논문 선정이유
LLM-as-Agent를 체계적으로 평가할 표준 벤치마크 부재.
기존 벤치마크 한계
-
텍스트 기반 게임 환경
: closed, discrete action spaces 한계
협소한 상식 추론 위주. -
멀티모달 시뮬레이터(게임·GUI·실내 환경)
: 실제 LLM 사용 사례를 반영하지 못함,
멀티모달 복잡성 때문에 text-only LLM 평가에는 부적합.
현재 대부분의 벤치마크는 single environment만 다루며,
다양한 애플리케이션 시나리오에서 평가 불가.
AgentBench
목표: 다양한 실제 시나리오에서 LLM-as-Agent 능력을 표준화해 평가.
8가지 환경
- Code 기반 : OS(Bash), Database(MySQL), Knowledge Graph(Freebase)
- Game 기반: Digital Card Game, Lateral Thinking Puzzles, House-Holding Simulator
- Web 기반: Web Shopping, Web Browsing
데이터셋
모든 데이터셋을 텍스트 인터페이스로 바꿔서 LLM이 "에이전트처럼" 과제들을 수행하도록 설계
평가 역량
- following instructions
- coding
- knowledge acquisition
- logical reasoning
- commonsense grounding
LLM-AS-AGENT: DEFINITION AND PRELIMINARY
정의: LLM-as-Agent 상호작용 평가
LLM을 에이전트로 평가하는 과정은 POMDP로 볼 수 있음.
LLM agent()은 환경과 상호작용하며 상태 변화와 보상을 통해 평가됨.
추론 전략 (Reasoning Strategies)
에이전트로 작동하려면 강한 추론 능력이 필요.
Chain-of-Thought (CoT) 사용
: AGENTBENCH는 개선된 기법(ensemble, reflection, search 등)을
쓰지 않고, CoT만 적용해 평가.
Finish Reasons
LLM 에이전트의 AGENTBENCH task 종료 사유를 5가지 유형으로 분류
-
Context Limit Exceeded (CLE)
interaction history 길이가 LLM 최대 컨텍스트 길이를 초과함. -
Invalid Format (IF)
출력이 지시된 포맷을 따르지 않음.
주로 지침 준수 능력 부족 때문. -
Invalid Action (IA)
포맷은 맞췄지만, 선택한 행동이 유효하지 않음.
(예: 없는 API 호출, 잘못된 명령 실행) -
Task Limit Exceeded (TLE)
정해진 최대 턴 수 안에 문제 해결 실패, 혹은 같은 출력을 반복함.
주로 멀티턴 과제 처리 능력 부족을 시사. -
Complete
정상적으로 과업을 마침.
COMPOSITION OF AGENTBENCH: A BRIEF LOOK
AGENTBENCH는 Chain-of-Thought(CoT) 프롬프팅을 기반으로
- Code-grounded
- Game-grounded
- Web-grounded
세 가지 유형 환경에서 성능 평가.
특정 태스크에 특화된 모델이 유리하지 않도록, 다양한 시나리오 제공.
Code-grounded Environments (코드 기반 환경)
1. Operating System (OS)
LLM이 터미널에서 운영 체제(OS)에 접근하고 조작할 수 있는지 평가
환경: Ubuntu Docker bash 환경에서 실제 OS 명령 실행.
샘플 구조
각 평가 샘플은 다음 요소를 포함:
- Instruction: 자연어로 된 문제 설명
- Docker Environment: 시작할 도커 이미지
- Initialization Script (옵션): 초기 환경 설정용 bash 스크립트
- Start Script (옵션): shell 생성 직후 실행되는 스크립트
- Checking Pipeline: 정답/정상 실행 여부를 확인하는 검증 방법
- Example Script (옵션): 정답 예시로 쓸 수 있는 참고 스크립트
태스크 유형
- QA (Question Answering)
특정 질문에 답하기 위해 명령 실행 - Operation
시스템 상태를 변경하는 작업 수행
OS 평가 데이터셋 수집 과정
-
인간 생성 문제 (50%)
Stack Overflow에서 문제 수집.
문제 설명, 초기화 스크립트, 검증 방식 등을 직접 작성 -
GPT-4 생성 문제 (50%)
그대로 쓰지 않고 유닛 테스트를 통해 걸러냄 : 초기화 스크립트가 정상 실행되는지, 예시 코드가 실제로 정답을 맞추는지 확인.
