
BST
오늘 배웠던거 ❗❗❗❗❗
모든 데이터는! 포인터 변수도 포함!
BstNode<T1, T2>* pNode = m_rootNode;| 주소 | 변수명 | 값 |
|---|---|---|
| 0x1234 | m_rootNode | 0x1000 |
| 0x2345 | pNode | 0x1000 |
'=' 대입연산자는 "값"을 전달해 주는 것이다❗❗
큰 구조 짜기
#pragma once
#include <iostream>
#include <assert.h>
template <typename T1, typename T2>
struct Pair
{
T1 first;
T2 second;
};
template <typename T1, typename T2>
struct BstNode
{
Pair* pair;
BstNode* parentNode;
BstNode* left;
BstNode* right;
};
template <typename T1, typename T2> // T1 키값, T2 실제 데이터를 가질 부분
class CBST
{
private:
BstNode* m_parentNode; // root 노드 주소
int m_dataCount; // 데이터 갯수
};구조는 대충 이정도..??
생각 ㄱㄱ
class CBST가 이진 탐색 트리 말하는거임.
insert함수 ❗
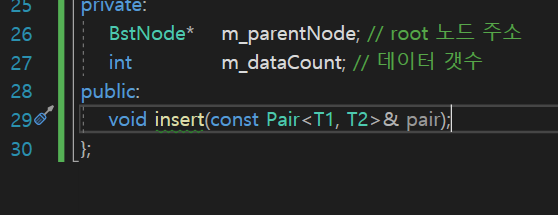
지금 Pair를 받는데
이 Pair는
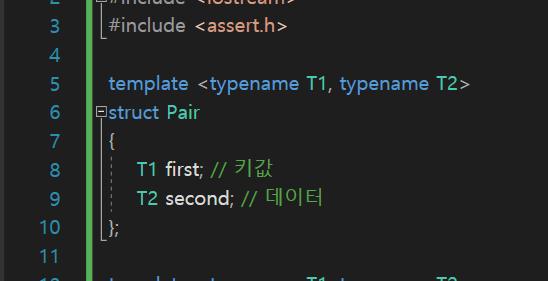
이녀석이다.
first가 키값, second가 데이터인 Pair 구조체임.
그러면 이 Pair를 받으면
Pair를 저장할 수 있는 "노드"를 "동적할당"해서 하나 만든 다음에
이 동적할당하여 만든 노드의 멤버 변수로 Pair의 주소값을 복사해서 들고있고,
비교 계산을 통해서(노드가 어디에 들어갈지에 따라서) 부모, 왼쪽, 오른쪽 자식을
연결해주는 형태이다.
insert 구현
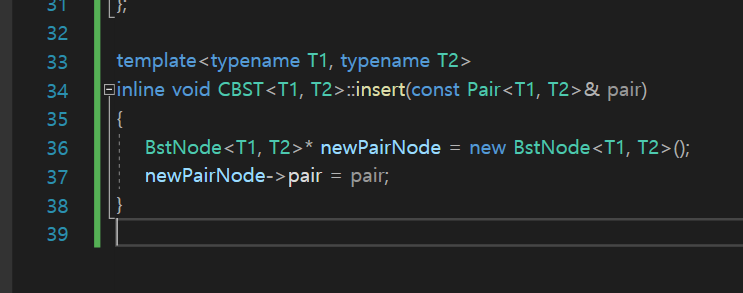
이렇게하면 새로운 노드는 채워졌다.
이상한? 점? 궁금한점
지금 노드에서 멤버 변수로 Pair를 들고있는데 Pair* 를 들고있어야하는거 아닌가?
둘다 말이 되는데
- 그냥 Pair를 멤버변수로 노드에 들고 있을 경우
newPairNode->pair = pair;하면 새로 동적 할당된 힙 메모리의 주소 구조체안에 이 pair를
인자로 넘겨받은 pair의 구조체를 "복사" 하지 않나?
그러면 효휼이 조금 낮지 않나?
- Pair* 를 멤버 변수로 노드에 들고있는 경우
현재 const Pair
const Pair<T1, T2>& pair 로 넘겨받은 이 녀석(pair)의 주소값을
동적할당 하여 만든 newPairNode의 pair에다가 넘겨주면
1. 번과 달리 주소를 넘겨주는 방식이니까 1번보다 더 효율적인 측면에서 좋지 않나?
