Intuition: margin
margin : 어느 정도까지 허용하고도 제대로 분류할 수 있는 여유 공간
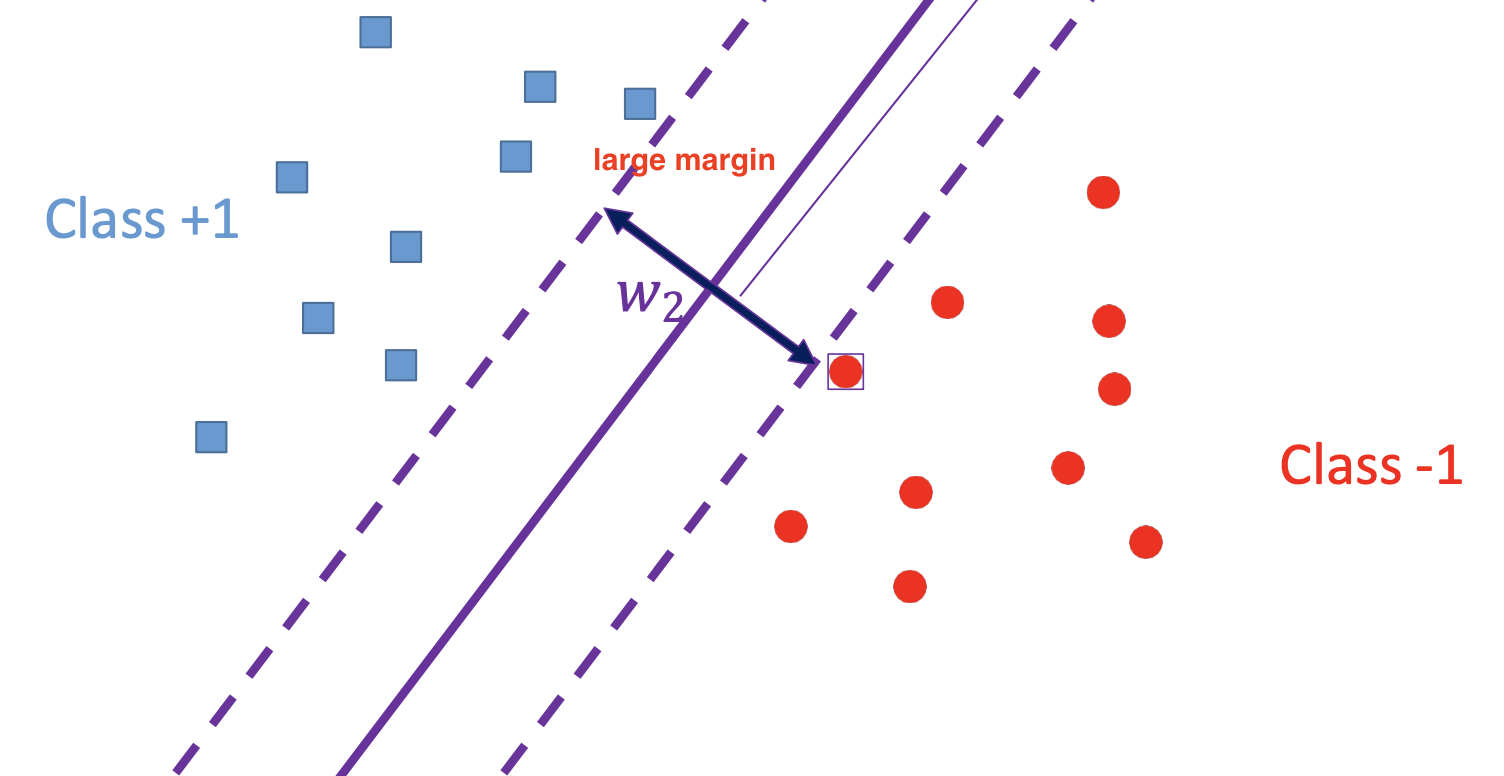
margin이 클수록 두 클래스의 “안전 영역”이 넓어져서,
새로운(시험) 데이터가 조금 이동해도 결정 경계 쪽으로 치우칠 가능성이 줄어들어
→ 일반화 성능이 좋아짐
Support Vector Machine
가장 넓은 margin을 주는(=가장 안정적인) 선형 경계를 찾아서 분류하고,
이 경계를 결정짓는 서포트 벡터들만
학습에 실제로 영향을 미치도록 설계된 모델
서포트 벡터(Support Vectors)
마진을 결정짓는(=경계에 가장 가까이 붙어 있는) 데이터 포인트
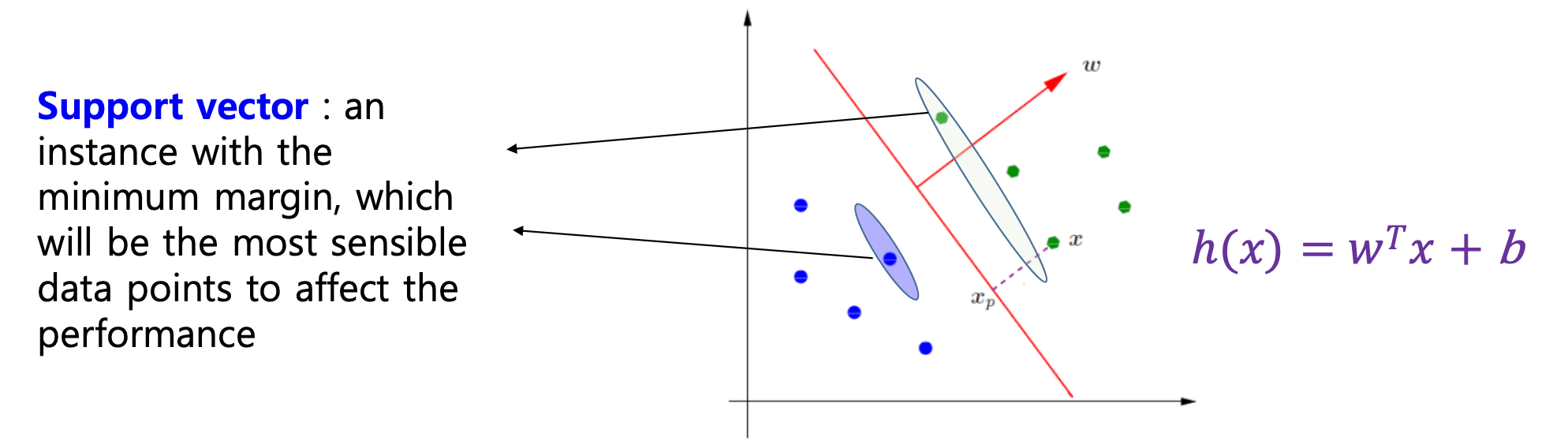
데이터 셋에 멀리 떨어진 노이즈나 이상치가 섞여 있어도,
그 포인트가 서포트 벡터 자리에 들어오지 않는 이상 경계를 바꾸지 않음
→ 모델이 이상치에 덜 민감해져서 robust(강건)
Margin
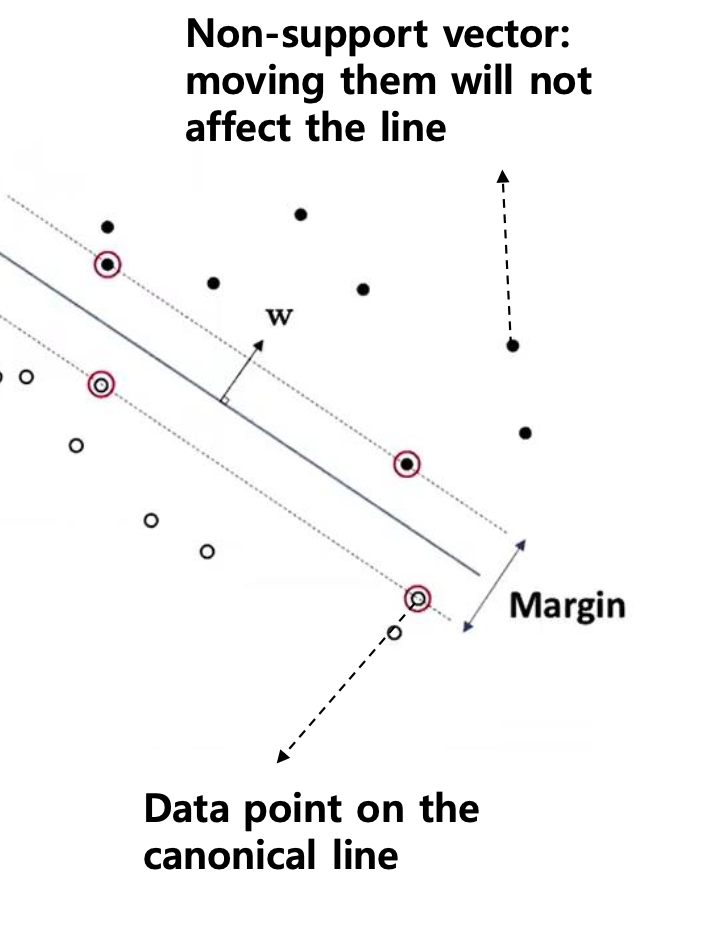
서포트 벡터
- 위쪽 클래스(+1)에서 가장 가까운 점을 하나
- 아래쪽 클래스(−1)에서 가장 가까운 점을 하나 선정
hyperplane ⇔ 서포트 벡터 간 거리
최적화가 잘 된 상태라면 :
- 한쪽 서포트 벡터가 hyperplane으로부터 떨어진 거리 = d라고 하면,
- 다른 쪽 서포트 벡터도 똑같이 d만큼 떨어져 있음
→ 마진(margin) = 2 × d
거리 공식
distance(x,hw,b(x)=0)=∥w∥∣wTx+b∣
: hw,b(x)=wTx+b=0인 hyperplane에서
어떤 점 x가 떨어진 수직 거리
→ 두 클래스의 서포트 벡터들은 이 거리가 가장 작은 점들이고,
SVM은 이 최소 거리를 최대화 하도록 w,b 를 학습
Margin distance
어느 한 점 x가 hw,b(x)=wTx+b=0인 hyperplane에서
