논문 선정 이유
- 진단 가능성
: API-Bank의 장점을 차용하여, 모델이 '왜' 실패했는지
(도구 검색 실패, 계획 오류 등) 분석할 수 있는 세분화된 평가 지표를 도입
논문 리뷰
- 현재 LLM은 tool를 얼마나 효과적으로 사용하는가?
- LLM의 tool 사용 능력을 어떻게 향상시킬 수 있는가?
- LLM이 tool를 효과적으로 활용하기 위해 극복해야 할 문제점은 무엇인가?
이러한 질문들을 해결하기 위해, API-Bank 벤치마크를 개발.
API-Bank 설계 원칙
500명 이상의 사용자를 인터뷰하여
tool-augmented LLM에 대한 요구사항을 파악.
이를 바탕으로, 평가범위에 세 가지 핵심 능력이 포함되도록 함.
-
계획(Planning)
: 복잡한 요청을 해결하기 위한 단계 계획 능력 -
검색(Retrieving)
: 큰 API 목록에서 적절한 API를 찾아내는 능력 -
호출(Calling)
: API를 정확한 형식으로 호출하고 결과를 활용하는 능력
Ability Grading
사용자가 정의한 API Pool을 기반으로 적절한 시점에 올바른 API를 호출
→ 두 가지 축을 정의
Few vs. Many APIs in Pool
-
Few APIs (2~3개)
: 모든 API 정보를 LLM 입력에 포함 가능
→ LLM은 직접 비교 후 API 선택 가능 -
Many APIs (수백 개)
: 입력 길이 한계 때문에 모든 API 정보를 넣기 어려움
→ LLM이 먼저 검색(retrieve) 을 통해 적합한 API를 찾아야 함
Single vs. Several API calls per Turn
-
Single Call (단일 호출)
: 사용자가 단계별로 질의를 나눠서 진행
→ LLM은 매번 하나의 API만 호출 -
Multiple Calls (다중 호출)
: 사용자가 복잡한 요구를 한 번에 제시
→ LLM이 스스로 여러 API를 순차 호출하여 문제 해결
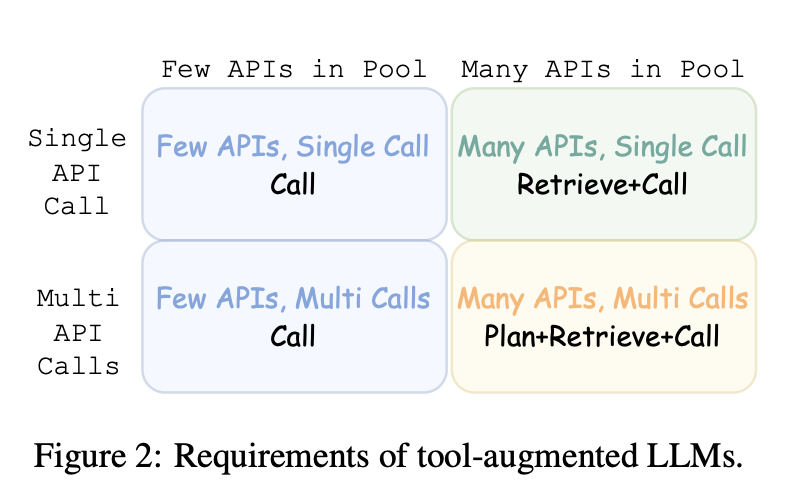
실제 구현해보니
Few APIs + Single Call과 Few APIs + Multiple Calls은
난이도가 거의 같아서, 둘을 하나로 합침.
