
기능을 구현하게 된 계기
대용량 파일을 업로드하다 보면, 중간에 네트워크 문제가 발생하거나 새로고침으로 인해서 업로드가 끊기는 경우가 발생할 수 있다. 10MB와 같이 작은 파일의 경우, 문제가 없겠지만, 5GB, 10GB 파일들은 업로드하는데 시간이 굉장히 오래 걸린다..!
(이런 파일을 업로드하다가 끊기면, 아마 화가 날 수도 있을 것 같다...)
이러한 불편함을 개선하기 위해서 업로드 재개 기능을 한번 도입해보려고한다.
이번에는 업로드/다운로드가 끊긴 지점부터 다시 업로드 하는 기능을 구현하는 과정을 담았습니다.
1. 이어서 업로드 하는 2가지 방법
업로드를 이어서 하는 2가지 방법이 있습니다.
- Multi-part Upload : 하나의 파일을 여러 파일로 나누어서 업로드하고, 이후 하나의 파일로 합치는 방법
- Offset 기반 append 방식의 업로드 : 하나의 파일에서 offset을 기반으로 이어서 write 하는 방법
기타 방법 (웹소켓으로 업로드를 한다거나 하는 방법)이 있겠지만, 현 storage 서비스와는 맞지 않아 제외하였습니다.
어떤 방법을 사용할지 고민해보았습니다.
2.1 방법 1 - multipart Upload 방식
여러 파일로 나누어서 업로드하고, 이후 하나의 파일로 합치는 방법
2.1.1 작동 방식 이해하기
실제 AWS S3에서 해당 multi-part Upload 방식을 사용할 수 있고, 권장하고 있습니다.
https://aws.amazon.com/ko/blogs/big-data/using-aws-for-multi-instance-multi-part-uploads/
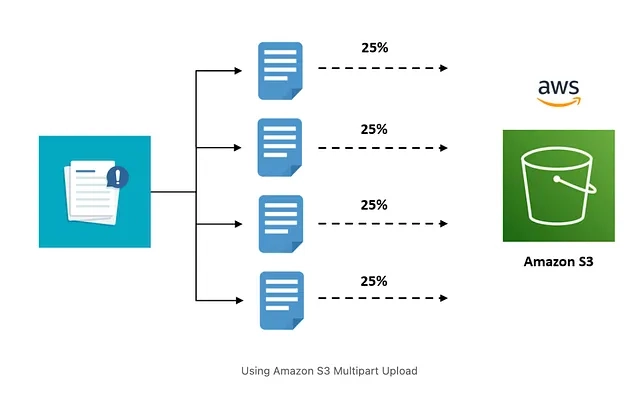
위 이미지처럼 하나의 큰 파일을 part A, B, C, D 4개의 파일로 나누어서 각각을 독립적으로 Upload하는 방식입니다. 각각을 병렬적으로 업로드하기에 (네트워크 대역폭이 충분하다는 가정하에) 더 빠르게 업로드를 진행할 수 있습니다.
2.1.2 장점
하나의 큰 파일을 병렬적으로 받을 수 있어서, 업로드 속도가 빠르다는 장점이 있습니다.
즉, 1GB파일을 100MB씩 10개의 파일로 나누어서 병렬적으로 받게되면, 업로드에 100초가 걸릴 작업을 대략 10초 정도에 할 수 있게됩니다.
따라서 대용량 파일을 자주 업로드하거나, 속도가 중요하다면 이 방법이 좋은 선택지가 될 수 있을 것 같습니다.
2.1.3 문제점1 : 다른 업로드 요청 속도 감소
업로드 세션이 많아지면, 다른 업로드 세션 속도가 줄어든다
현재 제 프로젝트에서는 병렬 기반의 업로드를 사용하고 있습니다. 즉, 여러 사용자들의 업로드 요청들을 병렬적으로 처리하고 있습니다.
하지만 multipart 업로드로 인해, 업로드 요청이 많아지게 된다면 모두가 공정한 업로드 속도를 갖는것이 아니라, multipart 의 part 별 세션이 모두 자원을 가져가게 됩니다. 공정하지 않게 되는 것입니다!
아래는 예시를 작성해보았습니다.