얼마나 떨어져 있는지를 보여주기 위한 증명
점 x 를 두 부분으로 분해하기
x⊥ : 주어진 점 x에서 hyperplane으로 수직으로 내렸을 때 닿는 점
∥w∥w : hyperplane의 법선(수직) 방향 단위벡터
r : x⊥로부터 x 까지 hyperplane에 수직으로 이동한 거리
x=x⊥+r∥w∥w
양변에 wT를 곱하고 b를 더하기
wTx+b=wT(x⊥+r∥w∥w)+b=(wTx⊥+b)+r∥w∥wTw
r∥w∥wTw=r∥w∥∥w∥2=r∥w∥ 이므로,
hw,b(x)=wTx+b=0+r∥w∥=r∥w∥
거리 공식
∥w∥∣wTx+b∣
Optimization
모든 점을 올바르게 분류하면서, 두 클래스 간 margin을 최대화하는
최적의 w와 b를 찾는 방법
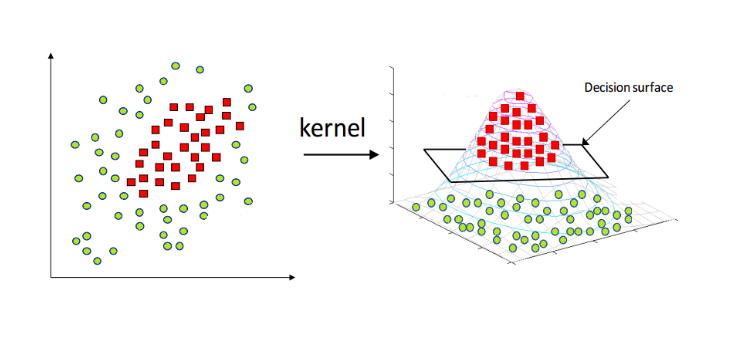
선형분리가 안 될 때 → 커널 트릭
현실 세계 데이터는 완벽히 선형분리가 어렵기 때문에,
비선형 특징 변환 ϕ(x)를 한 뒤
내적을 ϕ(x)Tϕ(x′) 대신 커널 함수 K(x,x′)로 계산하여
고차원 공간에서는 선형 분리가 가능하도록 만들어줌
Support vectors
서포트 벡터와 정규화
하이퍼플레인(결정경계) : hw,b(x)=wTx+b
margin 계산을 편하게 하기 위해
서포트 벡터에 대해 h(x)=±1이 되도록 w,b 스케일을 정규화
ex. 어떤 점 xt가 클래스 +1 쪽 가장 가까이 붙어 있다고 하면,
h(xt)=+1이 되도록 w,b를 전체적으로 늘이거나 줄임
거리 공식 유도
서포트 벡터는 wTx+b=±1이므로
support vector 거리 =∥w∥∣±1∣=∥w∥1
margin=∥w∥1−(−∥w∥1)=∥w∥2
constraints: linearly separable
클래스별 경계식
-
y=+1은
h(x)=wTx+b≥+1
실선 위쪽 영역에 있어야 하고
-
y=−1은
h(x)=wTx+b≤−1
실선 아래쪽 영역에 있어야 함
따라서,
yn×(wTxn+b)≥1
objective function