남은 3가지 Ability Grading
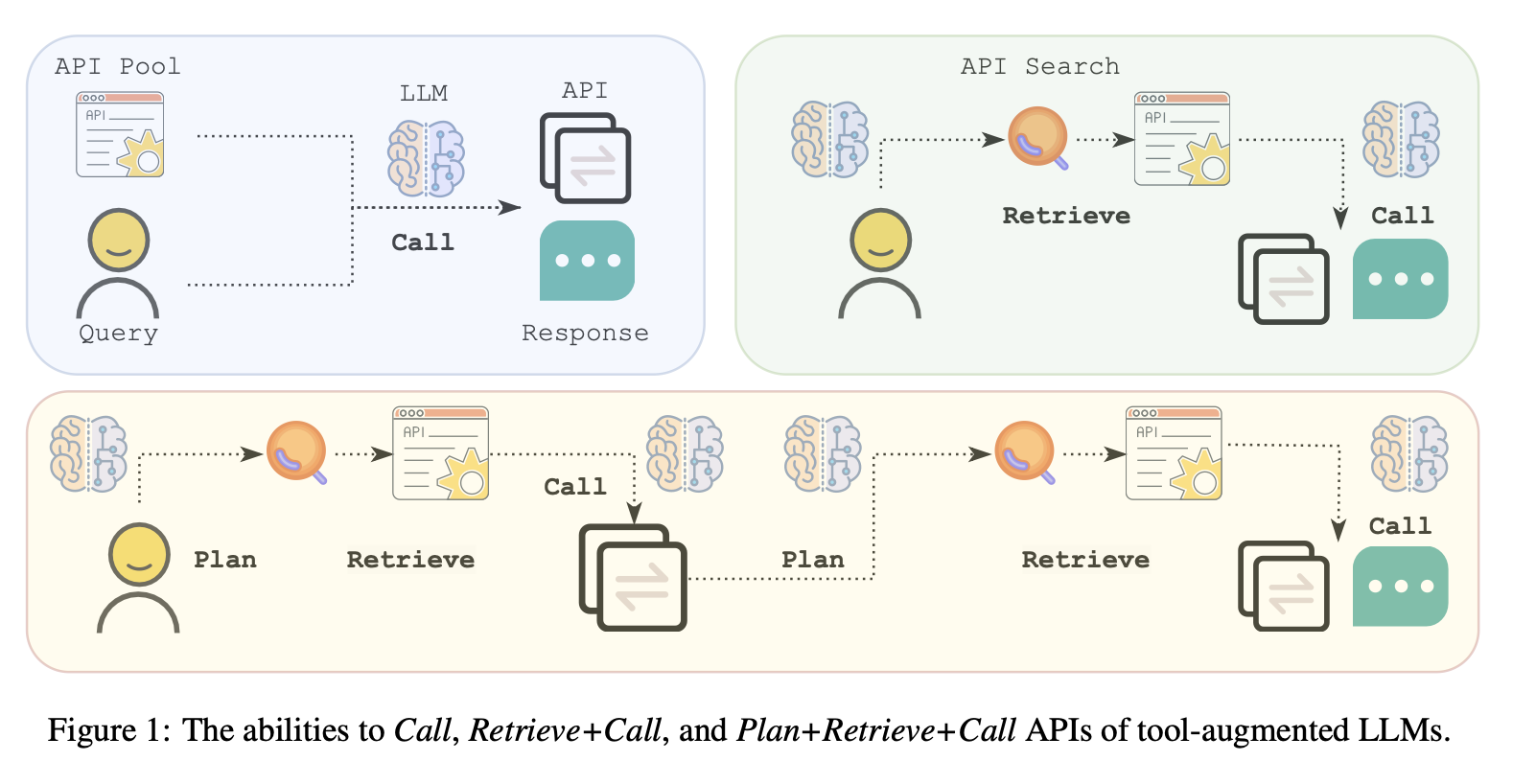
- Call
API가 이미 주어져 있을 때, 단순히 정확히 호출할 수 있는 능력.
- Retrieve + Call
API Pool이 크고, 어떤 API를 써야 할지 처음엔 모르는 경우
→ 검색(retrieve) 후 올바른 API를 찾아 호출해야 하는 능력.
- Plan + Retrieve + Call
복잡한 요구를 충족하기 위해 여러 API를 순차적으로 검색하고 호출하며 계획을 세우는 능력.
