1계 도함수법은 현재 위치에서의 기울기를 이용해 최적해를 찾는다. 이때 반복적인 작업을 통해 최적해를 찾아나가게 된다. 이번에 다룰 내용은 기본적인 그래디언트 디센트부터 딥러닝 옵티마이저로 자주쓰이는 Adam 등, 매우 자주 접하게 되는 최적화기법들이다.
1. Gradient Descent
이전에도 다룬바 있지만 흐름 상 간단히 짚고 넘어가자. 그래디언트 디센트는 현재 시점에서 그래디언트 디센트 를 선택하여 해당 방향으로 이동하는 것이다. 이때 목적함수가 스무스하고, 이동의 크기인 스텝이 작고, 그래디언트가 0인 stationary point에 도달하지 않은 상태에서 그래디언트 디센트 가 가장 경사가 가파른 하강 방향임을 보장하게 된다. 이때 는 그래디언트 의 반대방향으로 찾을 수 있다.
즉 시점에서 지점 에서 가장 경사가 급한 방향 그래디언트 디센트는 다음과 같이 찾는다.
이때 이렇게 찾은 값은 너무 그 크기가 커서 overshooting이 발생할 우려가 있으므로 다음과 같이 정규화하여 사용하게 된다.
여기서 재밌는 점은 의 값이 최대한 줄어들도록 스텝 크기를 설정하면 다음 시점의 방향과 현재 시점의 방향은 항상 직교하여, 전체적인 경로는 아래와 같이 지그재그꼴이 된다는 것이다.
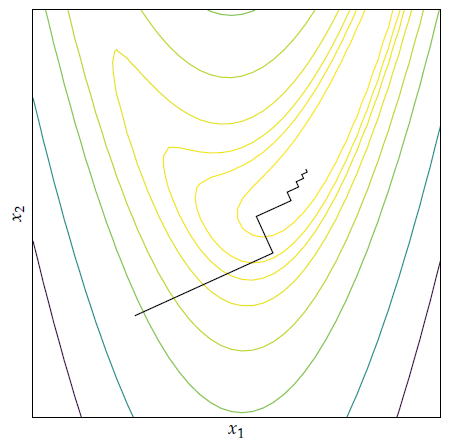
이는 다음과 같이 보일 수 있다.
증명
목적함수 가 있고, 현재 시점 에서 최적의 스텝을 설정한다면 다음과 같을 것이다.
이때 위의 식은 결국 시점에서 로 이동하면 해당 지점에서 을 의미한다. 이를 풀어쓰면 다음과 같다.
그런데 우리는 다음 식 역시 알고 있으므로 자연스레 다음과 같은 전개가 가능하다.
코드
class gd:
def __init__(self, lr = 0.001):
self.lr = lr
def update(self, params, grads):
for key in params.keys:
params[key] = params[key] - grads[key]*self.lr2. Momentum
그래디언트 디센트의 가장 큰 단점 중 하나는 stationary point를 통과하는데 무척이나 오랜 시간이 걸린다는 점이다. 논문들에서 plateau라고도 표현되는 이 지점들은 그래디언트의 크기가 매우 작아 조금씩 이동하게 된다. 이를 물리학의 관성 개념을 도입하여 이전의 관성에 따라 빠르게 통과하도록 한 것이 모멘텀이다. 식은 다음과 같이 구성된다.
이때 와 모두 하이퍼파라미터이며, 으로 설정된다.
즉, 이전 시점들의 그래디언트를 일정 비율로 더하여 관성으로 삼는 것이다. 이때 이면 그래디언트 디센트와 동일한 식이 된다. 관성을 통해 stationary point에 근접하더라도 이전의 그래디언트들의 영향을 빠르게 통과할 수 있게 된다. 즉, 좀더 전체적인 방향을 유지하도록 관성이 이끌어준다고 볼 수 있을 것이다.