조건을 통과하지 못한 문제는 제외
최종 데이터셋
각 문제는 실제 도커 환경 + 인터랙티브 셸 + 검증 스크립트 포함
1-shot Chain-of-Thought(CoT) 프롬프팅 방식 사용
<USER>:
{{ INSTRUCTION }}
Now, my problem is:
Tell me how many files are in the directory "/etc"?
<AGENT>:
Think: To count the files in /etc, I need to print all the files in
it.
Act: bash
‘‘‘bash
ls /etc
‘‘‘
<USER>:
The output of the OS:
cpi cron.hourly fuse.conf iproute2 lvm networkd-dispatcher protocols
selinux tmpfiles.d [truncated because the output is too long]
<AGENT>:
Think: The output has been truncated because it is too long, so I
need to count files by script directly.
Act: bash
‘‘‘bash
ls -1 /etc | wc -l
‘‘‘
<USER>:
The output of the OS:
220
<AGENT>:
Think: Now I get the answer, it is 220.
Act: answer(220)
<USER>:
Now, I will start a new problem in a new OS. My problem is:
{{ PROBLEM }}
<LOOP>:
<AGENT>:
{{ RESPONSE }}
Swicth AGENT.Action:
"bash":
<User>:
The output of the OS:
{{ OUTPUT }}
"answer" or "finish":
Executing Checking Script
Exit Loop
otherwise:
Exit Loop평가 절차 (Execution Setup)
Initialization
- 도커 컨테이너 생성 + 초기화 스크립트 실행
Interaction
- shell을 열고 Start Script 실행
- 모델이 Instruction을 받고 shell과 interaction 시작
- 매 턴마다
bash실행,answer제출 가능 - 최대 8턴 제한 → 초과 시 실패 처리
Checking
- Checking Pipeline = 스크립트 집합
- 스크립트의 실행을 위해,
모델 답변()과 이전 실행 결과들을 모두 입력받아 검증. - 모든 스크립트가 정상 종료(exit code 0) 시 정답으로 간주
평가지표
- Success Rate (SR) : 문제 해결 성공 여부 (0 = 실패, 1 = 성공)
2. Database (DB)
기존 연구들은 개별 절차만 다루고, 전체 SQL 작업 파이프라인을 다루기 않음.
DB 데이터셋 구성
-
기존 SQL 관련 QA 데이터셋들을 재사용·통합:
WikiSQL, WikiTableQuestions, SQA, HybridaQA, FeTaQA -
GPT-3.5-turbo 활용하여 Data Augmentation
샘플 구조
- Instruction: 자연어 문제 설명
- Table Info: 테이블 이름과 컬럼 설명
- Table Content: 실제 데이터 (DB 생성용)
- Correct Answer:
Select 유형 → 정답 텍스트
Insert/Update 유형 → 정답 SQL 실행 후 테이블의 해시값
평가 절차 (Evaluation Setup)
Initialization
- 테이블 내용 기반 SQL 스크립트 작성
→ MySQL DB를 도커 컨테이너에서 초기화
Interaction
- 프롬프트로 SQL 실행 지시 + 추론 과정 요구
- Agent는 SQL 쿼리 반환 → 실행 → 결과 반환 → 최종 답 제출
Checking
- Select 유형 → 표준 정답과 비교 (순서는 무시, 숫자 표현 차이 허용: 5 = "5.0" = "+5")
- Insert/Update 유형 → 결과 테이블의 해시값을 정답과 비교
평가지표
- Success Rate (SR)
세 카테고리(Select, Insert, Update)의 성공률을 매크로 평균
3. Knowledge Graph (KG)
KG 데이터셋 구성
- FREEBASE 기반 KBQA 데이터셋 활용
- LLM에게 전체 KG 지식을 설명하는 대신, API 형태의 KG 쿼리 tool을 제공
- 최소 5회 이상의 tool 호출이 필요한 질문들만을 선별
- 질문마다 미리 사람이 S-expression(논리식) 형태로 정답을 도출하는 최적의 액션 시퀀스를 정의
각 샘플 구성 요소
- Input Question: 자연어 질문
- Topic Entities: 질문에 언급된 주요 엔티티 (엔티티 링크 작업 불필요 → LLM은 long-term planning 에 집중)
