
BST
-
set
-
map
-
pair
-
ROM
-
->
이미 표준 라이브 러리에서 이진 탐색 트리를 제공하고있다.
std::map은 정확하게 말하면 class template이다.
set
int를 저장할 수 있는 이진 탐색 트리 기반의
"탐색"에 용이한 그런 자료구조 알고리즘을 사용한 "컨테이너"이다.
컨테이너란? => 객체를 저장하는 객체, 자료구조라고도 한다.
클래스 템플릿으로 구현되어있다.
https://velog.io/@starkshn/CPP%EC%96%B4%EC%86%8C59STL#1-container
컨테이너에 데이터 넣을 경우
이렇게 계속 넣으면 (들어는 가겠지)
그런데 setInt라는 "객체"의 메모리 공간안에 계속 들어 갈 수 있나?
이거를 물어보는 것임.
객체 자체의 메모리안에.
넣는 데이터를 어떤 식으로 관리를 할 거 같냐? 라는 것이다.
데이터를 관리하는 방식 ❗
은 "트리"라는 구조인것인데
이것은 "이론적"인 것이고
실질적으로 데이터는 "동적할당" 을 통해서 저장이 될 것이다.
즉, 힙메모리 영역을 사용 할 것이다.(힙메모리에 동적할당 해서 넣을 것이다)
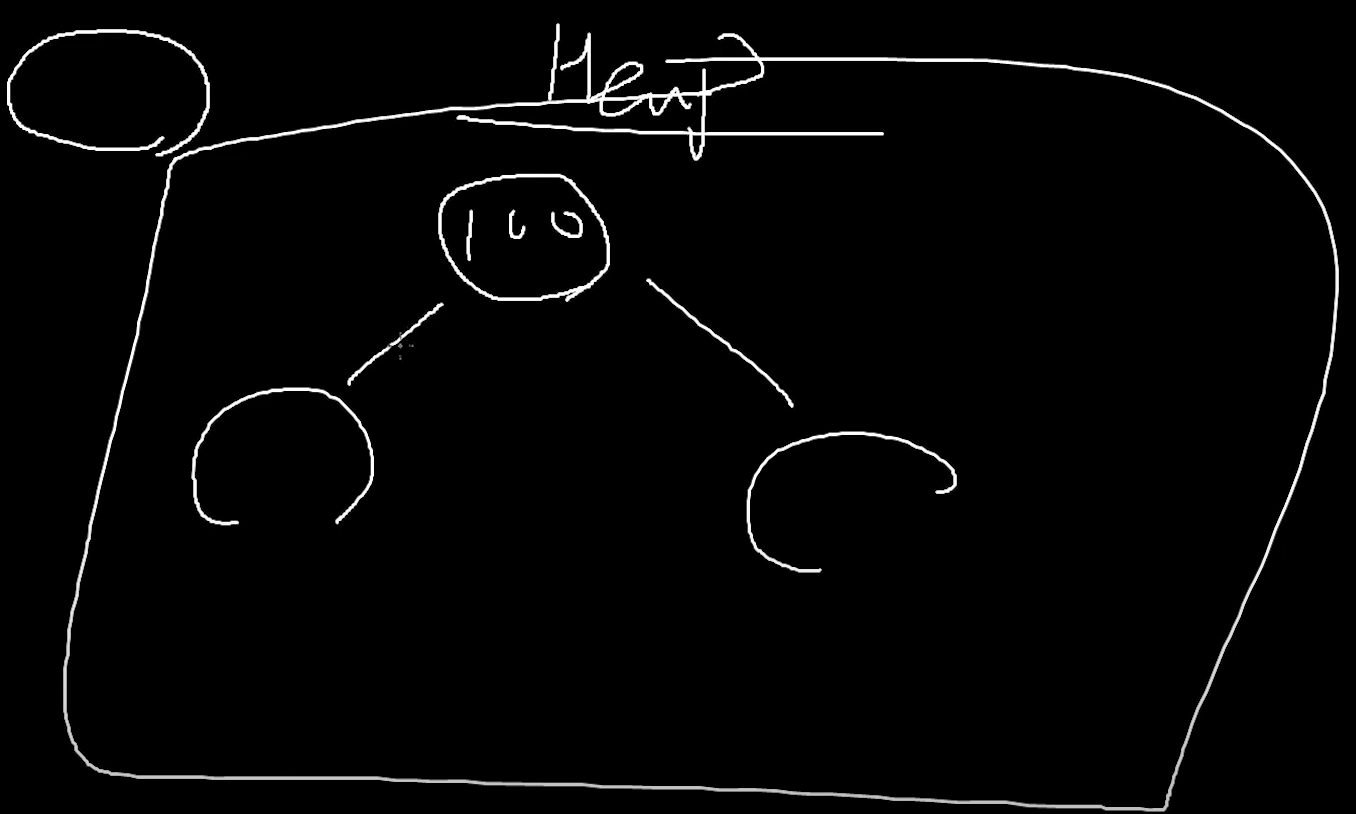
이런식으로 Heap안에 이렇게 들어 갈 것이다.
