- 본 포스팅은 2022 데이터 크리에이터 캠프에 참가하여 배운 내용과 느낀 점을 정리한 글입니다.
- 👉
Click
- DAMS (Data Analysis Math Statistics) 팀 최우수상 🎉🎉 감사합니다 👍👍
데이터 크리에이터 캠프란?
-
데이터 크리에이터 캠프는 실제 비즈니스 환경의 문제를 데이터 분석 교육 및 멘토링을 통해 해결해 보는 데이터 분석대회입니다. -
온라인 사전 학습을 제공하고 4주간의 해커톤 예선을 진행하는데 이때, 매주 멘토님에게 튜터링을 받을 수 있는 기회를 제공합니다.
-
과학기술정보통신부와 한국지능정보사회진흥원이 주최하며 약 2달 동안 진행됩니다.

신청하게 된 이유
- 평소 저는 캐글/데이콘과 같은 머신러닝의 예측 성능을 높이는 대회에 참여해왔습니다. 리더보드에서 알 수 있는 등수와 별개로 제가 사용하는 모델과 방법론들을 이 문제에 사용하는 것이 타당한지, 옳은 근거인지가 매번 궁금했었는데요, 그렇기에 데이터 크리에이터 캠프에서 매주 멘토링을 제공한다는 점이 매력적이었습니다.
- 무엇보다도 잘 맞는 친구들과 한 달 넘게 같이 팀 프로젝트를 할 기회가 앞으로는 거의 없을 것 같아서 신청했습니다! 😀😀
진행 방식
1. 온라인 연수원을 통한 사전 학습
- 전반적인 인공지능 역사부터 머신러닝/딥러닝 개념까지 학습할 수 있는 온라인 강의를 제공합니다.
2. 예선 문제 해결하기
-
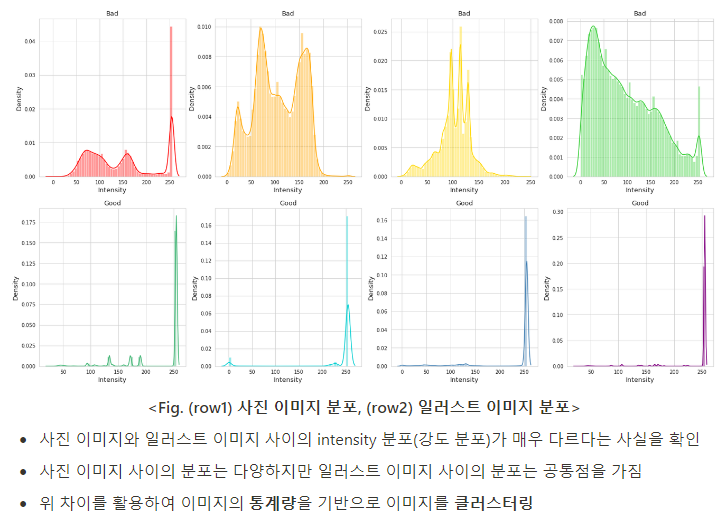
예선 문제는 아래와 같이 크게 세 가지로 나눠 집니다. 일러스트와 실사가 섞인 이미지 데이터를 제공받았습니다.
- EDA 과정을 통해 데이터 분포 문제 해결하기.
- 학습 데이터에서 실사 영상 제거하기 (비지도 학습).
- 일러스트 영상 분류하기 (지도 학습).
-
저희 팀은 일주일에 두 번 정도 회의를 진행했는데요, 회의 때 역할 분담을 하고 다음 회의에서 분석 결과를 공유하는 식으로 진행했습니다.
-
Notion 페이지를 활용하여 회의 내용 및 진행 상황을 팀원들과 공유하고, 멘토링을 위한 발표 자료를 기록했습니다.
- 아래와 같이 진행 상황과 모델 학습계획을 정리했습니다.