A, B, C, D 4개의 요청이 동시에 들어오면, 이들을 각각 병렬적으로 처리하고 있습니다. 이 과정에서 만약 1개의 추가적인 요청 E가 더 들어온다면, E를 포함해서 다시 병렬적으로 처리가 진행됩니다. (이러한 구조를 사용한 데에는 작은 파일을 빠르게 올리기 위함이었습니다.)
이러한 상황에서 multipart 업로드 방식을 사용하면 다른 사용자들의 요청이 느려지는 문제가 발생할 수 있습니다.
예를 들어서 [A, B, C, D] 4개의 요청이 존재하고, [A, B, C]는 각각 10MB, [D] 파일은 10GB라고 가정해보겠습니다. 그리고 초당 처리 속도가 10MB 라고 가정하겠습니다.
10GB를 1개의 요청으로 받게 된다면, ABCD는 트래픽을 고르게 나누어 가져서, 각각 초당 2.5MB를 처리할 수 있습니다. 즉, ABC는 약 4초만에 쓰기를 완료할 수 있게됩니다.
하지만 multipart 방식을 사용하여, 10GB 파일을 100개의 요청으로 분할해서 업로드를 한다면, 요청의 수가 A,B,C,D1,D2,…,D100 가 됩니다. 따라서 각각 초당 10/103 MB/s = 약 90KB/s 의 처리 속도를 갖게 됩니다. A,B,C 파일을 쓰는데에 약 25초가 넘게 소요되게 됩니다. 즉, 1개의 대용량 파일을 업로드하게 되면, 다른 사용자의 업로드 속도를 저하시킬 수 있습니다.
2.1.4 문제점2: 재복사
중복된 DISK 쓰기 작업
또 다른 문제점으로 merge 작업이 있습니다.
multipart로 나누어서 업로드를 하게 될 경우에는, 나누어진 part 파일을 병합하는 과정이 필요합니다.
A 파일을 a1, a2, a3, a4로 나누어서 받는다고 하면, 실제 DISK에는 a1, a2, a3, a4 파일이 업로드 됩니다. A라는 파일을 만들기 위해서는 받은 각각의 파일들을 병합하는 과정이 필요합니다. (a1 + a2 + a3 + a4 ⇒ A)
즉, 1GB파일을 받는다고 하면, 각 part 별로 총 1GB 를 쓰고, 이를 병합하는데 1GB, 총 2GB를 써야합니다.
현재 핵심 병목이 DISK 에 있기 때문에, 가능하면 중복하여 2번 쓰지 않는 것이 좋아보였습니다.
따라서 DISK 쓰기 비용을 조금이라도 줄이기 위해서는 위 과정은 가능하면 피하는 것이 좋다고 판단하였습니다.
2.2 방법 2 - 파일 자체에서 append를 통해 이어쓰기
두 번째 방법으로는 파일을 이전에 썼던 지점부터 다시 이어 쓰는 방법이 있습니다.
2.2.1 작동 방식 이해하기
다음 1GB 파일을 올린다고 가정하겠습니다. 각 라인은 100MB를 담고 있습니다.
// 총 1GB 파일
aaaaa...aaaa // 100MB
bbbbb...bbbb // 100MB
ccccc...cccc // 100MB
ddddd...dddd // 100MB
eeeee...eeee // 100MB
...그런데 중간에 네트워크 문제로 인해서 업로드가 끊겼습니다
aaaaa...aaaa // 100MB
bbbbb // 여기까지 쓰다가 연결 종료원래라면 다시 처음부터 aaaa…aaa 를 작성해야하지만, append를 통해서 이어나가면 bbb 부터 작성할 수 있게 됩니다. 즉, 다시 쓰기를 시작할 지점의 offset을 기록해서 해당 offset 부터 이어쓰는 것입니다.
aaaaa...aaaa // 100MB
bbbbb | **여기에서 바로 이어쓰기 (append)**2.2.2 장점과 단점
append 하는 방식은 별도로 파일들을 병합하는 추가 작업이 필요 없다는 장점이있습니다.
하지만 하나의 세션으로 업로드를 진행하다보니, multipart에 비해서 업로드 속도가 느리다는 단점이 있습니다.
하지만 위 단점은 현재 프로젝트 처리 방식과의 충돌로 인해서 피하는 것이 낫다고 판단하였고, DISK 쓰기를 조금이라도 줄이기 위해 append 방식으로 resumable Upload를 구현하기로 결정하였습니다
3. append 로 Resumable Upload 구현하기
3.1 구현 방식
구현은 두가지 방식이 있습니다.