set보다는 map 사용많이함.
이렇게하면
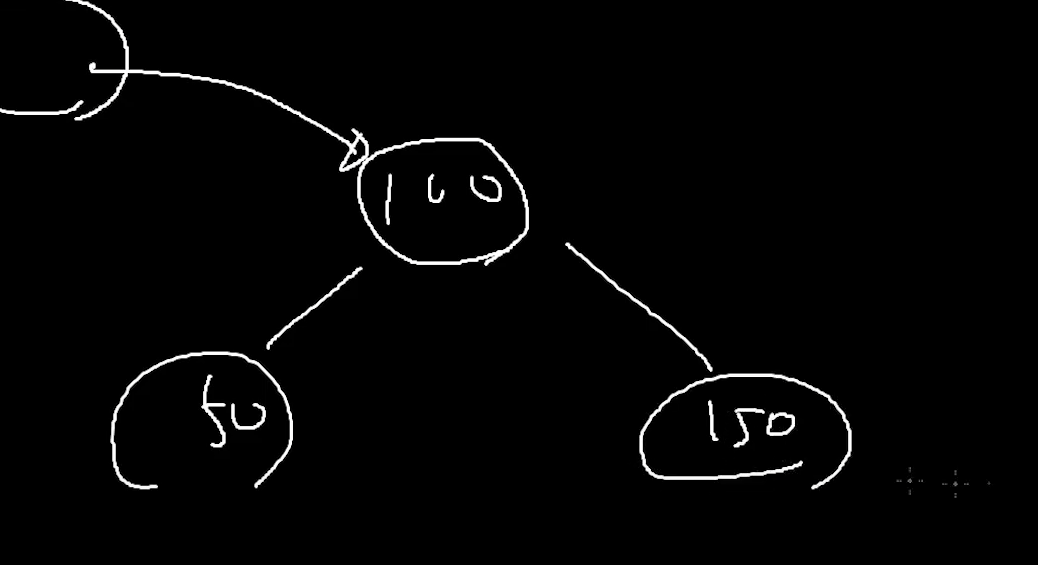
이런 그림인데
map은 typename을 두개를 지정한다.
두개의 int, float 중에 첫번째 타입인 int를 Key값
즉, 이진 탐색트리를 구성하는 애들의 비교를 하기 위해 사용을 한다.
float 두번째 녀석은 거기에 딸려있는 추가적인 데이터 타입을 말한다.
크기 비교를 하기위한 첫번째 인자이고
실질적으로
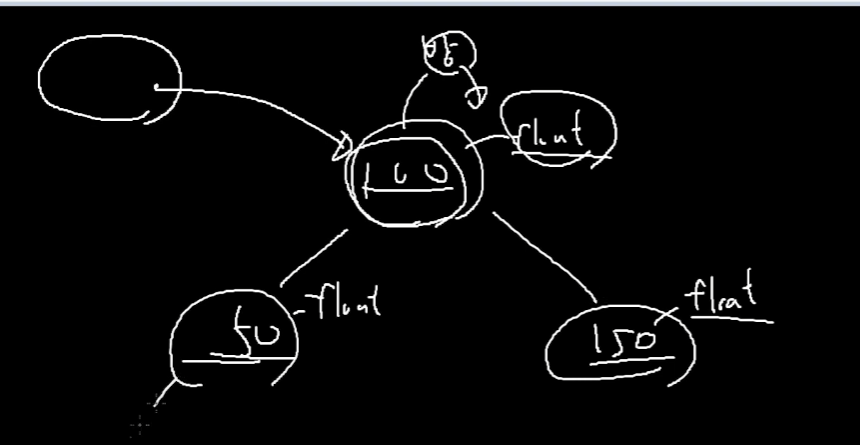
그 정수형 안에 들어있는 두번째 인자 float값이 중요한 값임.