루트노드가 아닐 경우
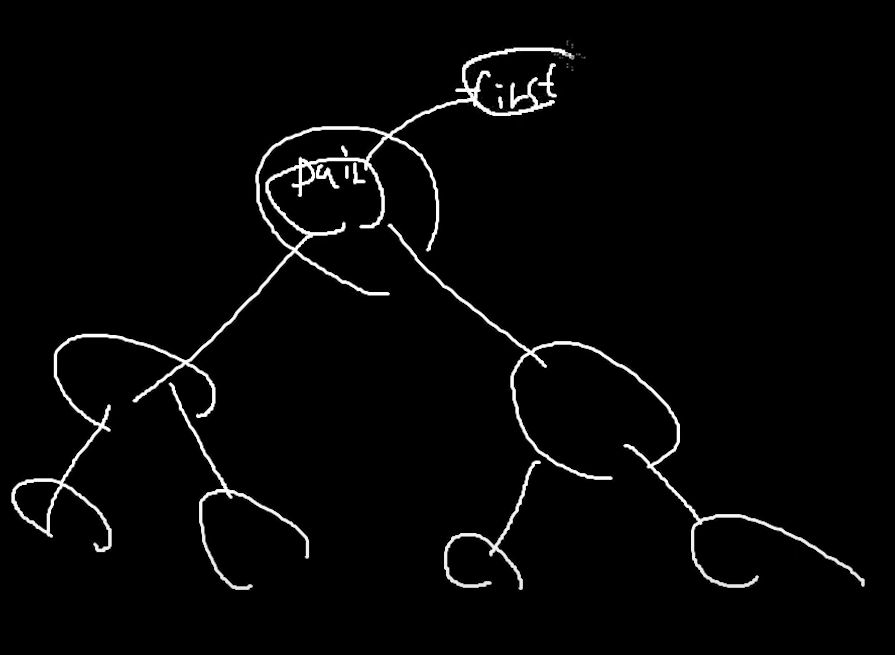
pair 랑 새로 생성된 노드 안의 pair의 first와 비교를 해서
누가 큰지 작은지를 봐야함.
오른쪽이든 왼쪽이든 노드가 없을 때까지 계속해서 반복을 해서 내려가야한다.
pair의 first가 같을 경우 ❓
왼쪽으로 갈지 오른쪽으로 갈지 답이 없어진다...
그래서 map에서도
중복값을 하용하는 map은 multimap이라고한다.
일반적인 map은 허용하지 않고 "무시"해버린다.
그래서 내가 map안에다가 데이터를 넣었다고 착각 할 수 있다.
find해서 동일한 key값이 있는지 체크를 해주어야한다.
multimap의 해결방법
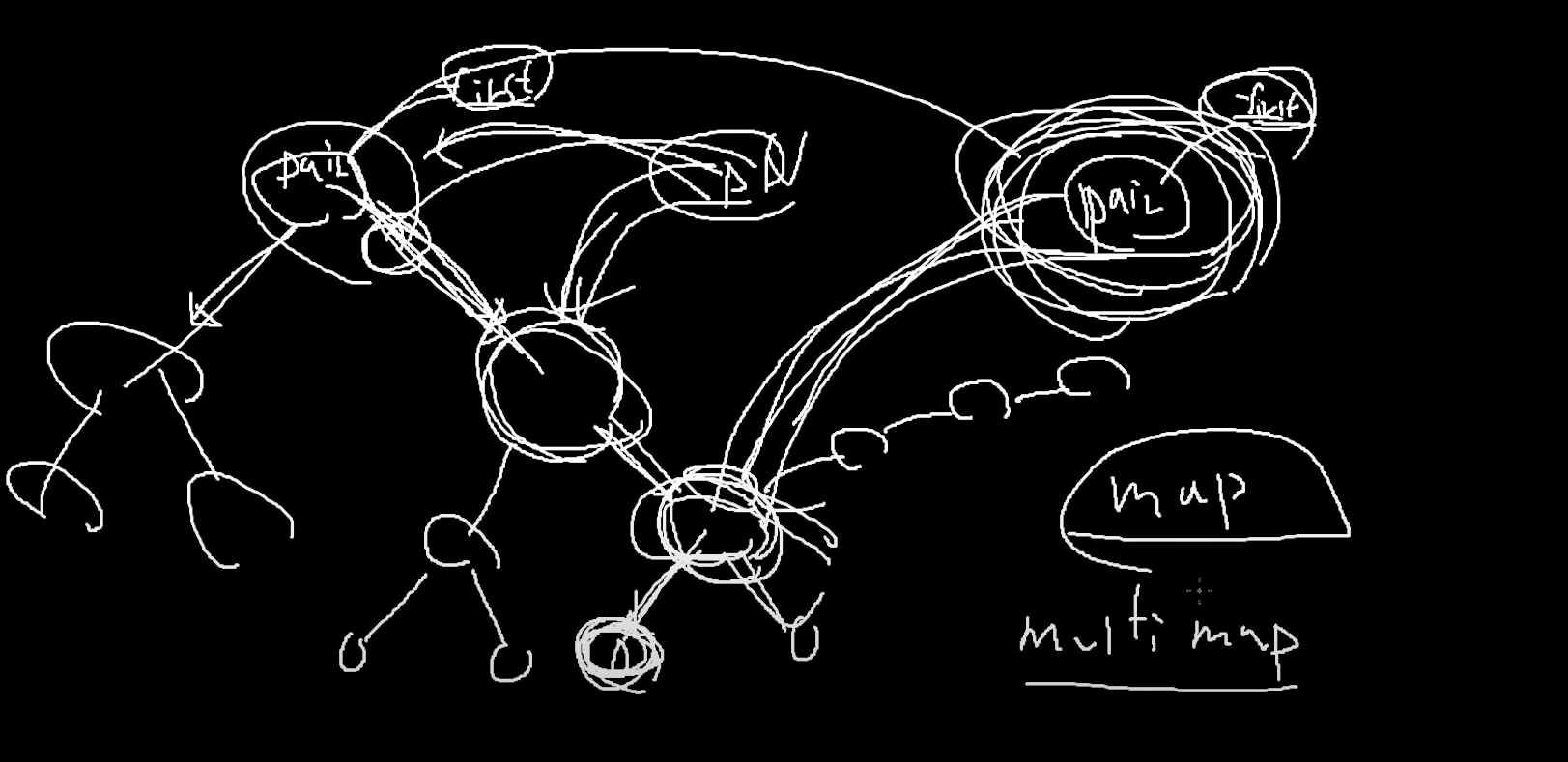
오른쪽 세번째에서 중복키값 발생하면
그곳에서부터 주렁주렁 리스트로 연결한다.
