우리는 ChatGPT를 많이 사용합니다. ChatGPT는 우리에게 유용한 정보를 아낌없이 주지만, 가끔씩 얼토당치 않은 답변을 주기도 합니다. 이를 환각 현상(Hallucination)이라고 표현합니다. 이러한 환각 현상을 줄이기 위해 수많은 방법론이 고안되었고, 그 중에서 가장 많이 사용되는 방법은 단연코 RAG(Retrieval-Augmented Generation) 일것입니다. RAG는 LLM이 응답을 생성하기 전 외부 데이터베이스에서 관련 정보를 탐색한 후, 해당 정보를 문맥에 포함시켜 최종 응답을 만들어내는 방법론을 일컫습니다. 대표적으로 ChatGPT의 '검색 기능', Perplexity AI가 있겠네요.
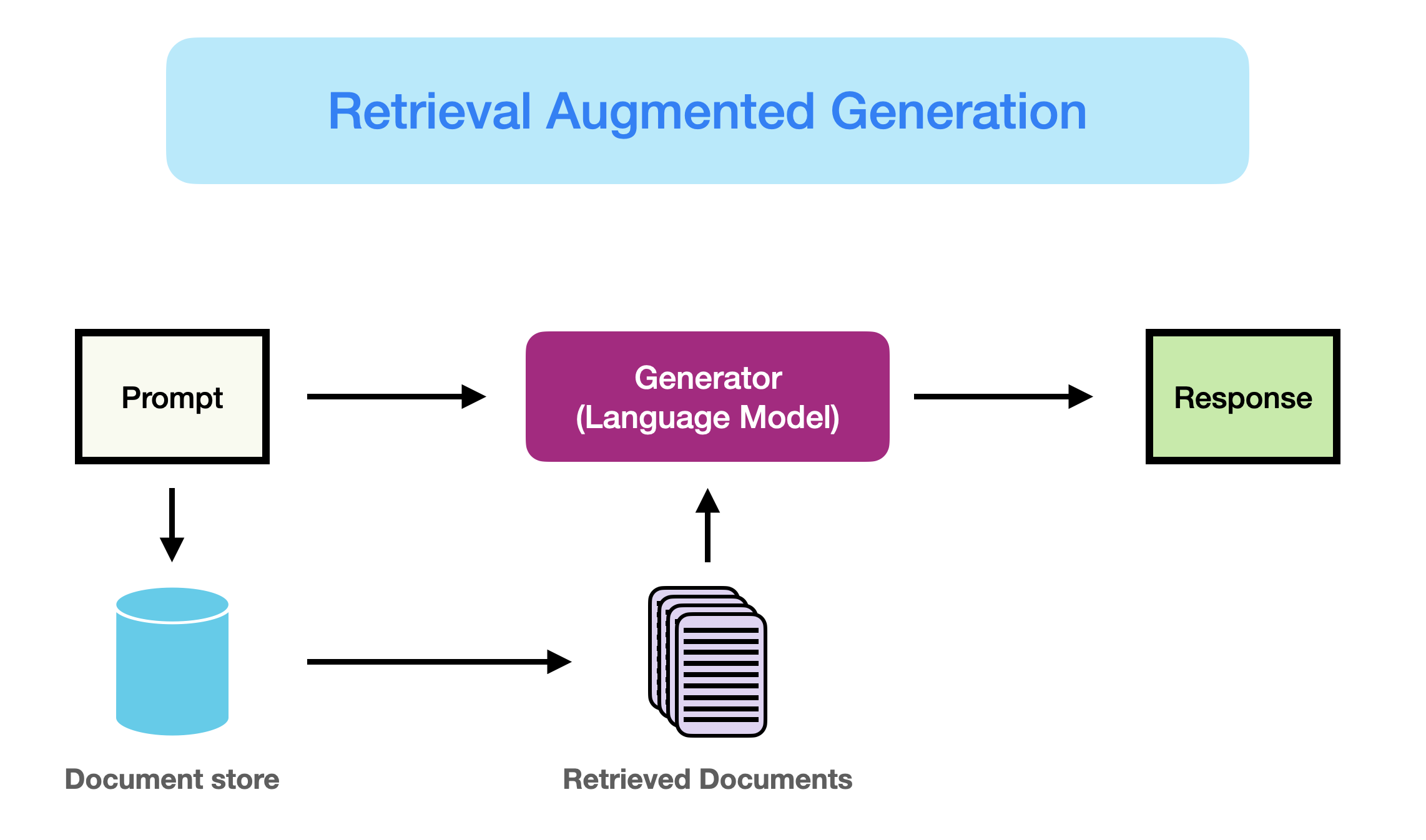
<그림1: RAG 구조. 출처: Prompt Engineering Guide https://www.promptingguide.ai/kr/research/rag >
이렇듯 LLM에 외부 지식(External knowledge)를 단서로 제시함으로써 응답의 정확도의 질을 높이는 방법은 수많은 연구, 기업에서 사용되고 있습니다.