마진을 크게 ⇔ ∥w∥을 작게
거리를 최대화하려면 ∥w∥2를 키워야 하고,
이는 결국 ∥w∥을 최소화하는 것과 동일
→ ∥w∥2 최소화
최종 SVM Primal 문제
w,bmin∥w∥2subject toyi(wTxi+b)≥1(∀i)
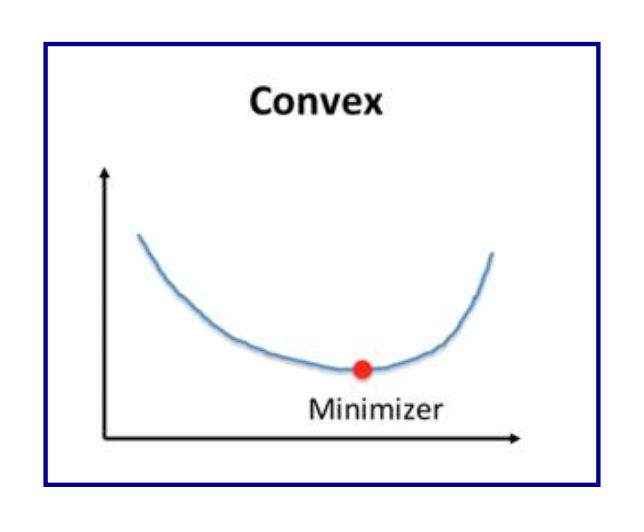
convex optimization
목적 함수가 2차(quadratic) 형태
w,bmin∥w∥2
제약 조건이 선형(linear) 형태
yi(wTxi+b)≥1for all samples i
부등식은 w와 b에 관해 linear
→ convex quadratic programming 문제, 전역 최적해가 보장
Primal and Dual problem for understanding SVM
SVM 최적화를 풀기 위해
primal problem → dual problem 로 바꾸는 과정
제약이 있는 일반적 최적화 문제
wminf(w)s.t.{gi(w)≤0,hj(w)=0,i=1,…,K(부등식 제약)j=1,…,L(등식 제약)
→ 이 상태로는 부등식 제약 + 등식 제약을 그대로 다루면서
w만 최적화해야 해서 풀기가 까다로움
라그랑지안(Lagrangian) 도입
제약(부등/등식)을 목적 함수 안으로 옮겨오기 위해
Lagrange multipliers αi,βj 를 도입
L(w,α,β)=f(w)+i=1∑Kαigi(w)+j=1∑Lβjhj(w)
Dual Problem (이중 문제)
-
Primal Problem (원래 문제) : P∗=minwmaxα≥0,βL(w,α,β)
-
Dual Problem : d∗=maxα,βminwL(w,α,β)
볼록(convex)한 문제라면 Strong Duality가 성립해 두 값이 같음
→ Dual 문제만 풀어도 Primal 해 w∗를 구할 수 있음
KKT 조건 (Karush–Kuhn–Tucker)
Primal과 Dual의 해 w∗와 α∗,β∗는
다음 네 가지 조건을 모두 만족해야만 최적해가 됨