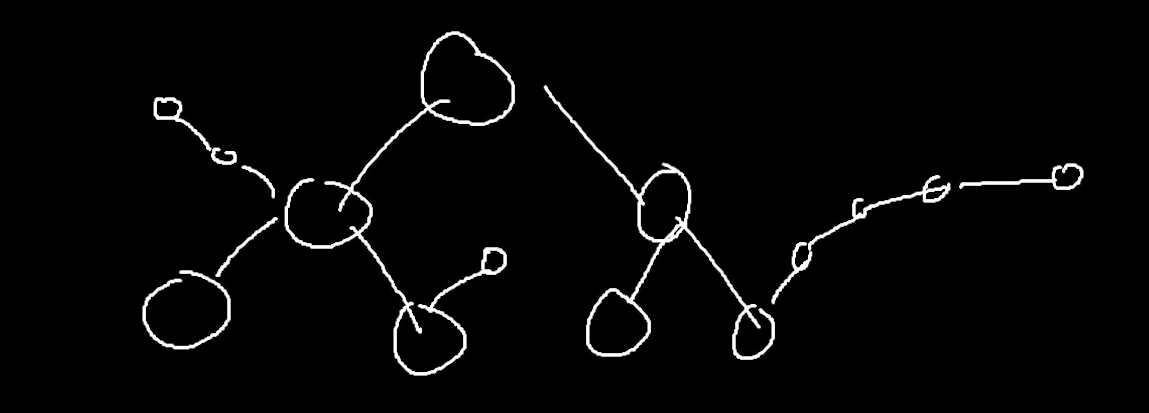
이런식으로 파생되서 나간다.
이러면 이진 탐색 트리로서의 탐색 효율이 극도로 떨어진다.
insert 다시 구현
template<typename T1, typename T2>
inline bool CBST<T1, T2>::insert(const Pair<T1, T2>& pair)
{
BstNode<T1, T2>* newNode = new BstNode<T1, T2>();
newNode->pair = pair;
newNode->parent = nullptr;
newNode->left = nullptr;
newNode->right = nullptr;
// 루트노드가 없을 경우
if (nullptr == m_rootNode)
{
m_rootNode = newNode;
}
else // root Node가 아닐 경우
{
// 훼손될 가능성을 없애기 위한 지역변수
CBST<T1, T2>* tempRootode = m_rootNode;
if (tempRootode->pair.first < newNode->pair.first)
{
tempRootNode = tempRootNode->right;
}
else if(tempNRootode->pair.first > newNode->pair.first)
{
tempRootNode = tempRootNode->left;
}
else // 같을 경우
{
return false;
}
}
// 데이터 증가
++m_dataCount;
return true;
}일단 이게 한 싸이클이다.
우리가 이제 이부분을 while문돌면서
while (true)
{
if (pNode->pair.first < newNode->pair.first)
{
if (nullptr == pNode->rightNode)
{
pNode->rightNode = newNode;
newNode->parentNode = pNode;
break;
}
else
{
pNode = pNode->rightNode;
}
}
else if (pNode->pair.first > newNode->pair.first)
{
if (nullptr == pNode->leftNode)
{
pNode->leftNode = newNode;
newNode->parentNode = pNode;
break;
}
else
{
pNode = pNode->leftNode;
}
}
else // 같을 경우
{
return false;
}
}이렇게 확인 할 것이다.
아 그리고 참고로
이 링크 무조건 읽으셈❗❗❗❗❗