Data Standards
-
Domain diversity (도메인 다양성)
훈련/테스트 데이터가 여러 분야를 폭넓게 커버해야 함 -
API authenticity (API의 현실성)
API의 이름, 정의, 입력/출력 파라미터가 실제 세상에서 쓰는 API와 비슷해야 함 -
API diversity (API의 다양성)
데이터셋 안에 다양한 유형과 목적의 API를 넣어야 함. -
Evaluation authenticity
API 호출의 정확성과 그 결과에 기반하여 LLM이 사용자에게 제공하는
최종 응답의 품질까지 종합적으로 고려하여 성능을 측정
Evaluation System of API-Bank
System Implementation
API 구현
총 73개의 API를 구현
- 일상적으로 쓰이는 API (ex. 날씨 예보)
- 다른 AI 모델 호출하는 API (ex. Text-to-Image 생성)
- DB 관련 API
: 필요한 데이터베이스를 구축, 초기 데이터를 입력 (대화 맥락 형성을 위해) - 외부 정보 접근 API
: 검색된 정보가 일정하게 고정.
테스트 대화에서 사용된 모든 API 쿼리와 결과를 기록.
이후 실행 시 항상 동일한 결과가 나오도록 하드코딩 처리.
특수 API 개발 – "API Search"
: Retrieval+Call, Plan+Retrieval+Call 과제 해결용,
어떤 API를 사용해야 할지 찾아낼 수 있도록 돕는 검색 도구
상황: 모델이 API Pool에 어떤 API들이 있는지 사전에 모르는 경우
-
모델이 사용자 요구를 보고 → 핵심 키워드 추출
-
API Search를 호출해서 → 키워드와 API Pool에 있는
모든 API 메타 정보로부터 문장 임베딩 획득 -
전체 API Pool 메타정보와 임베딩 유사도 계산
-
가장 유사도가 높은 API의 설명을 반환받음
-
모델은 그 API를 실제로 호출해서 결과를 얻음
Dialogue Annotation
Call 능력 데이터
- API Pool에서 무작위로 API 몇 개 샘플링
- annotator가 해당 API 문서를 보고,
그 API로 해결할 수 있는 사용자 질의(query)를 직접 상상해서 작성 - 정답 API 호출을 라벨링하고 실제 실행
- 실행 결과를 기반으로 정답 response를 기록
같은 API들을 두고 여러 턴(turn)으로 이어지는 대화 데이터도 기록.
Retrieval+Call 능력 데이터
복잡한 사용자 요구 → 여러 개의 단순 질의로 분해
- API Pool에서 1~5개의 API를 선택
- annotator가 API들이 함께 사용되면 복잡한 요구를 해결할 수 있는지 확인
- 가능하다면 복잡한 요구를 여러 개의 단순 질의로 분리
- 각 단순 질의마다 정답 API + 입력 파라미터,
시스템 실행 결과에 따라 LLM이 생성해야 할 정답 응답을 라벨링
Plan+Retrieval+Call 능력 데이터
LLM이 스스로 계획을 세우고 여러 API를 순차적으로 호출하는 상황
- Retrieval+Call과 유사하지만, 질의를 단순화하지 않고 그대로 사용
- annotator는 연속적인 API 호출 시퀀스(Chain)와
마지막 API 실행 결과 기반 응답을 라벨링
비용: 평균 $8 / 대화 → 비쌈.
Evaluation Metrics
1. API 호출의 정확성 (Correctness of API calls)
지표: Accuracy (정확도)
- 평가 시작 시, 각 API에 연결된 데이터베이스를 default values으로 세팅
- 모델이 생성한 API 호출과 annotator가 만든 정답 API 호출 비교
- 두 호출이 같은 DB 조회/수정 작업을 수행하고, 반환 결과도 동일한지 확인
→ 일치하면정답, 아니면오답(consistency)
2. LLM 응답의 품질 (Quality of LLM responses)
지표: ROUGE-L
모델이 API 결과를 받아서 생성한 응답을, 정답 응답과 비교
ROUGE-L
응답 간의 Longest Common Subsequence 기반 유사도 측정
Training Set of API-Bank
API-Bank는 단순히 평가뿐 아니라,
LLM이 도구(API)를 더 잘 쓰도록 훈련 데이터셋도 제공하려 함.
하지만 문제:
- 수작업 annotator 비용이 $8/대화 → 대규모 데이터셋 구축 시 너무 비쌈
- annotator가 고안할 수 있는 API 수가 한정적 → 도메인 다양성 부족
Multi-Agent Data Generation
단일 LLM에 너무 많은 조건(domain diversity, API diversity & authenticity, Call/Retrieve/Plan 능력 등)을 한 번에 요구하면 잘 따르지 못함.