- ∇wL(w∗,α∗,β∗)=0
- gi(w∗)≤0,hj(w∗)=0
- α∗≥0
- αi∗gi(w∗)=0
→ 네 가지를 만족할 때에만
Strong Duality, 두 문제의 해가 일치
Optimization objective function
Primal 문제: 제약 있는 최적화
minw,bJ(w)=∥w∥2
s.t. yi(wTxi+b)≥1,i=1,…,N
마진(margin) ∥w∥2를 최소화하면서
모든 샘플 (xi,yi)이 hyperplane로부터 최소 1 이상 떨어지도록
Dual 문제로 전환: Lagrangian 도입
L(w,b,α)=∥w∥2+i=1∑Nαi[1−yi(wTxi+b)]
Solving a dual problem
라그랑지안 정류 조건(Stationarity)
라그랑지안 함수 L(w,b,α)를 실제로 최적화하려면
w와 b에 대해 기울기(편미분)가 0이 되어야 함
L(w,b,α)=∥w∥2+i=1∑Nαi[1−yi(wTxi+b)]
를 w와 b에 대해 편미분하여 0으로 놓으면 :
∂w∂L=0⟹w=i=1∑Nαiyixi
→ 1. 최적 w는 샘플 벡터의 선형 결합
∂b∂L=0⟹i=1∑Nαiyi=0
→ 2. αi는 레이블 yi 합이 0이 되도록 분포
Primal 변수 w,b 제거
1번, 2번 식을 원래 Lagrangian에 대입해
w항은 ∑i=1Nαiyixi 으로 바꾸고
b항은 ∑i=1Nαiyi=0 으로 반영해서 제거
정리하면,
L(α)=i=1∑Nαi−21i=1∑Nj=1∑Nαiαjyiyj(xiTxj)
subject to
αi≥0,i=1∑Nαiyi=0
Convex Quadratic Programming(QP)
SVM Dual 문제는
일반적인 Convex Quadratic Programming(QP) 문제의 한 예
일반 QP 문제의 형태
목표
xmin21xTPx+qTx
제약
Ax=b,Gx≤h
SVM Dual ↔ QP 대응
αmaxi=1∑Nαi−21i=1∑Nj=1∑Nαiαjyiyj(xiTxj),
s.t.
i=1∑Nαiyi=0,αi≥0(∀i)