- 직접 구현하는 방식
- 라이브러리를 사용하는 방식 파일을 그대로 이어붙여주는
tus-node-server패키지가 있습니다.
직접 구현하는 방법보다는 라이브러리를 사용해서 구현하는 것이 시간상으로도, 완성도 측면에서도 도움이 될 것이라고 생각하였습니다.
라이브러리는 tus, Uppy, Resumable.js 가 있었고, 프론트와 서버 모두 지원하는 tus-node-server를 사용하여 구현하였습니다.
https://github.com/tus/tus-node-server
3.2 tus Libary
해당 라이브러리를 가져와서, 현 프로젝트 흐름에 맞추어야하였기에, 어떤 방식으로 동작하는지를 학습하고 현 프로젝트에 어떻게 도입하여야할지를 고민하였습니다.
3.2.1 동작 방식
동작 방식은 다음 공식 문서를 참고하였습니다.
- POST를 통해 서버에 Metadata를 보내고, 파일을 업로드할 수 있는 URL을 받기
- PATCH URL 을 통해서 파일을 업로드
- Upload-Offset 헤더 포함 : 파일 쓰기를 시작할 byte 위치
- request 성공 시 = 업로드 완료
- 업로드 도중에 실패했을 경우
- 사용자는 resume the upload 로 이어서 업로드를 재개 수 있다.
- 해당 URL로 HEAD 요청을 통해서, Upload-Offset header를 받을 수 있다. 이를 바탕으로 이어쓰기를 한다.
- 사용자가 해당 업로드를 삭제하고 싶은 경우
- DELETE 요청을 통해 upload URL을 삭제할 수 있다.
- 이 경우에는 이어쓰기(resuming the upload) 가 더 이상 불가능하다
3.2.2 현 프로젝트에 도입 시, 수정 및 override가 필요한 부분들
동작하는 방식에 있어서, 현 프로젝트와 크게 충돌하는 부분이 없다고 생각했고, 현재 방식과 다른 부분들은 override나 추가 구현을 통해 해결할 수 있다고 판단하였습니다.
기존 방식과 다른 부분은 아래와 같습니다.
URL 발급 및 검증 과정
PATCH URL을 받아 업로드를 진행하게 됩니다. 하지만 보안을 위해서 해당 업로드 URL이 올바른 업로드인지, 만료되지는 않았는지를 검증하는 과정이 필요합니다. 따라서 동작 방식의 1, 2 부분을 보완할 필요가 있습니다.
메타데이터 저장 위치
파일 업로드에 필요한 메타데이터를 기본적으로 memory에 저장하는 기본 코드를 지원하고 있습니다. (샘플이긴 합니다) 메모리에 저장하면, 서버 재시작 시 메타데이터가 날라갈 수 있으므로, 이 부분도 DISK에 저장하도록 수정이 필요할 것 같습니다.
3.2.3 테스트해보기
간단하게 실제로 잘 돌아가는지 확인 겸 흐름을 확실하게 이해하기 위해서 겸사겸사 테스트를 해보았습니다. 1GB로 테스트를 했더니 잘 작동하고, 중간에 끊어도 offset을 이어 받아서 잘 작성하는 걸 확인할 수 있었습니다.
아래는 그냥 offset을 어디에서 어떻게 가져오는지 궁금해서 직접 구현 코드를 뜯어서 offset을 어디에 저장하고 어디에서 가져오는지 확인해본 내용입니다.
https://www.notion.so/TUS-31afc6c66701808da996eefd70b85c0a?source=copy_link
4. 처리 흐름 설계하기
흐름을 설계하고, 발생할 수 있는 문제점들을 검토하며 보완하는 과정을 작성하였습니다.