이때 궁금한 점이 생깁니다. LLM이 학습할 때 사용된 내부 지식과, 추가로 제공된 외부 지식이 상충한다면 LLM은 어떠한 지식을 사용할까요? 결론부터 말하자면, 외부지식이 일관성 있고 설득력이 있다면 내부지식과 상충되는 관점이어도 외부지식을 받아들입니다. 외부 지식과 내부 지식이 일관성을 가진다면, 해당 지식을 지지하는 근거가 충돌하더라도 해당 지식에 대해 강한 확신, 확증편향을 가지게 됩니다.
오늘 리뷰할 논문, [Adaptive Chameleon or Stubborn Sloth: Revealing the Behavior of Large Language Models in Knowledge Conflicts]는 LLM의 지식 충돌(Knowledge Conflict)에 대해 통합적으로 연구한 첫 번째 논문입니다.
Introduction
거대한 코퍼스를 통해 사전학습을 마친 LLM은 내부적으로 상식을 포함하여 다양한 종류의 지식을 가지게 됩니다. 이를 지금부터 파라메트릭 메모리(parametric memory) 라고 표현하겠습니다. 그러나 이러한 지식들은 부정확하거나 시간이 지나 업데이트가 필요할 수 있습니다. 그러한 지식들은 환각 현상의 주 원인이 되기도 합니다. 이를 해결하기 위해 RAG 등의 외부 지식을 사용하는 기법이 등장하였지만, 외부 지식과 파라메트릭 메모리가 일치하지 않는 경우가 발생하였습니다. 이때 충돌의 원인이 되는 외부 지식을 카운터 메모리(counter-memory) 라고 표현하겠습니다.
해당 논문에서는 지식 충돌이 일어났을 때 벌어지는 일을 명확히 밝히고자 파라메트릭 메모리에 대응하는 카운터 메모리를 구축하는 프레임워크를 만들었습니다.
Framework
closed-book QA: 질문 혹은 지문이 주어지는 것이 아닌, 모델이 자체적으로 가지고 있는 능력에 기반하여 정답을 찾는 것을 의미합니다.

기반 데이터셋은 엔티티 기반의 데이터셋인 POPQA(https://huggingface.co/datasets/akariasai/PopQA)와 Multi-step reasoning 데이터셋인 STRATEGYQA(https://huggingface.co/datasets/voidful/StrategyQA)를 사용하였습니다.
새로운 데이터셋을 만드는 과정을 구체적으로 살펴보겠습니다.
1. 질문에 대해 모델은 가지고 있는 지식에 기반한 대답(Memory Answer)을 생성합니다. 이때 이 대답을 생성할 때 증거로 사용된 내용, 즉 파라메트릭 메모리를 만듭니다.
2. Memory Answer의 내용을 지식 충돌이 일어날 수 있는 내용(Counter Answer)으로 만듭니다. 예를 들어 해당 논문에서는 Google DeepMind의 리더를 Demis Hassabis에서 Jeff Dean으로 변경했습니다. 이후 Counter Answer을 설명하는 증거, 카운터 메모리를 만듭니다.
3. 만들어진 파라메트릭 메모리와 카운터 메모리가 각각 대응하는 응답을 잘 설명하는지 결정하기 위해 당시 NLI Task에서 SOTA를 달성한 DeBERTa-V2를 사용하였습니다. 추후 실험의 신뢰성을 위해 오직 잘 설명하는 메모리만을 사용하였습니다. (참고로 해당 모델이 잘 수행하는지 확실히 하기 위해 랜덤으로 200개의 예시를 뽑아 테스트해 본 결과, 99%의 정확도를 달성했다고 합니다.)