-
목표식
αmax[1Tα−21αTHα]⟺αmin21αTHα−1Tα
-
H 행렬의 구성
Hij=yiyj(xiTxj)
→ 표준 QP 포맷으로 SVM Dual을 풀 수 있음
Final solution
QP가 내놓은 최적의 αi∗ 값을 바탕으로, SVM의 최종 해인
w∗,b∗ 를 구하는 과정
가중치 벡터 w∗
QP 솔버가 반환한 αi∗ 중 0이 아닌 것(=서포트 벡터)에 대해서만 더함
편향(bias) b∗
서포트 벡터 중 하나를 골라, 결정 경계 조건
w∗Tx++b∗=+1,w∗Tx−+b∗=−1
을 평균내면 편향이 구해짐
b∗=−21(w∗Tx++w∗Tx−)
예측 함수 h(x)
최종 분류기는
h(x)=sign(w∗Tx+b∗)=sign(i=1∑Nαi∗yixiTx+b∗)
Example (in 2D)
2차원 공간에 3개의 샘플이 있을 때
SVM의 듀얼 문제를 풀어서 w와 b를 구하기

예제에서 주어진 xi와 yi
입력 벡터
x1=(10),x2=(01),x3=(02)
레이블
y1=+1,y2=−1,y3=−1
입력 내적(Gram) 행렬 Kij=xiTxj

K=⎝⎜⎛100012024⎠⎟⎞
H 행렬 : Hij=yiyjKij
H=⎝⎜⎛(+1)(+1)1(−1)(+1)0(−1)(+1)0(+1)(−1)0(−1)(−1)1(−1)(−1)2(+1)(−1)0(−1)(−1)2(−1)(−1)4⎠⎟⎞=⎝⎜⎛100012024⎠⎟⎞
dual 목적함수
J(α)=i=1∑3αi−21[α1,α2,α3]⎣⎢⎡100012024⎦⎥⎤⎣⎢⎡α1α2α3⎦⎥⎤
=α1+α2+α3−[0.5α12+0.5α22+2α32+2α2α3]
제약조건
제약조건 ∑i=13αiyi=0
(+1)α1+(−1)α2+(−1)α3=0⟹α1−α2−α3=0
부등식 제약
α1≥0,α2≥0,α3≥0
최적조건(편미분)
목적함수 J(α₁,α₂,α₃)의 최적점을 찾기 위해
변수 α₁, α₂, α₃에 대해 편미분(∂J/∂αᵢ)을 모두 0으로 놓음
⎩⎪⎪⎨⎪⎪⎧1−α1=0,1−α2−2α3=0,1−2α2−4α3=0.