이 값을 사용을 할 것이다.
먼말이고?
만약 비교하고싶은게 문자열이라고 할 경우.
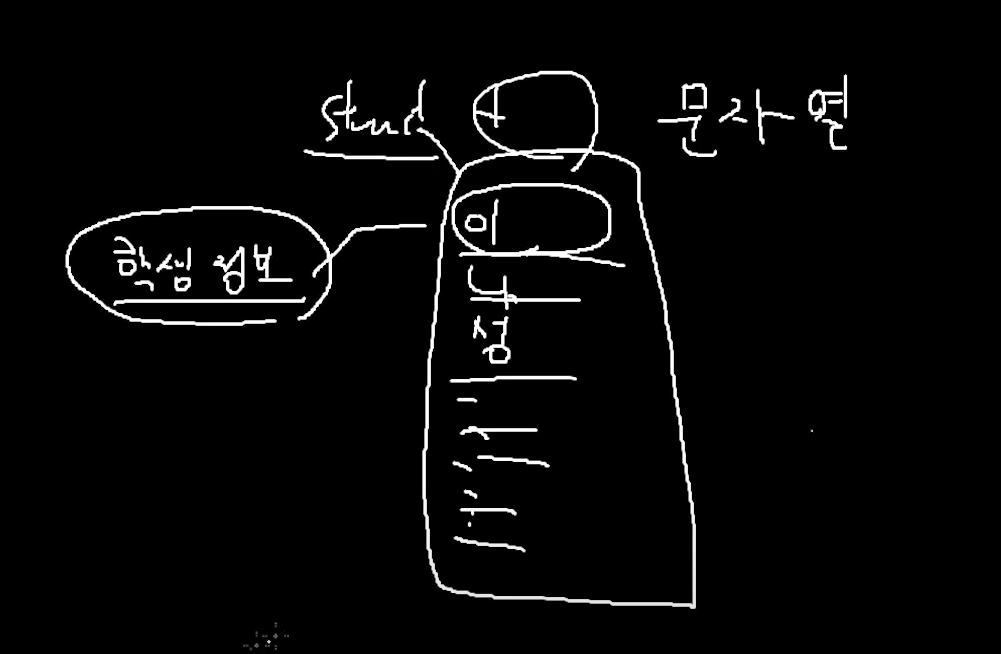
학생 이름, 나이, 성별 등등을 적은 구조체를 만들어서
이것들중에 키값을 고를 수 있지만 일단 "이름"을 키값으로 하도록 하자.
그러면 이것을 map을 사용한다면
map<학생이름, 정보(구조체)>
이런식으로 저장이 되는데 "학생 이름"을 기준으로 정렬이 될 것이다.
문자열도 비교가 가능함.
string.cmp
이러다보니까 키값과 안에 들어갈 데이터의 타입을 구분할 수 있기 때문에
map을 더 많이 사용하는 것이다.
또한
문자열의 ROM ❗
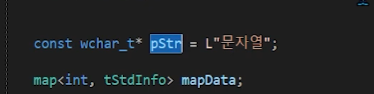
이렇게 문자를 받아 올 경우
어느 메모리라고 했나? => Read Only Memory라고 했다.
읽기 전용 메모리.
https://velog.io/@starkshn/CPP%EC%96%B4%EC%86%8C35%EB%AC%B8%EC%9E%90%EC%97%B4-1
이해가 안간다면 이부분 읽기
지금 사진에서
const wchar_t* ptr = L"문자열";에서 const붙인 이유는 읽기 전용 메모리이기도 하고
문자열은 "배열"이기 때문에 크기가 한정되어 있어서 크기를 바꿀 수 있는 경우를 배제하기 위해 const붙이는 것이다.
또한 읽기전용 메모리는 수정이 되면 안된다.