4.1. 흐름
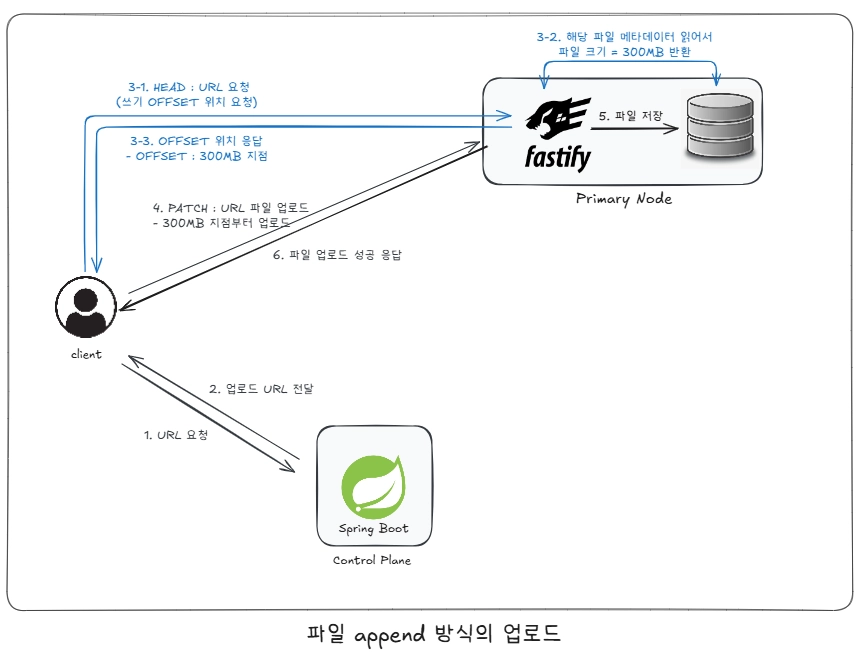
tus-server 코드를 최대한 유지한 방향으로 설계를 진행하였습니다. 이로인해, SpringBoot에서 Presigned URL을 받고, 또다시 PATCH 용도의 URL을 재발급 받아야한다는 불편함이 있습니다.
정확한 흐름은 다음과 같습니다.
1. Control Plane에서 Presigned URL 발급
2. POST 요청을 통해 Primary Node 에서 업로드용 URL 발급 및 Primary Node에 저장할 파일 생성
3. 'HEAD : 업로드용 URL**'** 을 통해 OFFSET 확인
4. 'PATCH : 업로드용 URL' 을 통해 OFFSET 지점부터 파일 업로드
5. 성공 응답 반환물론 Control Plane에서 Primary Node로 POST 요청을 보내어, 업로드용 URL을 바로 발급 받을 수도 있습니다. 하지만 TUS 로직 상, POST 요청을 보내는 순간, 저장할 파일이 생성되기 때문에 사용자가 URL을 사용하지 않는다면, 더미 파일이 생겨버릴 수 있습니다.
따라서 조금 번거로울 지라도, 2번의 걸쳐서 요청을 보내는 방식을 선택하였습니다.
4.2 첫 파일 업로드 시 발생하는 문제점 - 불필요한 HEAD 요청
파일을 처음으로 업로드하는 경우에서 발생할 수 있는 문제점이 있습니다.
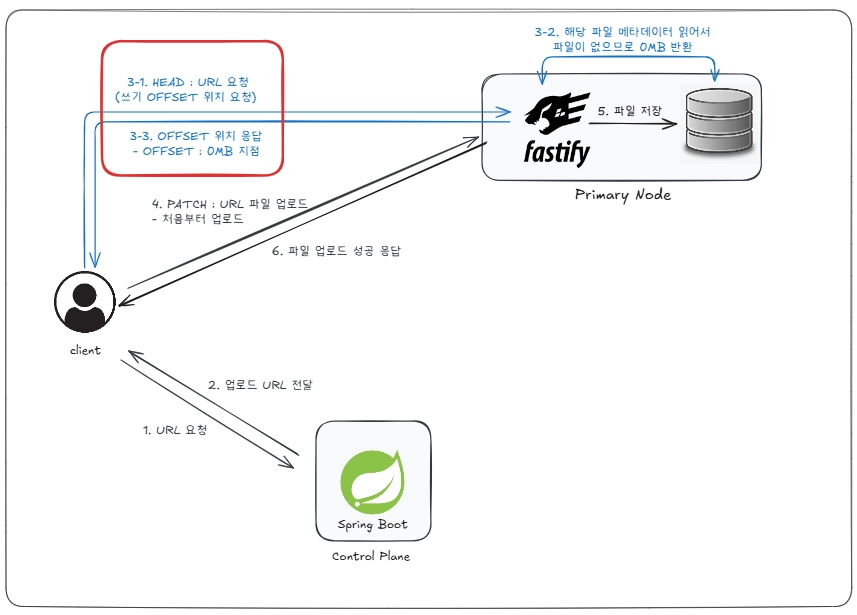
파일을 처음으로 업로드하는 경우에는 위와 같은 HEAD 요청이 불필요합니다. 왜냐하면 항상 파일의 처음 위치부터 업로드하기 때문입니다. 따라서 이러한 불필요한 요청을 어떻게 줄일 수 있을지를 고민하였습니다.