α1−α2−α3=0 과 풀면
α1=1,α2=1,α3=0
w와 b 복원
가중치 벡터 w
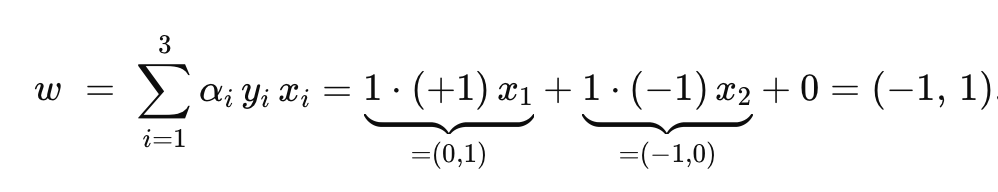
bias b
서포트 벡터로 (0,1) (양성) 과 (1,0) (음성)을 고르면 :
w∗Tx++b=+1
w∗Tx−+b=−1
b+=1−wT(0,1)=1−(−1⋅0+1⋅1)=1−1=0
b−=−1−wT(1,0)=−1−(−1⋅1+1⋅0)=−1−(−1)=0
두 값을 평균 내 주면 b=0
최종 분류함수
h(x)=sign(wTx+b)=sign(−1⋅x1+1⋅x2)
Properties of dual variable 𝜶
Lagrangian multipliers 𝛼
SVM의 듀얼 문제를 세울 때, 각 훈련 샘플 i 마다 하나씩 도입됨
비음수여야 함. αi≥0
서포트 벡터와 비서포트 벡터
-
서포트 벡터(Support Vector)
αi>0 인 샘플들만 최종 결정 경계를 결정하는 데 기여
Margin 경계에 걸려 있어서 yi(wTxi+b)=1 만족
-
비서포트 벡터(Non–Support Vector)
αi=0인 샘플들
yi(wTxi+b)>1 인 영역에 있어서 경계 결정에 전혀 영향을 주지 않음
결정 계수 w 의 표현
w=i=1∑Nαiyixi=i:αi>0∑αiyixi
0인 αi들은 합에 기여하지 않으므로
실제로는 서포트 벡터들만으로 w 를 구성
Drawbacks of SVM
원래 입력 공간에서는 서로 섞여 있어서
선형(직선·평면)으로 분리할 수 없는 데이터를 다루는 방법
원래 입력 공간에서 비선형 모델을 쓰는 방법
결정 트리나 신경망처럼
복잡한 경계(곡선·곡면)를 학습하는 분류기를 쓰는 방법
커널 트릭(kernel-trick)
입력을 더 높은 차원의 공간으로 변환한 뒤(=특징 변환),
그 공간에서 선형 모델을 사용
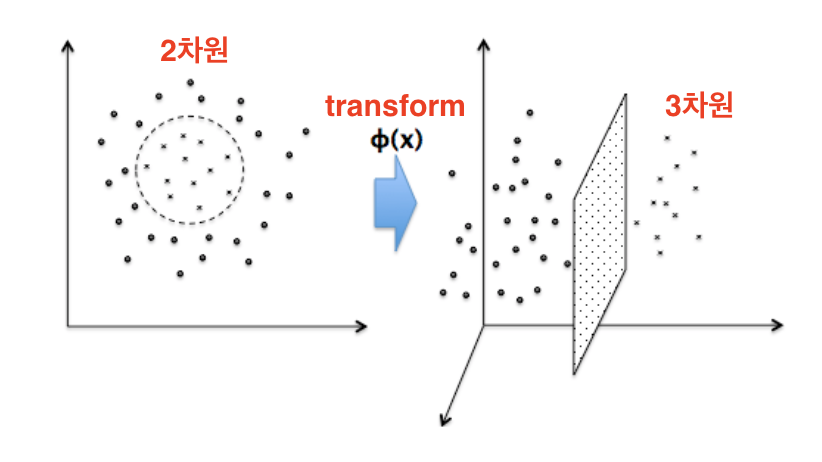
- 원형 영역 안팎으로 구분된 데이터는
2D 입력 평면상에서 원 하나로는 분리할 수 없지만,
- ϕ(x) 라는 함수로 3차원으로 transform하면
- 3D 공간의 하나의 평면으로는 나눌 수 있음
Linearity in linear models
비선형 입력을 쓰고 싶을 때
x가 복잡해서 직선·평면으로 분리할 수 없는 경우
원래 x 대신 ϕ(x)처럼 고차원·비선형 특징을 새로 만들어 사용