- Action Sequence: 정답에 도달하는 툴 호출 시퀀스
- Gold Answer: 정답 (KG 엔티티 집합)
평가 절차 (Evaluation Setup)
Initialization
- LLM에 태스크 설명 + 사용 가능한 KG-query 도구 설명 제공
Interaction
- LLM이 다양한 툴을 호출해 필요한 정보 탐색
- 자율적으로(workflow를 스스로 계획) 진행
Final Answer Prediction
- LLM이 여러 변수(엔티티 집합)를 생성
그중 최종 정답이라고 판단되는 변수를 출력하고 종료
평가지표 (Metrics)
-
F1 Score: 예측된 답과 정답 집합의 정밀도·재현율 기반 평가
-
Exact Match (EM):
기존 연구: 논리식 형태(Logical Form) 기반 비교
AgentBench: 결과 집합 비교 (예측 엔티티 집합 vs 정답 엔티티 집합) -
Executability:
모델이 생성한 액션 시퀀스를 실제 KG에서 실행했을 때:
실행 가능(Executable) → 1점
실행 불가능(Not Executable) → 0점
Game-grounded Environments (게임 기반 환경)
일단 생략
Web-grounded Environments (웹 기반 환경)
1. Web Shopping (WS)
WS 데이터셋 구성
-
실제 웹사이트 환경을 텍스트로 단순화하여 제공
화면 = 텍스트 관찰(observation)
행동 = 클릭(click), 검색(search) -
아마존(Amazon)에서 약 100만 개 상품을 크롤링하여 DB 구축
각 상품에는 속성(attributes) 라벨이 붙음 -
사람으로부터 12,087개 구매 지시문(human instructions) 수집 → 목표(goal)과 expected attributes 연결
평가 절차 (Evaluation Setup)
Instructing
- 초기 prompt: 환경 정보 + 응답 형식 설명
- 이후 "어떤 제품을 사고 싶은지" 사용자 지시문 제공
Interacting
- Agent는 Think → Action 형식으로 응답
- Action 유형 2가지:
search: 상품 검색 (검색 엔진 활용)
click: 버튼 클릭 (상품 선택/상세 확인) - 환경은 에이전트의 행동에 대해 텍스트 기반 웹페이지와 클릭 가능한 버튼 목록 반환
- 반복 수행 → Agent가 "buy now" 버튼 누르거나 라운드 제한 초과 시 종료
Calculating Reward
- 최종 선택한 상품의 속성과 기대 속성 간 유사도 계산
- 결과는 0~1 사이 점수로 환산
평가지표 (Metrics)
한 쿼리에 대해 여러 적합한 상품이 있을 수 있음 → 단순 정답/오답 x
: 매칭 점수(Reward)를 계산
Reward 계산식
: 사용자의 목표(Goal)
: 선택한 상품(Product)
: 필수 속성(attributes)
: 선택 속성(options)
: TextMatch 기반 가중치
rtype 정의
TextMatch: 선택 상품 제목 vs 목표 상품 제목의 유사도
2. Web Browsing (WB)
WB 데이터셋 구성
Mind2Web
실제 웹사이트 환경을 반영한 대규모 웹 브라우징 태스크 데이터셋
사람 annotator가 특정 웹사이트를 보고 Task Goal을 정의
실제 웹 탐색 과정을 기록 → action trace 생성
각 샘플 구성 요소
-
Task Description: 구체적 절차 대신, 고수준 목표로 제시
ex. “평점 4 이상, 3~6시간짜리 중급 SAP S/4 HANA 강의를 찾아 장바구니에 담고 결제하라” -
Reference Action Sequence:
각 단계 ()의 메타 액션() 마다 = {}
: 대상(선택한) 요소의 backend ID
: 수행할 액션 (Click, Type, Select Options)
입력 필요 시 (ex. Type/Select) → 입력 텍스트 포함 기록 -
Webpage Information:
각 단계에서 현재 페이지 HTML 코드 + 과거 상호작용 기록(trajectory) 스냅샷 포함
문제: HTML이 너무 방대 → LLM이 처리에 어려움
해결: 소형 언어모델(DeBERTa)를 사용해 HTML 요소를 랭킹 & 필터링
→ 추론 효율 개선
평가 절차 (Evaluation Setup)
HTML 요소 후보 줄이기
- 방대한 HTML을 그대로 쓰지 않고, 소형 언어모델로 요소들을 랭킹.
- 상위 Top-k 요소만 남겨서 후보로 사용.
다지선다식 선택 (Multi-choice QA)
- 각 단계마다 LLM은 주어진 후보 중에서 대상 요소()를 선택.
- 총 5개의 선택지를 제공.
Type / Select Option 처리
- 클릭만 하는 게 아니라, Type(텍스트)이나 Select 값도 함께 예측해야 함.
평가지표 (Metrics)
Element Accuracy
- 선택한 요소()가 정답인지 정확도 측정.