4.3.1 해결 방안 1 - Presigned URL 발급 시, OFFSET 정보 보내기
먼저, Presigned URL을 발급 받을 때, 데이터의 OFFSET 을 같이 전달하는 방법이 있습니다.
이렇게 된다면, Primary Node에서 파일을 업로드하는 시점과 완료한 시점에 Control Plane에 요청을 보내주는 로직이 추가되어야합니다.
4.3.2 해결 방안 2 - 대용량 파일일 경우에만 HEAD 요청을 전송하기
두 번째 방법은 HEAD 요청의 횟수 자체를 줄이는 방법입니다. 100KB, 1MB와 같은 작은 파일에는 HEAD 요청을 전송하지 않고, 바로 업로드를 진행하도록 처리할 수 있습니다. 도중에 끊겼을 경우에도 처음부터 덮어 쓰기 방식으로 진행하는 방향입니다.
이렇게 되면 Frontend 코드에서 용량을 먼저 확인하고 HEAD를 보낼지 말지를 처리하게 될 것 같습니다.
대부분의 요청은 용량이 크지 않은 파일이고, 해결 방안 2를 도입하게 되면, HEAD 요청의 수가 상당히 감소하게 됩니다. HEAD 요청이 불필요하게 많이 생기지는 않을 것이라고 판단하여, 우선은 해결 방안 2를 선택하여 도입하기로 결정하였습니다.
(추후에는 방안 1 도입도 고려해봐야겠습니다)
5. 구현하기
5.1 API 엔드포인트 분리
4.3.2의 방식을 적용하기 위해 대용량 파일과 저용량 일반 파일 업로드의 API endpoint를 다르게 설정하였습니다. 하나의 엔드포인트에서 처리할 수도 있지만, 업로드의 방식이 다르고 resumable 방식에는 header값들이 많이 추가되기 때문에, 동일한 URL로 처리하기 보다는 분리해서 처리하는 것이 좋다고 판단하였습니다.
다음과 같이 URL을 발급받도록 구현하였습니다.
- 100MB 보다 작은 파일 업로드 요청 ⇒ 일반 업로드 URL = uploads/direct
- 100MB 보다 큰 파일 업로드 요청 ⇒ resumable 업로드 URL = uploads/resumable
5.2 tus FileStore override
tus에서는 기본적으로 file_id 값을 사용해서 하나의 디렉토리에 모든 파일을 저장합니다. 즉, 파일 이름과 위치를 file_id로 저장하고 메타데이터도 file_id로 얻습니다.
하지만 현 서비스에서는 디렉토리 기반의 파일 경로 기반 구조를 사용하고 있기 때문에, 경로가 없는 경우 자동으로 생성되는 로직을 추가하여 구현하였습니다.
create()의 생성로직만 바뀌고 나머지는 동일하기 때문에, create() 만 override하였습니다.
class CustomFileStore extends FileStore {
private readonly _directory: string;
constructor(options: FileStoreOptions) {
super(options);
this._directory = options.directory;
}
create(file: TusFile): Promise<TusIFile> {
return new Promise((resolve, reject) => {
const filePath = path.join(this._directory, (file as unknown as { id: string }).id);
const dirPath = path.dirname(filePath);
// 디렉토리가 없는 경우 생성
fs.mkdir(dirPath, { recursive: true }, (mkdirErr) => {
if (mkdirErr) {
return reject(mkdirErr);
}
return super.create(file).then(resolve).catch(reject);
});
});
}
}5.3 Configstore 메모리 조회 → DISK 조회
Configstore의 역할은 업로드하는 파일의 메타데이터를 저장하는 공간입니다. 해당 파일의 총 크기를 바탕으로 업로드 요청의 재개 여부를 판단합니다. (즉, 파일 총 크기보다 현재 저장된 파일이 작다면, 업로드를 재개해야하는데, 이러한 파일의 총 크기 정보를 저장합니다)
기본 tus 라이브러리에서 제공하는 방식은 메모리에 메타데이터를 저장/조회하는 방식입니다.