코드
class momentum:
def __init__(self, lr, beta = 1, alpha = 0.9):
self.lr = lr
self.beta = beta
self.alpha = alpha
self.momentum = 0
def update(self, params, grads):
for key in params.keys:
self.momentum = self.momentum*self.beta - self.alpha*grads[key]
params[key] = params[key] + self.momentum3. Nesterov momentum
모멘텀이 stationary point를 빠르게 지나가기는 하지만, 골짜기를 지날 경우에는 여전히 진동하면서 움직이고, 그 관성으로 인해 최적해를 지나칠 우려가 있다. 이를 개선하고자 네스테로프 모멘텀이 등장하였다. 수식부터 살펴보자
모멘텀과 달라진 부분은 현재의 그래디언트 대신에 를 이용한다는 점이다. 즉, 모멘텀은 현재 지점의 그래디언트를 관성에 빼주지만, 네스테로프 모멘텀은 미리 이동해보고 그 지점의 그래디언트를 이용한다.
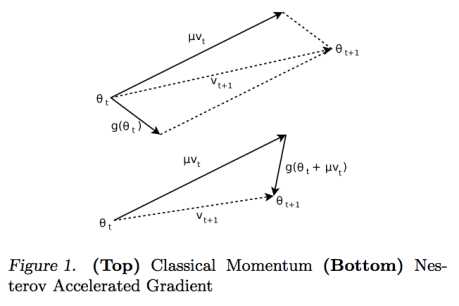
그 이유는 위의 그림을 통해 조금 더 알 수 있는데, 어쨋든 미리 가본 지점의 그래디언트가 최적해로 가는 데 좀 더 신뢰할 수 있는 그래디언트이기 때문이다. 즉, 위의 그림에서 가 현재까지의 모멘텀이고, 가 현재 지점의 그래디언트, 가 미리 가본 지점의 그래디언트 인데, 이를 통해 좀 더 믿을만한 방향으로 이동할 수 있게 되는 것이다.
코드
class nesterovM:
def __init__(self, lr, b, a):
self.lr = lr
self.b = b
self.a = a
self.momentum = 0
def update(params, grads, f, x):
for key in params.key:
delta = get_delta(f(params[key] + grad[key]))
self.momentum = self.b*self.momentum - self.a*delta
params[key] = params[key] + self.momentum 4. Adagrad
모멘텀은 방향에 집중하고 있다. 즉, 어떻게 하면 빠르게 최적점을 찾아갈 수 있는지 옳바른 방향을 찾고자 하는 것이다. 하지만, 그래디언트 디센트 방법론들은 방향만큼이나 스텝의 크기도 중요하다. 그래디언트 디센트나 모멘텀 모두 골짜기에서 진동하면서 이동하기 때문에 수렴하는데 오랜 시간이 걸린다고 했다. 이는 골짜기에서 해당 방향으로의 이동은 맞지만, 너무 많이 이동해서 문제가 되는 것이라고 생각할 수 있을 것이다. 즉, 그래디언트에서 각 원소들이 필요한 스텝의 크기만 이동할 수 있다면 문제가 해결될 것이다. 아다그라드는 이러한 접근을 취하고 있다.
위의 식이 파라미터 하나에 대한 업데이트 식이다. 즉, 아다그라드는 벡터를 통채로 연산하지 않고, element wise하게 연산하게 된다. 이때 는 이전 시점들의 해당 원소에 대응하는 그래디언트 원소값이다.
위의 식을 다시 벡터 형태로 표기하면 다음과 같다.
아다그라드는 치명적인 약점이 있는데, 계속해서 제곱합을 한 로 학습률을 나눠주다보니, 특정 원소에 대응하는 그래디언트가 너무 큰 값을 계속 가질 경우 어느 시점부터 더이상 유의미하게 업데이트되지 않는다는 점이다. 이 지점이 너무 빨리 오면 수렴하기도 전에 최적화 과정이 종료된다.
코드
class adagrad:
def __init__(self, lr):
self.lr = lr
self.s = 0
def update(self, params, grad):
self.s += grad^2
for key in params.keys:
params[key] = params[key] - self.lr*grad[key]/(0.00000001 + sqrt(self.s[key]))5. RMSProp
Adagrad에서 제곱을 누적합하는 것은 필연적으로 계속하여 를 증가하게 만들고 이것이 가중치가 업데이트되지 않도록 하는 문제점이었다. 그렇다면 의 값이 일정하게 유지되도록하면 문제가 해결되지 않을까? RMSProp은 이러한 접근법을 택하고 있다.
에 대한 식을 살펴보자.