- ChatGPT → usable data 약 5%
- GPT-4 → usable data 약 25%
해결책: Multi-Agent Data Generation 사용
복잡한 요구를 여러 작은 Task로 분리 → LLM 에이전트들이 단계별로 수행.
총 5개의 Agent 협업.
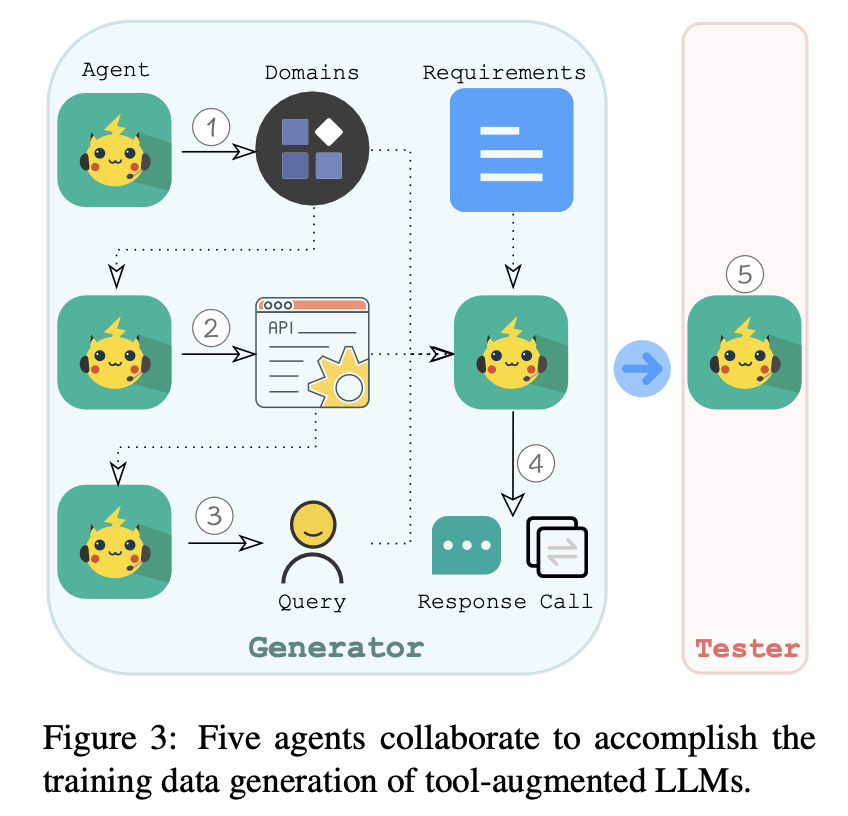
-
Domain Generator
의료, 피트니스, 금융, 여행 등 도메인 생성 -
API Generator
도메인에 맞는 potential(시뮬레이션된) API 생성.
실제 공공 API 예시를 프롬프트에 넣어서
현실적인 API 구조(authenticity)를 흉내내게 만듦. -
Query & Ability Selector
생성된 API 중 1~n개 선택
평가 능력(Call, Retrieve+Call, Plan+Retrieve+Call) 중 하나 선택
해당 능력에 맞는 Query 작성 -
Caller & Responder
선택된 API와 질의를 받아 → 실제 API 호출 시뮬레이션 수행
실행 결과를 바탕으로 응답(Response) 생성 -
Tester (Verifier)
생성된 데이터가 설계 원칙을 충족하는지 자동 검증
이렇게 자동 검증을 거쳤을 때, 약 35%의 데이터는 불합격 처리
multi-agent 접근으로 품질은 유지하면서 비용을 대폭 절감 : $0.1/대화
Benchmark Analysis
Statistics