그렇기 때문에
ptr이 가르키는 값인 L"문자열" 이부분을 const로 바꿀 수 없게 한 것이다.
ㅇㅋ??
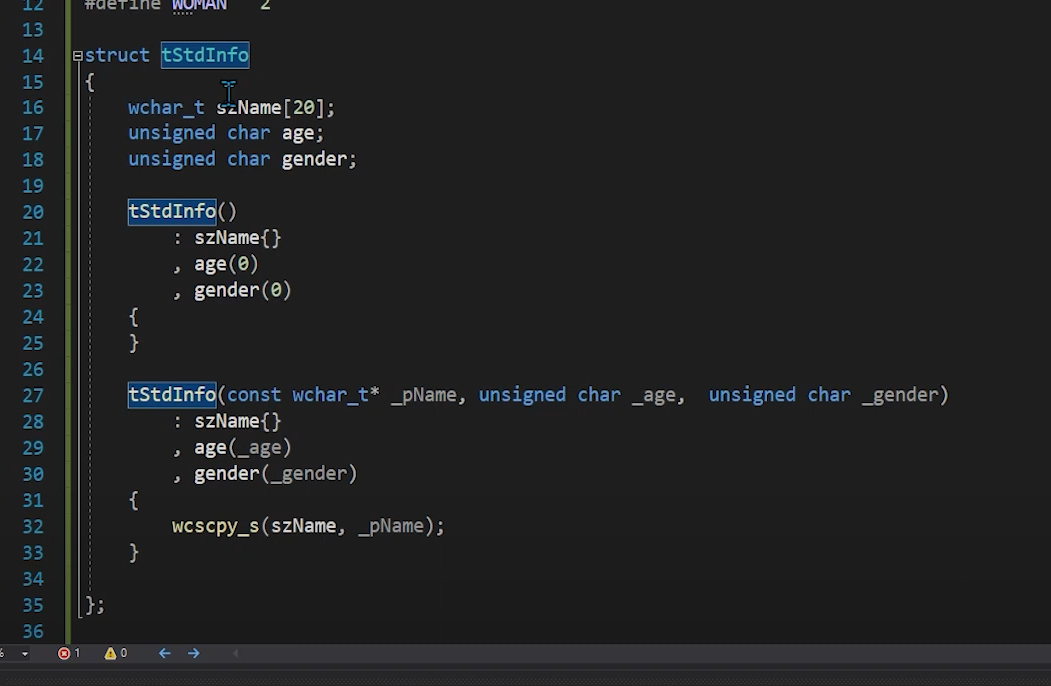
wcscpy_s 함수
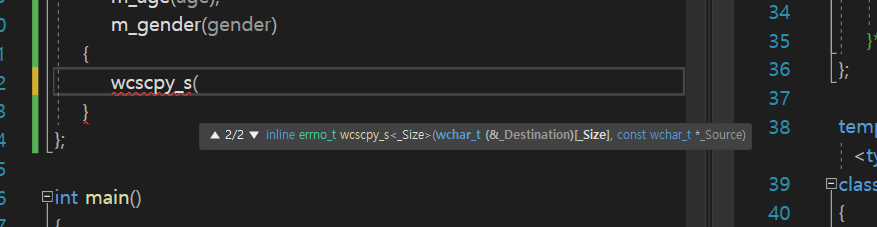
StdInfo 구조체 안에서 초기화작업을 할 때
배열을 초기화 할 수 없어서 초기화 인자로 들어온 문자열 주소를 직접
한땀한땀 넣어주기 위하여
wcscpy_s함수를 사용 할 것이다.
