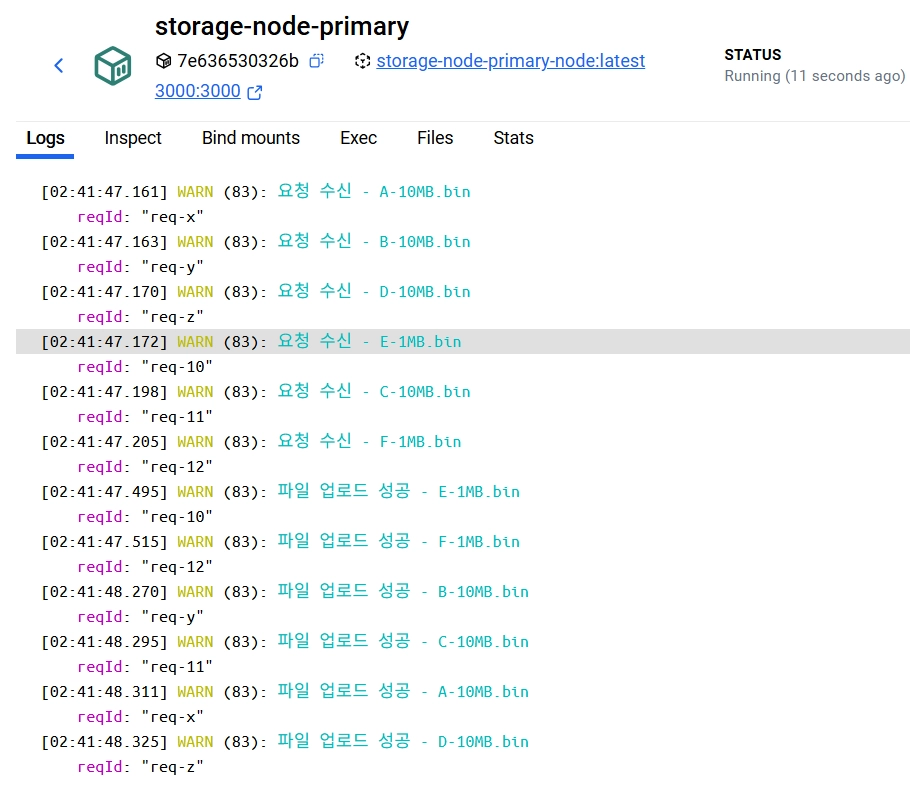
직접 측정을 해본 결과로, 가설을 검증할 수 있었습니다. 다음건 재미삼아서 다르게 한번 더 해보았습니다.
[ABCDE][FGHI] 이렇게 10MB, 1MB 파일로 테스트를 진행해봤습니다.

마찬가지로 1MB 파일이 먼저 업로드되고, 10MB 파일이 나중에 업로드 되는 것을 볼 수 있습니다.
이를 통해 이론 가설을 검증했습니다. 이제 이 병렬 처리 구조에서 작업 수를 어떻게 파악할 수 있을지 고민해보았습니다.
3.3 작업큐를 직렬적으로 변경
3.3.1 작업큐를 직렬적으로 변경
대기큐에서 작업을 1개씩 빼낼 수는 없습니다. n개 단위로 뺄 수도 없는 상황입니다. 그리고 이 문제의 원인은 작업이 병렬적으로 처리가 되기 때문입니다. 따라서 해결책은 이러한 처리를 직렬적으로 바꾸어 1개씩 빼내게 하는 방법이 있습니다.
1번에 1개씩 처리하면, 속도가 느려진다
하지만 1번에 1개씩만 처리하게 된다면, 속도가 느려진다는 우려도 있습니다. 현재 병렬 처리에서는 DISK에 쓰기작업을 진행하는 동안, 다른 요청들의 socket buffer에서 readable Stream으로 미리 옮겨놓는 작업을 진행하고 있습니다. 하지만 1번에 1개의 작업만 처리한다면, DISK에 쓰는 작업 도중에 js가 놀게되는 시간이 생기게 될 것 같습니다. (검증하지는 않았지만, 제 추측입니다)
1번에 4개씩 처리하면?
속도 저하가 우려된다면, libuv 스레드 단위에 맞춰서 4개씩 빼는 방법은 어떨까요? 생각보다 괜찮을 방법일지 모르겠습니다. DISK에 쓰는 동안 socket buffer에서 데이터를 읽는 작업을 진행할테니 말이죠!