-
주최 측에서 Colab Pro 환경을 제공 해주셔서 더 편하게 모델링 할 수 있었습니다.
-
마지막으로 소스 코드와 PPT, 최종 모델 가중치를 제출했습니다.
- 제출 일주일 전 최종 모델을 채점할 때 사용하는 테스트 코드를 주최 측에서 제공해 주시는데요, 저희 팀에서 테스트 코드 오류를 먼저 발견하고 오류 레포트를 작성하여 주최 측에 보냈습니다. 😂😂
- 다행히도 오류가 맞아서 수정된 코드를 다시 받았습니다. 사실 저희가 틀린 것 같아서 조마조마 했었는데, 지나고 보니까 더 다양한 실험과 시도를 해보게 된 것 같아 저희 팀을 더 성장하게 해준 일이었던 것 같습니다 :)
3. 멘토링 활용하기
-
매주 토요일마다 담당 멘토님에게 미션을 수행하면서 궁금했던 점을 질문했습니다.
-
Notion 페이지에 궁금한 점도 따로 적어두고 질문했습니다 :)

- 발표 잘 들어주시고 좋은 피드백 해주신 조희승 멘토님! 감사드립니다 😀😀
- 멘토링 데이 외에도 매일 QnA 게시판에 질문 하나 씩 할 수 있어서 유용하게 활용했습니다.
4. 본선
- 예선 일주일 후 본선 진출 팀임을 공지 받았습니다. 🎉🎉

-
마지막으로 발표 자료와 대본을 점검하고, 예상 질문 및 모델 개념을 공부했습니다.
-
특정 방법론과 모델을 활용한 근거와 구체적인 학습 방법을 위주로 정리하여 발표 디펜스를 대비했습니다.
➔ (EX) L2정규화와 드롭아웃을 통해 과적합이 어느정도 보완되었나요?, 왜 기존 VGG16보다 새로 제안한 모델이 더 빠르게 수렴되나요?
-
학습 데이터에서 실사 영상을 제거할 때 Self supervised learning 을 활용했는데요, 이에 대한 survey 논문을 정리하여 팀원들에게 공유하고 함께 공부했습니다.
-

- 본선은 한국지능정보사회진흥원 스마트 스퀘어에서 오후 1시에 시작했습니다. 발표 순서는 당일 추첨으로 결정됐고, 저희는 대학부 7번째로 발표했습니다 :)


- 발표 시간은 5분으로 짧았지만 다행히 발표자 친구가 모든 내용을 잘 발표해 주었습니다. 😂😂 발표가 끝나면 팀원들 전체가 무대 위로 올라가서 심사위원 분들께 질문을 받게 되는데, 운좋게도 예상 질문을 벗어난 질문이 없었기에 논리적으로 잘 대답했던 것 같습니다.
- 5시 정도에 시상식이 진행되었는데 정말 너무 떨리더라구요.. DAMS 팀은 최우수상을 수상하게 되었습니다! 감사합니다 🥳🥳

배우고 느낀 점
-
먼저 멘토링을 통해 많이 배웠습니다. 어떤 문제를 풀기 위해 내가 생각하는 방법론을 제안해야할 때, EDA와 모델링 실험 결과를 근거로 들어 설득하는 법을 배웠습니다.
-
최종 발표 내용에는 포함하지 않았지만, 사실 캠프를 진행하면서 해본 시도가 굉장히 많았습니다. 이러한 시도들을 통해 더 많이 배우게 된 것 같습니다.
(WARD, DBSCAN, K-means, CAE, Segmentation, AnoGAN, Efficientnet, ConvNext, Resnet, Desnet ...)
-
어쩌다 보니 제가 Self supervised learning 부분을 도맡아 하게 됐는데요, 덕분에 많이 배웠고 흥미로워서 추후에 여유가 되면 다른 대회에도 활용해볼까 고민 중입니다.
-
이렇게 해보면 좋지 않을까? 라고 막연하게 생각했던 것들을 직접 하나하나 시도해 보면서 지식으로 적립되었네요 :)
후기
- 열심히 준비해주신 운영진분들 덕분에 몇 달 동안 부담없이 편하게 참가했습니다. 무엇보다도 상을 받게 되어 더 뿌듯하고 즐거웠습니다! (다른 task의 문제로 캠프가 또 열리면 좋겠습니다!)
- 팀원 분들에게도 감사합니다! 두 달 동안 즐거웠고 너무 좋은 팀워크를 느낄 수 있었습니다 😀😀