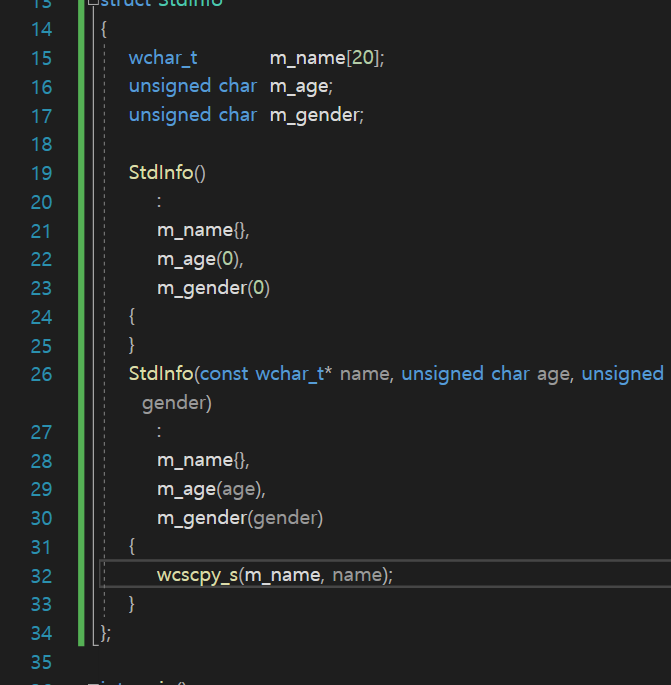
그래서 포인터 변수로 받아온 name을 Source부분에 넣어주도록 하자.
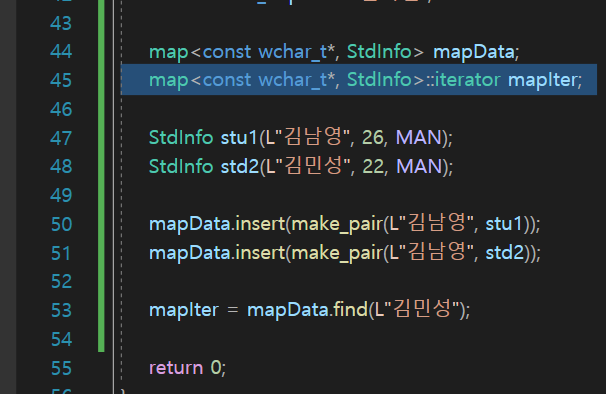
데이터 넣기
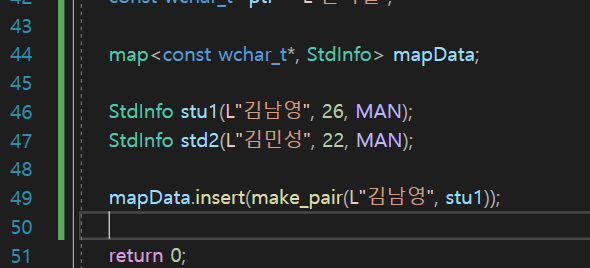
이렇게 StdInfo를 각각 인자를 넣어서 초기화를 해주고
지금 이름을 Key값으로 사용하기로 했으니까
insert해주는데
make_pair 라는 함수가
저 "김남영", stu1을 묶어서 하나의 짝으로 만드는 함수임.
짝으로 만들고 이것을 mapData에 insert해준다.
설명
노드안에
이런 문자열을 넣고
그다음에 실제 저장하고싶은 데이터를
이렇게 묶어서 하나의 pair로 보고
노드 안에는 그 pair가 있는 것이다.
즉,
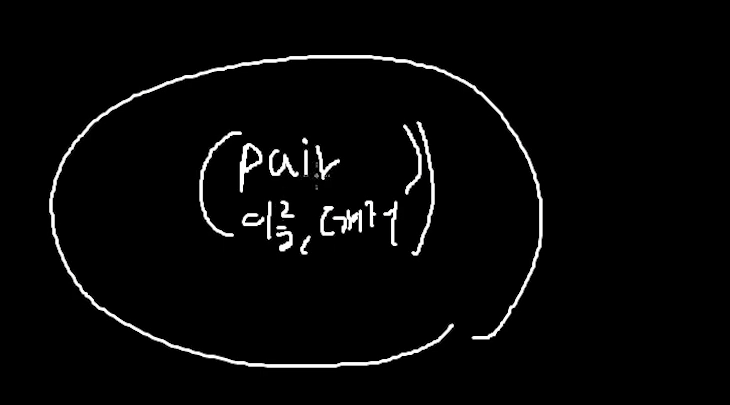
노드 안에 pair가 있는데 그 pair안에 이름과 데이터 파트가 있는 것이다.
pair를 만들어서 return 시켜주는 함수가 make_pair함수이고.