4. 추출한 파라메트릭 메모리가 정말로 LLM의 내부적 믿음에서 나온건지 확인하기 위해, 동일한 질문을 LLM에게 한 번 다시 던졌다고 합니다. 예를 들어 Google DeepMind의 리더를 물어봤을 때, Demis Hassabis라고 동일하게 답했는지 확인해보았습니다. 만약 일치하지 않았다면 해당 데이터를 제외하였습니다.
최종적으로 만들어진 데이터셋의 형태는 다음과 같습니다.

Experiments
카운터 메모리만 증거로 제시되었을 때
카운터 메모리를 만드는 2번 과정에 대해 논문에서는 두 가지 방법을 제시했습니다. 첫 번째 방법은 '엔티티 대체 기반'방법입니다. (우리가 Figure 1에서 본 카운터 메모리 생성방법은 두 번째 방법을 따릅니다)
엔티티 대체 방법(entity substitution-based counter memory method)
해당 방법에서는 문장 구조에서 특정 엔티티(문장 구성요소라고 생각해주세요)를 정한다음, 동일한 요소를 가지는 랜덤한 엔티티로 대체시키는 방법입니다. 예를 들어 아래와 같은 파라메트릭 메모리가 있다고 가정해보겠습니다.
증거: 미국의 수도인 워싱턴 D.C.는 워싱턴 기념탑을 가지고 있습니다.
질문: 미국의 수도는 어디인가요? ChatGPT 답변: 워싱턴 D.C. 입니다.카운터 메모리를 만들기 위해 증거 문장에서 '워싱턴 D.C.'라는 엔티티를 다른 수도로 변경하는 것입니다.
증거: 미국의 수도인 런던은 워싱턴 기념탑을 가지고 있습니다.
질문: 미국의 수도는 어디인가요? ChatGPT 답변: 워싱턴 D.C. 입니다.그런데 문제가 생겼습니다. 증거를 명확하게 변경하여 제시했음에도 불구하고, LLM이 답변을 생성할 때 파라메트릭 메모리에 의존하여 답변을 생성합니다. 이러한 문제는 더 큰 파라미터를 가지고 있는 모델에서 두드러지게 나타나는 것을 확인할 수 있었습니다.
응답-기반 방법(generation-based method)
Figure 1에서 설명한 방식입니다. 단계는 다음과 같습니다.
1. 질문에 대해 모델은 가지고 있는 지식에 기반한 대답(Memory Answer)을 생성합니다. 이때 이 대답을 생성할 때 증거로 사용된 내용, 즉 파라메트릭 메모리를 만듭니다.
2. Memory Answer의 내용을 지식 충돌이 일어날 수 있는 내용(Counter Answer)으로 만듭니다. 예를 들어 해당 논문에서는 Google DeepMind의 리더를 Demis Hassabis에서 Jeff Dean으로 변경했습니다. 이후 Counter Answer을 설명하는 증거, 카운터 메모리를 만듭니다.
LLM은 이렇게 만들어진 일관성 있는 카운터 메모리를 매우 잘 받아들인다고 합니다.
실험 결과
아래 실험은 여러 모델들의 응답의 결과가 Memory Answer인지 Counter Answer인지 측정해본 결과입니다.

Subs는 entity substitution-based 방식(일관성이 부족한 증거)으로 만들어진 카운터 메모리를 사용한 것이고, Gen은 generation-based 방식(일관성이 충분한 증거)으로 만들어진 카운터 메모리를 사용한 방식입니다.
위 실험 결과를 통해 다음의 결론을 얻을 수 있습니다.
1. LLM은 일관성 있는 외부 증거를 매우 잘 받아들인다.
2. 카운터 메모리로 인해 만들어진 답변은 LLM을 잘못된 답변으로 이끈다. 즉, LLM은 역정보(disinformation)에 취약하며 쉽게 받아들인다.
다양한 증거가 동시에 제시되었을때
여러 개의 증거가 동시에 제공되었을 때는 어떨까요? 검색 엔진과 같은 툴로 증강된 LLM을 생각해보면 다양한 출처에서 정보를 가져오므로 이런 종류의 지식 충돌이 자주 발생할 가능성이 있습니다. 분석 결과는 다음과 같습니다.
1. LLM은 인기 있는 정보에 대해서 내부 지식을 사용한다.
 위 실험결과에 따르면 인기 있는 정보에 관해 판단할 때는 기존 기억을 사용하는 비율이 훨씬 높다고 합니다. 특히 GPT-4의 경우 80%에 가까운 내부 지식 사용률을 보였습니다. 즉, 인기 있는 정보는 파라메트릭 메모리를 사용하는 비중이 매우 높다고 판단할 수 있습니다. 이는 사전 학습 중 인기 있는 엔티티에 관한 정보를 더 자주 접했기 때문이라고 생각합니다.