선형성은 w에 대해서만 유지됨
모델을
f(x)=wTx⟶f(x)=wTϕ(x)
바꿔도, 파라미터 w에 대해서는 여전히 linear하기 때문에
- 목적 함수는 여전히 볼록이고
- 경사(gradient), Lagrange multiplier를 구할 수 있음
비선형 변환 φ:X→Z,
x∈X⟼z=φ(x)∈Z
Z는 X보다 차원이 높음
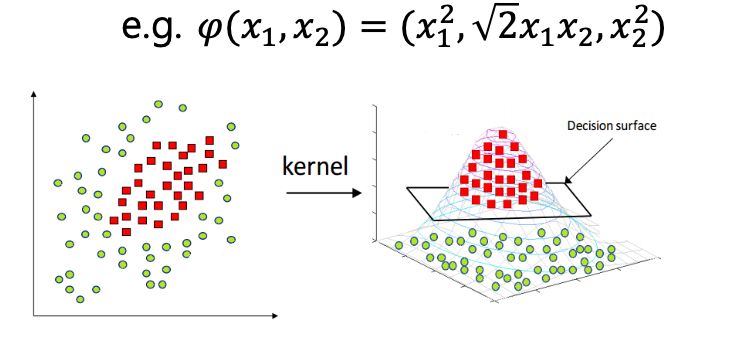
원래 (x1,x2) 평면에서 원형·타원형 경계가
Z에서는 평면 하나로 분리됨
복잡한 경계 → 고차원에서 선형
Some thoughts
SVM의 dual 목적함수
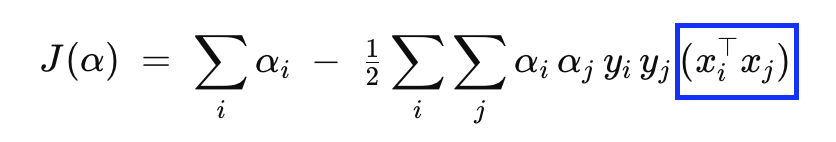
(xiTxj)만이 실제 입력 벡터의 차원 d 에 따라 달라지는 부분
고차원 맵 φ(x)을 만들면 계산·메모리 비용이 큼
Kernel
저 차원의 벡터를 받아서, 고차원 공간에서의 내적값만 돌려주는 함수
SVM dual 형태에서는 내적 φ(xa)⋅φ(xb) 만이 필요하고,
이는 커널 함수 K(xa,xb)로 대체할 수 있음
φ(xa)⋅φ(xb)=(a12,2a1a2,a22)⋅(b12,2b1b2,b22)=a12b12+(2a1a2)(2b1b2)+a22b22=a12b12+2a1a2b1b2+a22b22=(a1b1+a2b2)2=(xa⋅xb)2.
→ 3차원 사영 후의 복잡한 내적을
원래 2차원 점의 내적의 제곱 (xa⋅xb)2으로 대체
SVM dual 목적함수에서
i∑j∑αiαjyiyj(φ(xi)⋅φ(xj))
대신
i∑j∑αiαjyiyj(xi⋅xj)2
커널 함수 K는 특징 공간 내적을 원래 입력에 대한 함수로서 계산할 수 있게 해 줌
K(x,x′)=⟨φ(x),φ(x′)⟩,K:Rd×Rd→R
Some commonly used kernels
다항식 커널 (Polynomial Kernel)
입력 벡터 x,y의 내적에 상수 1을 더한 뒤, p차로 올려줌
K(x,y)=(x⋅y+1)p
파라미터
p: 다항식 차수
가우시안 RBF 커널 (Gaussian Radial Basis Function)
두 점 사이의 유클리드 거리를 지수 함수로 감쇠(decay)시켜,
가까운 점에 높은 값을, 먼 점에 낮은 값을 줌
K(x,y)=exp(−2σ2∥x−y∥2)
파라미터
σ: 반경을 조절.