데이터 찾을 경우 ❗
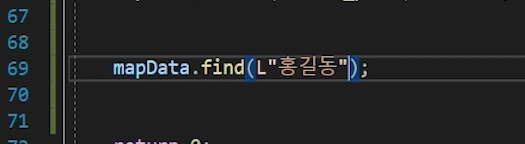
이렇게 Key값으로 사용하기로한 문자열의 시작 주소를 넣어준다.
그러면
find함수는 pair가 나온다.
둘이 묶어진게 나와서 데이터가 2개가 나온다.
그리고 찾았을 경우 데이터를 바로 주지 않고 iterator를 준다.
즉,
찾고자 하는 녀석의 iterator를 반환해서 준다.❗❗❗
뭐가? => find함수가
즉 iterator객체를 하나 생성을 해서
이녀석으로 find함수를 받아 와야한다.
이렇게 받아온 iterator가 가르키고있는게 이 pair이다.
make_pair(L"김남영", stu1); 이 짝임.
그리고 iterator는
마치 포인터인 것 처럼 동작하기 위해서
그러한 operator 들이 구현되어 있었다.
그렇다면 * 역참조 가능 🛫
그렇다면 우리가 역참조 연산을 사용함으로써
가르키고 있는 데이터를 접근 할 수 있다.
이전까지는 데이터 타입이 하나였는데 -> 접근하는 순간 그 데이터 타입을 바로 말하는 것인데
지금 이상황은 데이터 타입이 두개인데
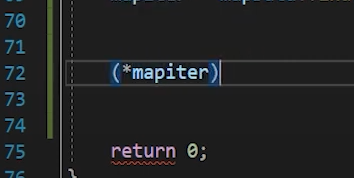
이렇게 접근을 하면 pair라는 구조체 형태이다.
이 구조체 형태의
첫번째 타입이 const wchar_t* 이고, 두번째가 StuInfo 인
그런 Pair가 나오는 것이다.
즉,
pair라는 구조체도
첫번째 타입이 < const wchar_t*, StuInfo > 이러한 타입의 "구조체"이다.
우리가 이렇게 만든 구조체가
find함수르 사용했을 때 나오는 pair라는 구조체 안에 들어가게 된다.
즉 pair의 멤버가 된다.
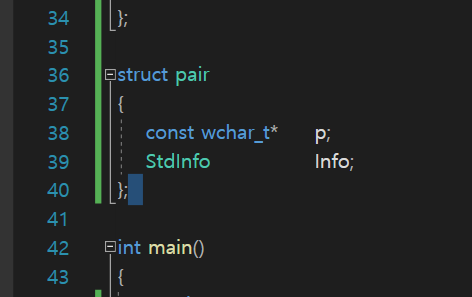
이런식의 구조체 가 있는 것임
이거는 그냥 예시로 만들어놓은 first, second이고
실제로 map의 멤버 변수 이름이 first, second이다.
-> 연산자 ❗
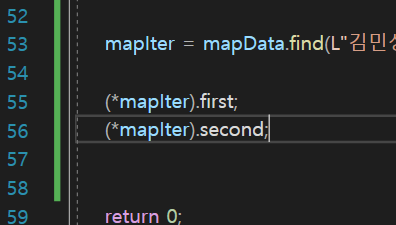
포인터를 역참조해서 그 구조체의 멤버로 들어가는 연산자를
축약해서 '->' 로 배웠다! 기억 ㄱㄱ.
mapIter->first;
mapIter->second;이렇게 가능한게 operator overloading을 해놓아서 가능한거임.
탐색한 데이터가 존재 하지 않을 경우
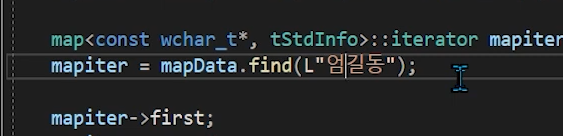
이렬경우 iterator의 상태는 "유효하지 않은 iterator"이다.
m_i_valid = false // 이겠지?찾았는데 없다면 -> 프로그램이 터져야 하나? (ㄴㄴ)
ㄴㄴ -> 없다면 충분하게 대처 할 수 있도록 코드가 작성 되어야한다.
되돌아온 iterator가 쓸 수 없는 iterator이면 안되고
end iterator가 나와야한다.
find => end iterator 반환되면 "아 내가 찾을라는게 없구나"
ㅇㅋ?