여기서 는 의 값으로 보통 정도로 잡는다고 한다. 즉, 를 통해 의 값이 커지지 않고, 번째 그래디언트가 추가되도록 만들고 있다. 이를 그래디언트 디센트 전체 식에 대입하면 다음과 같다.
여기서 이름의 기원이 나오는데 그냥 Root Mean Squared of S라서 RMS라고 붙인 것이다.
코드
class RMSProp:
def __init__(self, lr, gamma):
self.lr = lr
self.gamma = gamma
self.s = 0
def update(self, params, grads):
self.s = self.gamma*self.s + (1-self.gamma)*grads^2
for key in params.keys:
params[key] = params[key] - self.lr*grads[key]/(0.00000001 + self.s[key]6. Adadelta
아다델타는 이전에 소개한 그래디언트 디센트, 모멘텀과 아다그래드에서 의 단위와 의 단위가 역수 관계라는 점에 집중한다.
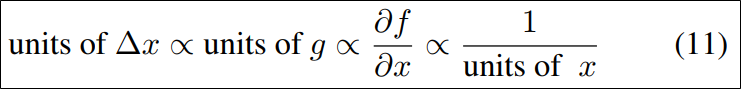
위에서 볼 수 있듯이 는 와 역수의 단위를 가지고 있다. 이게 문제점이라고 지적하는데, 이를 개선하고자, 뉴턴법을 이용하여 아래와 같은 관계를 만든다고 한다.
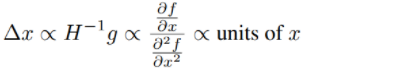
뉴턴법에 대해서는 다음 장에서 배울 예정이므로 일단 넘어가자.
아다델타는 전반적으로 RMSProp과 비슷하다. 다른점은 학습률역시 RMS로 바꿧다는 점인데 자세한 수식은 아래와 같다.
코드
class Adadelta:
def __init__(self, lr, gamma1, gamma2):
self.lr = lr
self.gamma1 = gamma1
self.gamma2 = gamma2
self.s = 0
self.deltas = 0
self.epsilon = 0.0000000001
def update(self, params, grads):
self.s = self.gamma1*self.s + (1-self.gamma1)*grads^2
self.deltas = self.gamma2*self.deltas + (1-self.gamma2)*self.s^2
for key in params.keys:
params[key] = params[key] - (sqrt(self.deltas)/(self.epsilon + sqrt(grads[key]))*grads[key]7. Adam
가장 표준적으로 쓰이는 옵티마이저는 아마 아담일 것이다. 대부분의 논문에서 아담을 기준으로 성능을 평가하고 있을 정도이다. 아담은 RMSProp, Momentum를 종합하여 사용한다. RMSProp처럼 스텝의 크기를 각 원소마다 조절하여 너무 큰 그래디언트의 영향을 과하게 받지 않도록 하고, Momentum처럼 과거의 그래디언트를 저장하여 관성으로 작용하도록 한다.
수식은 다음과 같이 구성되어 있다.
즉, 여기서 는 Momentum처럼 이전의 그래디언트에 대해 이동지수평균과 같이 작동하여 관성을 가지도록 하고, 는 RMSProp처럼 각 원소의 그래디언트가 너무 커지면 해당 원소의 스텝 크기를 적정하게 줄여주어 적절히 이동하도록 만들어 준다. 이때, 로 설정한다고 한다.
코드
class Adam:
def __init(self, lr, g1=0.9, g2=0.999):
self.lr = lr
self.g1 = g1
self.g2 = g2
self.epsilon = 0.0000000001
self.v = 0
self.s = 0
def update(self, params, grads):
self.v = self.g1*self.v + (1-self.g1)*grads
self.s = self.g2*self.s + (1-self.g2)*(grads^2)
for key in params.keys:
params[key] = params[key] - self.lr*self.v/(sellf.epsilon + sqrt(self.s))위의 모든 코드들은 파이썬 형식으로 작성된 수도코드이다. 리스트와 스칼라가 연산되는 등 어색한 부분이 있지만, shape만 맞춰주면 되는 부분이기 때문에 큰 무리는 없다고 생각한다.
참고
텐서플로우 공식 블로그
PRML 번역 사이트