위 실험결과에 따르면 인기 있는 정보에 관해 판단할 때는 기존 기억을 사용하는 비율이 훨씬 높다고 합니다. 특히 GPT-4의 경우 80%에 가까운 내부 지식 사용률을 보였습니다. 즉, 인기 있는 정보는 파라메트릭 메모리를 사용하는 비중이 매우 높다고 판단할 수 있습니다. 이는 사전 학습 중 인기 있는 엔티티에 관한 정보를 더 자주 접했기 때문이라고 생각합니다.
2. 증거가 제공되는 순서가 LLM의 응답에 영향을 미친다.
 위 실험결과에 따르면 첫 번째 증거로 어떤 메모리가 제공되는지에 따라 내부 지식을 사용할지, 외부 지식을 사용할 지 영향을 미친다고 합니다.
위 실험결과에 따르면 첫 번째 증거로 어떤 메모리가 제공되는지에 따라 내부 지식을 사용할지, 외부 지식을 사용할 지 영향을 미친다고 합니다.
3. LLM은 더 많은 증거를 가진 메모리를 선택한다.
 증거의 비율이 높아질수록 LLM이 해당 메모리를 따를 가능성이 높아집니다. 예를 들어 파라메트릭 메모리와 일치하는 증거가 67% 이상일 때, 대부분의 모델이 이를 따르는 답변을 생성했다고 합니다. GPT-4의 경우 카운터 메모리를 받아들이는 경향이 특히 더 낮았습니다.
증거의 비율이 높아질수록 LLM이 해당 메모리를 따를 가능성이 높아집니다. 예를 들어 파라메트릭 메모리와 일치하는 증거가 67% 이상일 때, 대부분의 모델이 이를 따르는 답변을 생성했다고 합니다. GPT-4의 경우 카운터 메모리를 받아들이는 경향이 특히 더 낮았습니다.
4. LLM은 무관한 증거에 의해 방해받을 수 있다
 해당 실험에서는 무관한 증거가 제공될 때 LLM의 응답을 조사했습니다.
1. 무관한 증거만 제공된 경우: LLM은 무관한 답변을 생성합니다. 이는 Llama2-7B에서 두드러지게 나타나고 있습니다.
2. 관련 및 무관한 증거가 동시에 제공된 경우: 대부분의 LLM은 무관한 증거를 어느정도 필터링 할 수 있지만, 무관한 증거가 많아질수록 필터링 능력이 감소합니다. 이는 Llama2-7B에서 두드러지게 나타나고 있습니다.
해당 실험에서는 무관한 증거가 제공될 때 LLM의 응답을 조사했습니다.
1. 무관한 증거만 제공된 경우: LLM은 무관한 답변을 생성합니다. 이는 Llama2-7B에서 두드러지게 나타나고 있습니다.
2. 관련 및 무관한 증거가 동시에 제공된 경우: 대부분의 LLM은 무관한 증거를 어느정도 필터링 할 수 있지만, 무관한 증거가 많아질수록 필터링 능력이 감소합니다. 이는 Llama2-7B에서 두드러지게 나타나고 있습니다.
Conclusion
해당 논문에서는 올바르지 않은 외부 증거를 사용할 때 모델의 응답 경향을 측정했습니다. 그 결과 다음의 결론을 얻을 수 있습니다.
- 확인 편향: LLM은 내부 메모리와 일치하거나 인기 있는 정보를 선호하는 경향이 있습니다.
- 순서 민감성: 증거의 순서가 LLM의 응답에 영향을 미칠 수 있습니다.
- 다수 증거 효과: LLM은 더 많은 증거를 가진 쪽을 선택하는 경향이 있습니다.
- 무관한 증거 영향: LLM은 무관한 증거에 의해 혼란을 겪을 수 있으며, 이를 필터링하는 능력이 제한적입니다.
또한 올바르지 않은 외부 증거가 일관성 있을 때 해당 증거를 매우 잘 받아들인다는 점과, LLM이 역정보에 취약하다는 점 또한 파악할 수 있었습니다.
이 글이 여러분에게 도움이 되었으면 좋겠습니다 :)