// 기존 제공
class MemoryConfigstore {
constructor() {
this.data = new Map();
}
async get(key) {
let value = this.data.get(key);
if (value !== undefined) {
value = JSON.parse(value);
}
return value;
}
async set(key, value) {
this.data.set(key, JSON.stringify(value));
}
async delete(key) {
return this.data.delete(key);
}
}
module.exports = MemoryConfigstore;
메모리는 속도가 빠르다는 장점이 있지만, 서버가 예상치 못하게 종료되면 파일을 처음부터 다시 올려야하는 문제가 있습니다. 따라서 해당 방식을 메모리 방식에서 DISK에 저장하는 방식으로 수정하였습니다.
속도보다는 안정성이 더 중요하다고 판단하여, DISK에 저장하는 방식을 선택하였습니다.
5.3.1 필요 기능
다음 기능을 지원할 수 있어야합니다.
file_id(파일경로)를 통해서, 메타데이터를 조회/쓰기가 가능해야합니다.- 일정 시간이 지난, 만료된 데이터를 삭제할 수 있어야합니다.
- 상태를 조회할 수 있어야합니다.
파일 여러개의 메타데이터를 동시에 쓸 수도 있으므로, 충돌을 막기 위해서 일반 파일을 사용하는 것은 좋지 않을 수 있겠다고 생각하였습니다. 또한 많은 데이터가 저장되는 것이 아니기에, 별도 DB 서버를 운용할 필요가 없습니다.
따라서 embedded DB 중, RocksDB, SQLite 중 고민을 하였고, 위 상황에 SQLite가 적합하다고 판단하였습니다. RocksDB는 Key Value의 형태로 저장하기 때문에, 만료 데이터 조회나 상태 조회가 어렵기 때문입니다. 더구나 기존에 서버에서 사용하던 SQLite가 있어, 그대로 가져가서 사용하면 되기 때문입니다!
SQLite를 기반으로 메타데이터를 관리하는 Configstore를 추가하였습니다.
export default class SqliteConfigstore {
private readonly getStmt: Statement;
private readonly setStmt: Statement;
private readonly deleteStmt: Statement;
constructor(db: InstanceType<typeof Database>) {
this.getStmt = db.prepare(QUERIES.GET);
this.setStmt = db.prepare(QUERIES.SET);
this.deleteStmt = db.prepare(QUERIES.DELETE);
}
async get(key: string): Promise<IFile | undefined> {
const row = this.getStmt.get(key) as TusFile | undefined;
if (row === undefined) return undefined;
const file = new TusFile(
row.id,
row.upload_length ?? "",
row.upload_defer_length ?? "",
row.upload_metadata ?? "",
);
return file as IFile;
}
async set(key: string, value: IFile): Promise<void> {
const { upload_length, upload_defer_length, upload_metadata } = value;
this.setStmt.run(
key,
upload_length || null,
upload_defer_length || null,
upload_metadata || null,
);
}
async delete(key: string): Promise<boolean> {
const result = this.deleteStmt.run(key);
return result.changes > 0;
}
}이제 메타데이터 조회, 저장, 삭제 시 SQLite를 통해 진행됩니다.
5.4 PATCH URL 검증
5.4.1 검증의 필요성
tus는 기본적으로 다음 resumable 업로드 URL을 반환해줍니다.
http://localhost:3000/{tus api path}/test_bucket/abc/test(1).jpg이를 그대로 사용할수도 있겠지만, 어떤 사용자가 악의적으로 요청을 수정하진 않았는지, 해당 URL이 만료되었는지 등을 검증하기가 어렵습니다. 따라서 이를 검증하는 로직이 필요하다고 생각하였습니다.
5.4.2 시도 1 - TUS 라이브러리 코드를 수정하기
우선 코드를 수정하여 URL에 signature를 넣어, 검증 할 수 있도록 하려고 하였습니다.
그래서 URL을 생성하는 로직을 살펴보았습니다. TUS의 BaseHandler - generateUrl 을 통해서 생성이 됩니다. (Handler는 응답을 처리하는 class 입니다)
class BaseHandler extends EventEmitter {
generateUrl(req, file_id) {
return this.options.relativeLocation ? `${req.baseUrl || ''}${this.options.path}/${file_id}`
: `//${req.headers.host}${req.baseUrl || ''}${this.options.path}/${file_id}`;
}
...
}그래서 BaseHandler를 override하여 수정하려고 했습니다.