최종 벤치마크 규모:
도메인: 1,008
APIs: 2,211
대화(dialogues): 2,202
턴(turns): 6,135
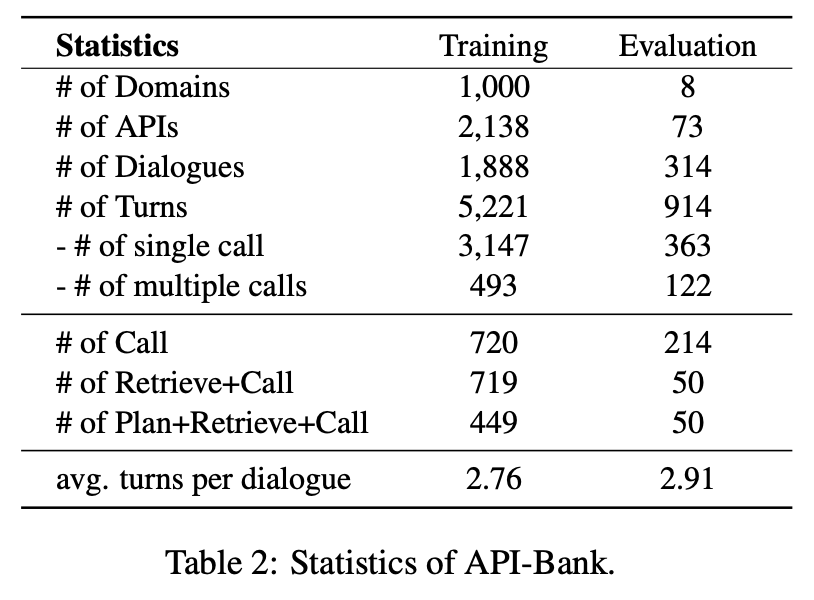
데이터 생성 방식의 차이:
- 훈련 데이터 (Training data)
Multi-agent 방식으로 LLM이 자동 생성한 데이터 - 평가 데이터 (Evaluation data)
사람이 manually annotated한 데이터
→ 훈련된 LLM이 훈련 과정에서 보지 못했던 새로운 도메인, API, 대화 시나리오에서도 얼마나 잘 작동하는지, 일반화 능력을 평가하기 위함
Quality
4명의 annotator가 검토한 평가 데이터셋을 기준으로 삼아,
자동으로 생성된 Training set의 품질과 신뢰성을 검증
- Multi-agent 생성 데이터 100개 샘플 점검 → 94% usable
- 단일 LLM(Self-instruct) 생성 데이터 대비 89% 개선
- Tester agent가 걸러낸 데이터 중 78%는 실제로 설계 원칙에 어긋남
→ 자동 필터링의 효과 입증
Comparison
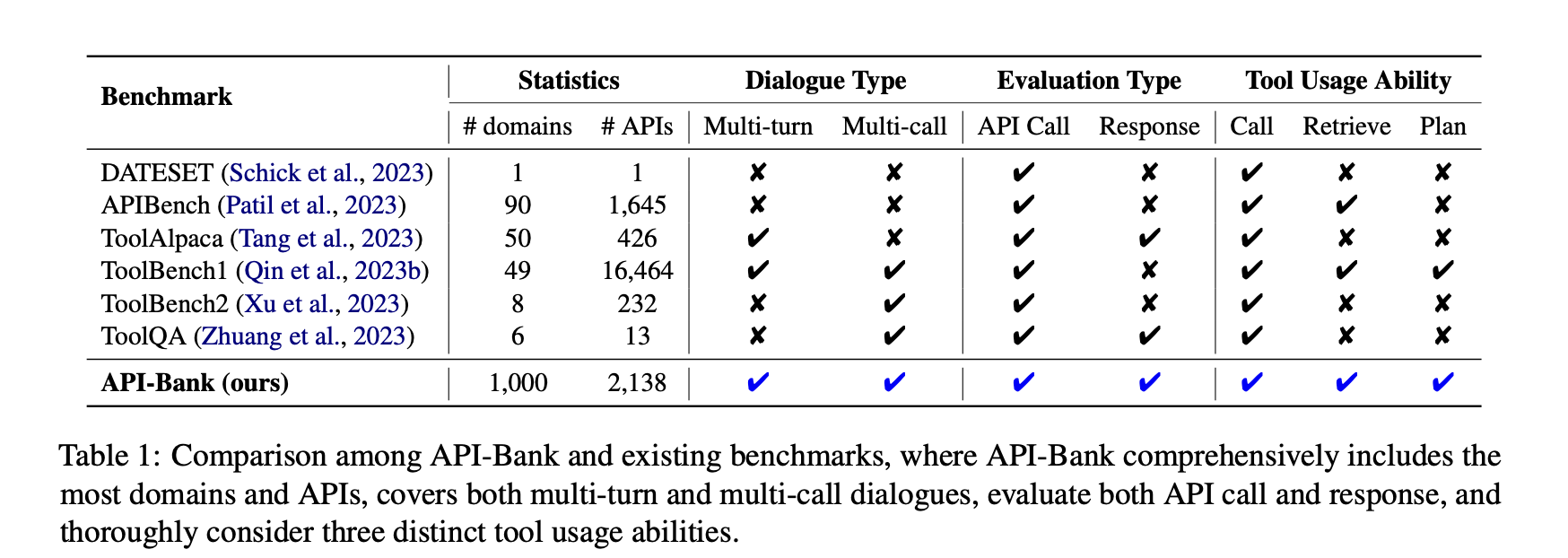
- Highest diversity
다양한 도메인과 API - Highest realism
실제와 유사한 multi-turn과 multi-(API)call 대화를 모두 지원 - Highest coverage