3.3.2 직렬 처리의 문제점
하지만 직렬 처리에서의 근본적인 문제점이 하나 있습니다. 직렬적으로 바꾸게된다면, 데이터 처리가 느려지는 문제가 발생합니다. 정확히 말하자면 데이터 처리가 느려진다기 보다는 요청 처리 순서로 인해서, 불편함을 유발한다고 보는게 더 정확할 것 같습니다. 마치 HTTP/1.1 의 HOL(Head-of-Line) Blocking 문제처럼 말입니다.
HOL(Head-of-Line) Blocking 문제란, HTTP 전송에서 앞에있는 요청 데이터가 큰 경우 뒤에 작은 데이터가 오더라도 앞의 요청을 모두 처리한 후에 처리되는 문제를 말합니다. 구체적인 예시를 들어 설명하자면 1GB파일 → 1KB 파일순으로 HTTP 요청을 보낸다면, 1KB 파일은 매우 작지만, 1GB 파일을 모두 받은 이후에야 받을 수 있는 문제입니다.
직렬 처리로 바꾸게 된다면, 사용자 입장에서 ‘용량이 1KB 파일인데 왜이렇게 업로드/다운로드가 느려?’ 라는 불편함을 호소할 수도 있습니다. 즉, UX를 크게 감소시키게 될 수 있다고 판단하였습니다. 더군다나 현재 서비스는 write 만 하는 것이 아니라, read 요청도 많이 처리를 해야하기 때문에 더더욱 직렬화로 바꿀 수 없었습니다.
3.3.1의 한번에 4개씩 처리한다면 위 문제를 예방할 수도 있을 것 같습니다. 다만, 1GB 파일이 4개가 동시에 들어온다면 다시 문제가 터질 수는 있겠습니다.(물론 확률은 낮을 듯 합니다)
3.4 결론
결국 작업 수를 파악하기 위해 처리 구조를 바꾸는 대신, 현재 병렬 처리 구조를 그대로 유지하면서, 다른 방법으로 작업 수를 관찰하는 방향으로 진행하고자 하였습니다.
4. 작업 수 측정하기
결국에 저희가 알고 싶어 하는 정보는, ‘현재 서버가 몇 개의 작업을 처리하고 있느냐?’ 입니다. 그리고 조금 더 나아가서 재복제 요청에 영향을 줄 수 있는 작업인지까지 확인하면 좋을 것 같습니다.
4.1 재복제에 영향을 줄 수 있는 작업 파악하기
재복제 작업은 순수 DISK 쓰기 작업입니다. 따라서 DISK 작업에 병목이 없어야합니다. 그래서 DISK 작업의 병목에 초점을 두어 테스트를 진행하였습니다.
4.1.1 쓰기 요청 병목 테스트
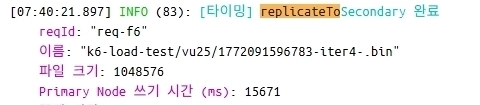
k6로 부하테스트를 진행했을 때의 일부 로그를 가져왔습니다. DISK 쓰기 작업에서 시간이 소요되는 것을 확인할 수 있었습니다.
4.1.2 읽기 요청 병목 테스트
| 항목 | 수치 | 비고 |
|---|---|---|
| Checks (성공률) | 100.00% | 총 9,156건 성공 / 0건 실패 |
| Data Received | 2.0 GB | 초당 평균 약 63 MB/s |
| Data Sent | 1.2 MB | 초당 평균 약 36 kB/s |
| 구분 | 응답 시간 (Latency) |
|---|---|
| Avg (평균) | 1.22s |
| p(90) | 1.7s |
| p(95) | 2.1s |
| p(99) | 11.1s |
위는 30초 동안 9156건의 서로 다른 파일(100KB, 1MB, 10MB) 읽기 요청에 대한 테스트 결과입니다. 읽기 또한 DISK에 병목 영향을 끼칠 수 있다고 판단하여 읽기의 작업 수도 고려해야한다고 생각하였습니다.
다만 쓰기보다는 병목이 작아서, 쓰기를 중심적으로 고려할 필요가 있습니다.