Action F1
- 예측한 동작()이 얼마나 정답과 일치하는지 토큰 단위 F1 점수로 계산.
특히 Type, Select Option처럼 입력값이 있는 경우에 중요.
Success Rate
- Step Success Rate: 한 단계에서 요소 선택과 동작 모두 정답이면 성공으로 계산.
- Task Success Rate: 모든 단계가 정답일 때만 성공으로 처리 (엄격한 기준).
현재 LLM들이 전체 과제를 끝까지 성공(Task Success Rate)하기는
너무 어려움.
따라서 각 단계별 성공률(Step Success Rate)을 주요 지표로 사용.
→ 액션 하나하나의 정확도를 독립적으로 평가.
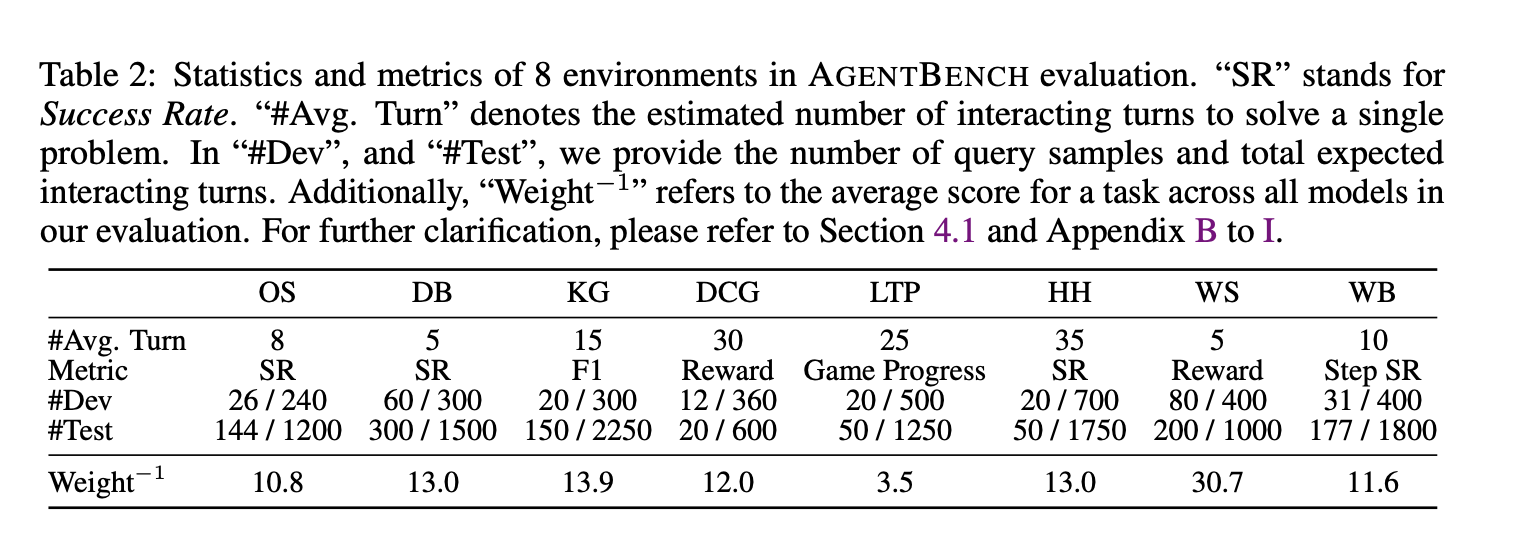
EVALUATION OF AGENTBENCH
4.1 EVALUATION SETUP
AGENTBENCH 논문 정리
평가 지표
AGENTBENCH는 환경별 특성을 반영하여 다양한 지표를 사용
-
Success Rate (SR)
OS, DB 같은 코드 기반 환경에서 사용.
모델이 문제를 정확히 해결했는지 여부(0/1)로 평가. -
Answer F1
Knowledge Graph 환경에서 사용.
모델이 예측한 답과 정답 엔티티 집합 간 F1 점수로 측정. -
Exact Match (EM)
KG에서 보조 지표. 모델이 낸 예측 집합과 정답 집합이 완전히 일치하는지 평가. -
Reward 점수 (WebShop)
사용자가 원하는 속성과 실제 선택된 상품 속성의 일치율 기반 [0~1] 점수. -
Action Accuracy / Action F1 (Mind2Web)
웹 브라우징에서 특정 HTML 요소 선택 정확도(Element Accuracy),
액션 토큰 단위 매칭(Action F1),
단계별 성공률/전체 성공률(Task Success Rate). -
Overall AGENTBENCH Score (OA)
태스크별 점수를 정규화(normalize)한 뒤 가중 평균.