Plan, Retrieve, Call 능력을 모두 고려
Experiments
Fine-tuning Lynx (LLaMA-7B 기반)
Lynx를 API-Bank 데이터로 튜닝해
→ API-Bank 평가 시스템에서 다른 LLM들과 성능 비교
평가 환경: API-Bank evaluation system
평가 방법: 준비된 프롬프트를 사용

목표:
- Lynx 모델의 성능을 다른 LLM들과 비교
- LLM의 도구 활용에서 남아있는 challenges를 확인
Baselines
GPT-3, GPT-3.5, GPT-4, ChatGLM-6B, Alpaca-7B
Main Results
전체적인 경향
-
요구 능력(Call → Retrieve+Call → Plan+Retrieve+Call)이 높아질수록 모델 성능은 점진적으로 하락.
-
기본 LLM도 단순 API Call은 일정 성능 발휘 가능
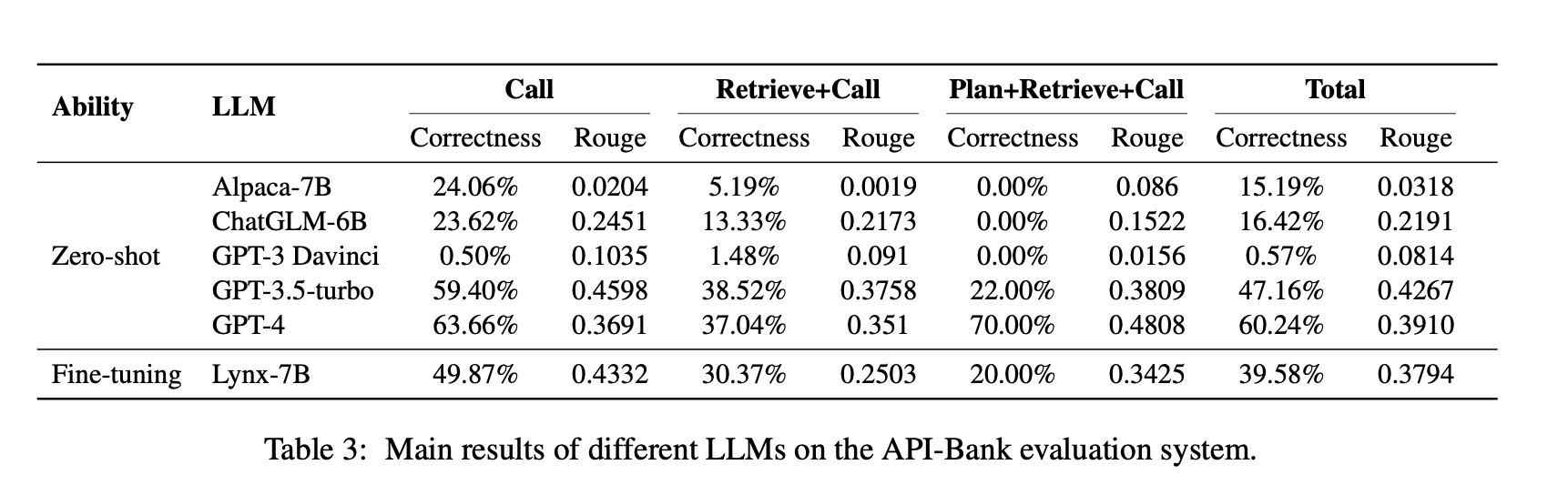
Lynx (API-Bank로 파인튜닝된 Alpaca-7B)
Alpaca-7B 대비:
- API Call 정확도 +26포인트
- Response 품질(ROUGE-L) +0.41
성능이 GPT-3.5에 근접
→ Multi-agent 방식으로 생성한 API-Bank 훈련 데이터의 품질 우수성 입증
벤치마크 차별성
GPT-3.5는 APIBench, ToolAlpaca의 데이터셋에서 80~90% 정확도 달성.