4.2 작업 수 판단 코드
4.2.1 Stream 수와 작업 수의 관계
┌─────────────────────────── Client ─────────────────────────────────┐
│ │
│ 요청 1 요청 2 │
│ │ │ │
└─────┼──────────────────────────────────────────┼───────────────────┘
▼ ▼
┌──────────────────────── Kernel (Network) ──────────────────────────┐
│ │
│ [ Socket Buffer 1 ] [ Socket Buffer 2 ] │
│ │
└──────────────┬───────────────────────────────┬─────────────────────┘
▼ ▼
┌──────────────────────── Node.js (User Space) ──────────────────────┐
│ │
│ 요청 1 흐름 요청 2 흐름 │
│ │
│ [ Readable Stream ] [ Readable Stream ] │
│ │ │ │
│ ▼ ▼ │
│ [ Writable Stream ] [ Writable Stream ] │
│ │
└──────────────┬───────────────────────────────┬─────────────────────┘
▼ ▼
┌──────────────────────── Kernel (File System) ──────────────────────┐
│ │
│ [ Page Cache ] (커널에서 공유됨) │
│ │
└──────────────────────────────┬─────────────────────────────────────┘
▼
[ DISK ]즉 쓰기 작업의 개수는 현재 열려 있는 Readable Stream 수와 비례한다는 것을 알 수 있습니다. 읽기 작업도 위 구조와 비슷한 구조를 갖습니다.
따라서 DISK IO에 사용되는 Stream의 개수를 바탕으로 병목이 될 수 있는 작업 수를 판단하기로 하였습니다.
4.2.2 디스크 쓰기/읽기 작업 수
DISK에 저장하는 메서드 내부에 전역 변수를 별도로 두어서, 작업 시작 시 +1, 종료 시에 -1 을 하는 방식으로 구현하였습니다.
/**
* 파일을 로컬 파일시스템에 저장
*/
export async function saveFileToStorage(
bucket: string,
objectKey: string,
fileData: MultipartFile
): Promise<string> {
...
// 파일 저장
const writeStream = fs.createWriteStream(filePath)
// stream이 닫히면 자동으로 '쓰기 작업 개수 -1'
writeStream.once('close', () => { _activeDiskWrites-- })
// 작업 수 +1
_activeDiskWrites++
await pipeline(stream, writeStream)
return filePath
}Stream이 닫히면 -1 하도록 구현하였습니다.
읽기도 마찬가지입니다
/* 파일 읽기 스트림 생성 */
export function getFileStream(bucket: string, objectKey: string): fs.ReadStream {
...
const stream = fs.createReadStream(filePath)
stream.once('close', () => { _activeDiskReads-- })
_activeDiskReads++
return stream
}이로써, 현재 진행 중인 DISK I/O 작업의 수를 API를 통해 얻을 수 있는 로직을 구현하였습니다.
5. 트래픽 판단 기준
과도한 트래픽의 적절한 기준을 잡아야했습니다. 트래픽 기준을 작게 잡는다면, 복제 로직 시도를 못할 것이고, 높게 잡는다면 부하가 있을 수 있기 때문입니다.
트래픽 판단의 기준을 잡기 정말 어려웠습니다. 보통 서비스를 사용한다면 카메라 이미지를 많이 올릴 것 같은데, 카메라 이미지(약 4MB)로 테스트를 한다고 하더라도, 몇 초를 기준으로 잡아야할지 어려웠기 때문입니다.
기준 찾아보기
기준 설정을 위해 Notion, Google Drive, Naver-MyBox 등 일상에서 많이 사용하는 서비스에서 실제 파일 업로드 시간을 측정해보았습니다.
1MB 파일을 올리는데 소요된 시간입니다. (업로드 대역폭 25Mbps (3MB/s) 환경에서 테스트)
(오차가 있을 수 있습니다.)
| 서비스 | 1MB 파일 업로드 소요 시간 | 5MB 파일 업로드 소요 시간 | 5MB 파일 다운로드 소요시간 |
|---|---|---|---|
| Notion (재미용) | 약 2.5초 | 10초 이상 | - |
| Google Drive | - | 약 3초 | 1.5초 이내 |
| Naver MyBOX | - | 약 1.5초 (최대) | 1초 이내 |
많은 사용자가 사용하는 대규모 서비스에서 응답 속도에 불편함을 느끼지 않는다는 점에서 이 수치를 트래픽의 부하 기준으로 정해도 괜찮겠다는 생각을 하였습니다.
파일 저장소인, google drive와 Naver My box를 기준으로, 5MB 파일의 업로드 시간은 중간 지점인 2.5초 기준으로 정하는 것이 괜찮겠다고 생각하였습니다. 읽기 소요시간은 넉넉하게 1.5초 이내로 잡았습니다.
5.1 테스트 결과
K6로 5MB 파일로 5m간 테스트를 진행하여, 요청 인원수별로 적정 트래픽을 찾아보았습니다.