하지만 문제는 기존 클래스들이 모두 BaseHandler를 상속하기 때문에 수정해서 적용이 불가능합니다.
class PostHandler extends BaseHandler {...}그래서 BaseHandler로는 수정을 할 수 없어, 다른 방법을 찾아야 했습니다.
5.4.3 시도 2 - SQLite에 세션 정보 저장시키기
현재 메타데이터 정보를 SQLite에 저장하고 있습니다. 즉, 상태를 이미 저장하고 있고
- 서버 재시작 시, 업로드 유지
- 세션 검증 데이터와 TUS 상태 데이터 생명 주기가 동일하다는 것을 바탕으로
SQLite에 저장하여 URL을 검증하고 만료를 확인하는 방법을 선택하였습니다.
즉, URL 요청이 들어오면, 해당 URL이 만료되었는지 여부를 DB에서 판단하고 만료되지 않았다면 업로드를 시작하는 방식입니다.
파일의 크기 검증은 기본적으로 TUS가 지원을 해주기 때문에 URL의 유효기간만을 검증하도록 구현하였습니다.
만료된 데이터 삭제하기
SQLite는 별다른 조치를 하지 않으면 영속적으로 저장되기때문에, 주기적인 삭제 작업이 필요합니다. 따라서 서버 시작 및 1일 주기로 삭제 처리를 하도록 설정하였습니다.
6. 대용량 파일의 기준 설정하기
테스트를 통해서 대용량 파일의 기준을 설정하는 단계입니다. 다른말로 표현하자면, resume upload 를 적용할 파일의 크기를 설정하는 단계입니다.
작은 파일인 경우에는 굳이 resume upload를 할 필요 없이, 다시 upload 하는게 성능상 더 좋으니 기준선을 잘 찾을 필요가 있습니다.
6.1 기준을 설정할 때 고려한 점
어느정도를 기준으로 잡아야할지 최적의 값을 찾는 것은 꽤나 어려운 일입니다. 그래서 AWS S3를 찾아보았습니다.
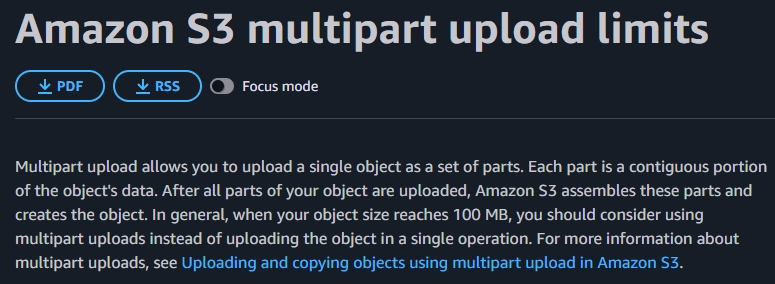
S3의 경우, 100MB 부터 multipart 도입을 권장하고 있습니다.
https://docs.aws.amazon.com/AmazonS3/latest/userguide/mpuoverview.html?utm_source=chatgpt.com
물론 S3의 경우 multipart upload 이기 때문에, 업로드 속도를 빠르게 하기 위해서 100MB부터 도입한다는 측면도 있습니다. 하지만 제 프로젝트에서는 append 방식의 upload 이기에, 속도는 그대로입니다.
하지만 세계적으로 많이 사용되는 서비스에서 100MB를 기준으로 권장을 하고 있기 때문에, 이 수치를 사용해도 괜찮겠다고 판단하였습니다.
또한 현재 제가 대여하고 있는 Azure 서버 컴퓨터의 최대 네트워크 대역폭은 6250 Mbps ≈ 781.25 MB/s 으로 큰 문제가 없고, 일상 환경에서 저비용 인터넷 업로드 대역폭이 40Mbps인 듯 하여, 40Mbps 기준으로 생각을 해보았습니다.
- 학교 인터넷 : 20Mbps
- 일반 가정(우리집) : 40Mbps
- LTE : 40Mbps
일상에서 100MB 파일을 업로드하는데 보통 20-30초 정도가 소요됩니다. 20초는 사용자가 느끼기에 상당히 긴 시간으로 느껴질 것 같아, 50MB 파일을 기준으로 50MB 이상의 파일은 resumable Upload를 적용하고, 그 미만의 파일은 단순 업로드를 하도록 구현하였습니다.