σ가 작으면 국소적(local) 영향이 강해지고, 크면 더 넓게 부드럽게 퍼짐
시그모이드 커널 (Hyperbolic Tangent / MLP Kernel)
다층 퍼셉트론(neural network)의 은닉층 활성화 함수처럼,
입력 내적을 tanh로 통과시킴
K(x,y)=tanh(k(x⋅y)−δ)
파라미터
k: 입력 내적의 스케일
δ: 편향(bias) 역할
Radial-basis function (RBF) kernel
K(x,x′)=exp(−γ∥x−x′∥2)
- 점 x와 x′가 가까울수록 ∥x−x′∥가 작아지고, K는 1에 근접.
- 멀어질수록 K는 0에 수렴.
γ : RBF의 폭. 값이 클수록 '좁고 날카로운' 가우시안 곡선
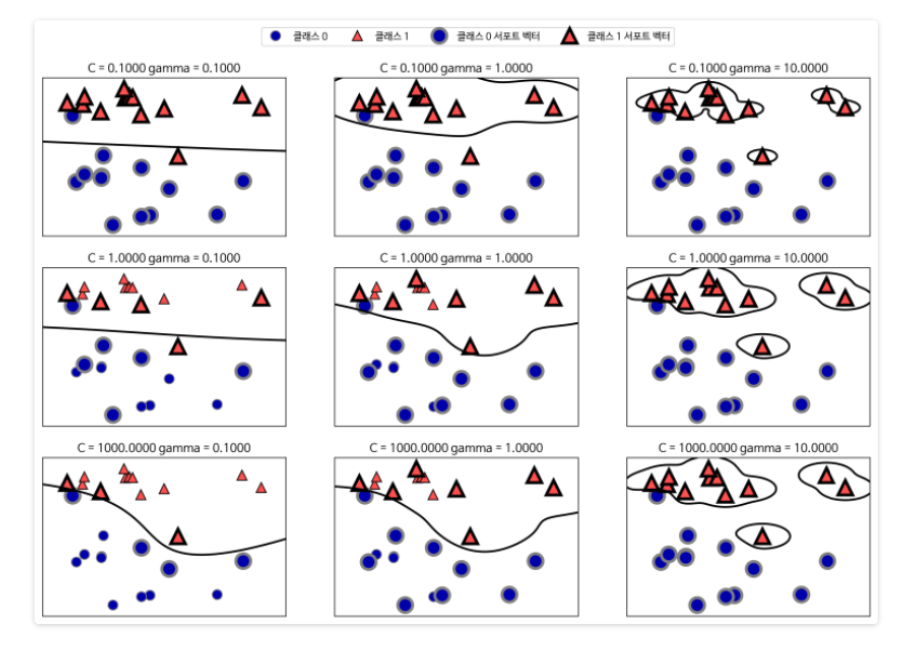
SVM의 장점
-
다양한 분야(ex. 이미지, 텍스트)에서 일관되게 좋은 결과를 보여줌
-
자동화된 학습 절차
적절한 커널 함수와 그 하이퍼파라미터(C, γ 등)만 선택하면,
Decision boundary 학습은 QP로 자동 수행
-
유연한 구조 가정
데이터의 분포나 경계 형태에 대한 사전 지식이 거의 없어도,
커널 트릭을 통해 비선형 경계를 효과적으로 학습
SVM의 단점
-
시간·공간 복잡도
학습 비용이 훈련 샘플 개수 N의 제곱에 비례 (O(N2), O(N3))하여, 데이터셋이 커지면 메모리·연산량이 급격히 늘어남
-
모델 저장 비용
결정 경계를 표현하는 서포트 벡터(αi>0인 샘플)를
모두 저장해야 하기 때문에,
서포트 벡터가 많으면 예측 시에도 메모리·계산이 많이 듦