5.1.1 읽기
| 동시 요청 최대 유저 수 | 20 | 30 |
|---|---|---|
| p(95) | 1.14s | 5.41s |
| p(99) | 1.35s | 6.93s |
읽기 작업의 경우 20명의 유저가 지속적인 다운로드 요청을 보냈을 때, p(95)=1.14s 가 나왔습니다. 따라서 20개의 작업을 적정 기준으로 설정하였습니다.
(30명이 되니 급수적으로 올라갔는데, 아마 추측하기에는 병렬적으로 요청을 처리하고 있기 때문이 아닐까 싶습니다.)
5.1.2 쓰기
| 동시 요청 최대 유저 수 | 10 명 | 15 명 | 20 명 |
|---|---|---|---|
| p(95) | 744.07ms | 810.16ms | 3.23s |
| p(99) | 7.01s | 11.4s | 10.14s |
아무튼 쓰기도 마찬가지의 이유로 15개의 DISK 쓰기 작업을 적정선으로 설정하였습니다.
(읽기와 마찬가지로 병렬 처리로 인해서 15 → 20 명으로 올라가면 갑작스럽게 p(95)가 올라가는 것 같습니다.)
5.2 기준 설정하기
우선은 쓰기가 15개 이상이거나, 읽기가 20개 이상인 경우를 트래픽 부하로 설정하여, 재복제 요청을 보내지 않도록 처리하였습니다.
그리고 병렬 작업으로 인해, 요청 딜레이가 늘어나는 지점이 20개 근처인 것으로 보여서, 쓰기 작업 + 읽기 작업 < 20 인 조건도 추가하였습니다.
(적정선을 더 정확하게 정하려면, 쓰기 작업 1개당, 몇개의 읽기 작업에 해당하는지를 측정하여 적용할 수 있을 것 같지만, 이정도의 트래픽에서는 오차도 크고 큰 의미도 없을 것 같아 따로 계산하지는 않았습니다.. )
6. 구현 및 흐름
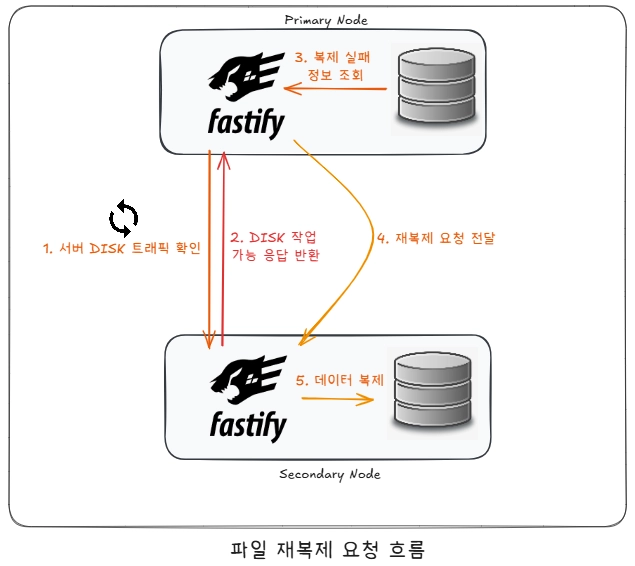
위 흐름을 구현한 코드입니다.
async function retryFailedReplications(
replicationQueue: ReplicationQueueRepository,
log: FastifyBaseLogger,
): Promise<void> {
// 1. Secondary 노드의 현재 작업량을 확인하여 복제 가능 여부 판단
const idle = await isSecondaryNodeIdle(log);
// 2. 작업 가능 여부 확인
if (!idle) return;
// 3. 복제 실패한 정보들 sqlite에서 가져오기
const replicationObjects = replicationQueue.fetchRetryBatch(RETRY_WORKER_BATCH_SIZE);
if (replicationObjects.length === 0) return;
// 4. 재복제 요청 전달
for (const row of replicationObjects) {
const { bucket, objectKey } = row;
try {
await replicateToSecondary(bucket, objectKey, log);
} catch (err) {
...
// 복제 실패 시, 복제 실패 정보를 업데이트
replicationQueue.updateOnRetryFailure(
bucket,
objectKey,
errorType,
errorMessage,
);
...
continue;
}
// 복제 성공 시, 데이터 삭제
replicationQueue.deleteOnSuccess(bucket, objectKey);
}
}핵심은 1번 단계입니다. 재복제를 요청을 하기 전에, isSecondaryNodeIdle을 호출하여 현재 작업량을 확인하고, Secondary 서버의 작업량이 기준치를 초과하지 않은 경우에만 재복제를 하여, 트래픽이 몰린 시점의 추가 부하를 방지합니다.