반면, API-Bank에서는 GPT-3.5 성능이 더 낮게 나옴
APIBench, ToolAlpaca은 LLM(Self-instruct) 자동 생성 데이터 사용
→ 도메인 협소, 다양성 부족
Error Analysis
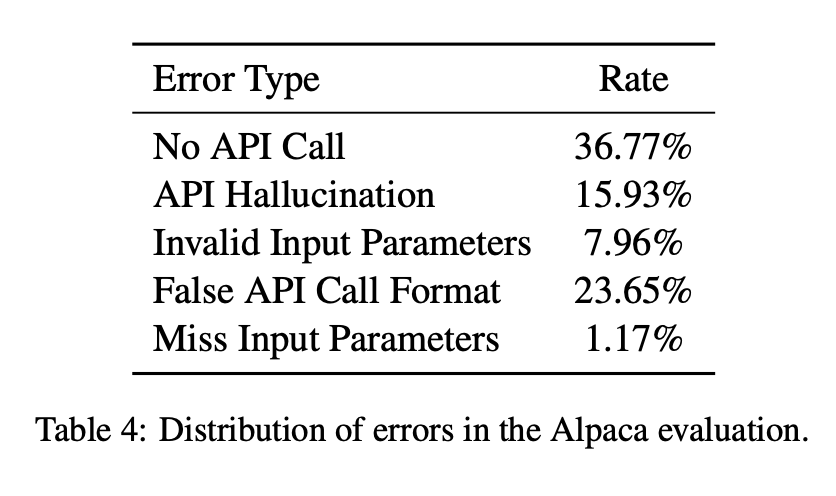
오류 유형
-
API Hallucination
예측한 API 이름이 Ground Truth API 이름과 일치하지 않음
→ 존재하지 않거나 잘못된 API를 호출한 경우 -
Has Exception
예측한 API 호출이 실행 중에 Python Exception을 발생시킴
정답 호출에서는 이런 오류가 없어야 함 -
Invalid Input Parameters
예측한 API 호출에 잘못된 입력 파라미터가 포함됨
ex. 형식 불일치, 잘못된 값 -
False API Call Format
예측한 API 호출의 형식이 파싱 불가능
ex. 괄호·쉼표 누락, JSON 문법 오류 등 -
No API Call
예측 결과에서 API 호출이 아예 감지되지 않음 -
Missing Input Parameters
예측한 API 호출에서 필수 입력 파라미터가 누락됨
LLM 개선 방향
- Improved API calling methods
- Enhanced API decoding algorithms
- Larger-scale training data
API-Bank 논문 정리
평가 지표
- API Call 정확도 (Accuracy)
모델이 예측한 API 호출 시퀀스가 정답 호출과 일관(consistency) 하면 정답으로 카운트.
consistency 판단: 같은 DB 조회/수정이 일어나고, 반환 결과가 동일하면 정답으로 간주
Call / Retrieval+Call / Plan+Retrieval+Call 에 공통 적용
- 최종 응답 품질 (ROUGE-L)
API 실행 결과를 바탕으로 LLM이 생성한 자연어 응답과 정답 응답의 유사도
평가 방식
1. Ability Grading
Call: API가 주어졌을 때 올바르게 호출.
Retrieval+Call: API 목록을 모르는 상태에서 API Search → 호출.
Plan+Retrieval+Call: 복수 호출을 계획(Plan) + 검색 + 연쇄 호출.
2. 시스템 구현
DB 초기화, 외부 검색류는 평가 시점에 한 번만 결과를 가져와 고정된 응답으로 저장(하드코딩).