특정 태스크(Web Shopping 등)가 평균을 왜곡하지 않도록 조정.
평가 방식
1. 벤치마크 구조
- 다양한 환경: 총 8개 환경을 코드, 게임, 웹으로 나눔.
- multi-turn 상호작용: 단순 1회 응답이 아니라, 실제 환경에서 여러 번 대화·액션을 반복해야 성공.
- 가상 시뮬레이터가 아닌, 운영체제·데이터베이스·실제 웹페이지 등과 직접 상호작용하도록 설계.
2. 실행 환경과 프레임워크
서버-클라이언트 구조: 에이전트(LLM), 환경(Task Server), 평가 도구가 분리돼 있어 확장성 확보.
도커 기반 환경 격리: OS, DB 같은 복잡한 환경은 Docker 이미지로 캡슐화 → 충돌 방지와 재현 가능성 보장.
평가 재개 가능성: 중도 중단된 평가도 이어서 실행할 수 있는 구조를 마련.
3. 프롬프팅 방식
- Chain-of-Thought (CoT): 모델이 “생각(Reasoning) → 행동(Action)” 순서를 명시적으로 따르도록 유도.
- Few-shot 학습: 액션 포맷과 출력 방식을 이해시키기 위해 예시 대화 제공.
- 대화 패러다임: User ↔ Agent가 교대로 메시지를 주고받으며, 각 턴에서 LLM은 Thought와 Action을 출력.
- 출력 규칙: 액션은 제한된 형태(bash, SQL, API 호출 등)로 강제됨.
4. 환경별 특화 평가 방식
- OS / DB: 실제 실행 결과를 기준으로 정답 여부 판별 → 성공률(SR) 측정.
- KG: API 형태의 툴 호출을 제공 → F1, Exact Match로 평가.
- WebShop: 상품 속성과 목표 속성의 유사도 기반 보상 점수 계산.
- Mind2Web: HTML 요소를 소형 LM(DeBERTa 등)으로 필터링
→ 다지선다 QA로 변환
→ Element Accuracy, Action F1, Step Success Rate로 평가.
5. 실패 원인 분석
모델이 실패하는 원인을 세분화하여 성능 부족 지점을 드러냄:
- CLE (Context Limit Exceeded): 대화 기록이 최대 맥락 길이를 초과.
- Invalid Format: 프롬프트에서 요구한 출력 포맷을 따르지 않음.
- Invalid Action: 존재하지 않거나 잘못된 액션을 선택.
- TLE (Task Limit Exceeded): 허용된 턴 수를 넘겨도 문제 해결을 못 함.
- Complete: 정상적으로 문제 해결.
Ko-AgentBench 적용 가능 포인트
-
환경별 분류
Code / Game / Web 으로 나눈 것처럼, 상위 카테고리(환경)를 먼저 정함.
환경 안에서 여러 한국어 특화 API 제공.
Task는 API를 활용/조합하는 형태로 설계. -
평가 지표
- 정답 일치 기반 지표: Exact Match, F1
- 과정 일치 기반 지표: Step Success Rate, Action F1
- 결과 활용성 기반 지표: Reward 점수 (현실에서의 효용성)
-
실행 기반 평가 (Execution-based Evaluation)
API-Bank와 유사하게, 실제 API 호출 실행 결과를 활용.
단순 텍스트 생성 정답 비교보다 신뢰도 ↑. -
오류 유형 분석
Interaction vs API 계층으로 나눠서 분석
ex.Invalid Action오류가 Interaction Level의 IA인지,
API-Level의 Invalid Input Parameters인지 구분 가능.
- Interaction 오류 (AGENTBENCH 기반)
CLE (Context Limit Exceeded): 컨텍스트 길이 초과
IF (Invalid Format): 출력 포맷 불일치
IA (Invalid Action): 행동 자체가 유효하지 않음
TLE (Task Limit Exceeded): 멀티턴 내 해결 실패 / 무한 반복
Complete: 정상 완료- API 호출 오류 (API-Bank 기반)
API Hallucination: 존재하지 않는 API 호출
Has Exception: 실행 시 예외 발생
Invalid Input Parameters: 잘못된 입력값 포함
False API Call Format: 호출 문법 오류로 파싱 불가
No API Call: 호출 자체가 없음
Missing Input Parameters: 필수 입력 파라미터 누락