6. 성능 테스트 결과
1. 테스트 조건 요약
- (네트워크 대역폭 제한 없음 - 로컬에서 테스트)
- 파일 크기: 1.00 GB (1024 MB)
- 청크 크기: 5 MB
- 중단 시점: 500 MB 전송 후 중단
| 항목 | 기존 방식 - Restart | 업로드 재개 방식 - Resume | 차이 (절감 효과) |
|---|---|---|---|
| 복구 소요 시간 | 20.7 초 | 10.9 초 | 9.8 초 (47.3% ↓) |
| 전체 소요 시간 | 32.2 초 | 21.6 초 | 10.6 초 (32.9% ↓) |
| 총 전송량 | 1524 MB | 1024 MB | 500 MB (32.8% ↓) |
| 낭비 데이터 | 500 MB | 0 MB | 100% 제거 |
간단하게 1GB를 기준으로 테스트를 진행하였습니다. 만약 데이터가 더욱 커진다면, 더 큰 효과를 발휘할 수 있을 것 같습니다.
7. 배운점
확장성과 유지보수를 고려하여 코드를 작성하는 태도를 기르자.
7.1 오픈소스를 읽은 계기
이번에 tus라는 오픈소스를 직접 뜯어서 디버깅도 해보고, override도 해보는 과정을 가지게 되었습니다.
사실 AI를 사용해서 간단하게 처리하려고 했지만, AI가 짜준 코드가 작동을 안하는 경우가 굉장히 많았습니다. 뿐만아니라, 왜 작동을 안하는지 확인을 하기 위해서도 직접 로직을 살펴보아야하는 경우가 많았습니다.
그래서 오픈소스 파일을 직접 읽고 디버깅도 하면서 흐름을 파악하는 과정에 시간을 많이 들였습니다.
7.2 오픈소스를 보면서 느낀점
코드를 보면서, 추상화가 굉장히 잘 되어있다는 것을 느꼈습니다. 정말 interface만 딱 바꾸면, 다른 기능으로 사용할 수 있게 되어있습니다.
(Store와 Configstores는 손쉽게 갈아 끼울 수 있습니다.)
이번 프로젝트를 하면서, 추상화를 전혀 고려하고 있지 않았습니다. 기능이 안정적으로 돌아가도록 하는게 최우선의 목표였고 하루빨리 잘 돌아가는 걸 보고싶어서 코드 퀄리티를 많이 고려하지 않았던 것 같습니다.
그래서 제가 해야할 다음 과제는 리팩토링. 그 중에서도 추상화를 할 필요가 있는 부분들을 찾아서 수정해야겠습니다.
현재 디렉토리 구조의 파일구조로 파일을 저장하고 있는데, 추후에 확장이 될 경우 BLOB Storage(블록 저장소) 로 바꿀 필요가 있습니다. 메타데이터라던가, 작은 크기의 파일들을 효율적으로 저장하는 방식이기 때문입니다.
따라서 다음번에는 파일 저장 기능들을 interface로 바꾸어볼 생각입니다.
고민해봐야할 문제
결국에 resumable upload 방식은, 하나의 요청으로 업로드를 처리하는 합니다. 따라서 본질적으로 속도 문제에 있어서 아쉬움이 있습니다.
10GB파일... 더 나아가 100GB파일을 올린다면, 요청 1개로는 몇시간이 걸릴지도 모르겠네요. 따라서 이러한 속도 문제를 해결하기 위해서 multipart를 도입할 필요가 있는데, 문제는 disk 병목인 것 같습니다. 더 나아가 다른 사용자의 업로드 속도에 영향을 미친다는 점. (이것도 DISK 병목이 원인입니다)
물론 DISK를 프리미엄으로 업그레드를 한다거나 하는 방법이 있을 수 있겠지만... 이런 비용적인 문제는 가능하면 피하고 싶었습니다.
이러한 문제를 어떻게 해결할지 고민을 해봐야겠습니다.
지금 당장 떠오르는 방법으로는...
multipart가 다른 사용자의 요청을 가로막아서 문제라면, 가로막음을 최소화시키면 되지 않을까? 동시 세션 수를 동적으로 줄인다거나 해서!
merge 작업으로 DISK 병목이 생긴다면, merge를 안하면 되지않을까? part 데이터를 SQLite에 저장하던가 해서...!
여러가지 방법이 있을 것 같습니다. 이러한 부분은 다음번에 알아보도록 하겠습니다
