
enum

TYPE_5 = 100 이면
TYPE_6은 101부터 다시 시작
( C#도 똑같다 이부분은 )
모호해질 경우
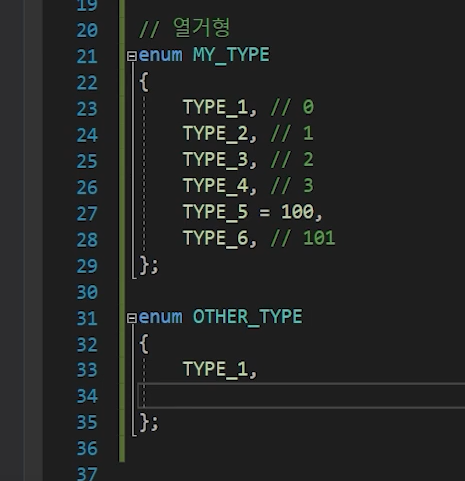
어느쪽 TYPE_1을 얘기하는지 모호함.
그래서 이러한 모호한 문제를 해결하기 위해서
enum class ❗
enum class My_Type
{
type_1,
type_2,
type_3,
};
enum class Other_Type
{
type_1,
type_2,
type_3
};
// 사용할 경우
int a = (int)My_Type::type_1;
// 이렇게 명시 해주어야한다.이렇게 하면 구별이 되어서 모호한게 없어짐.
또한 정수형으로 사용할려면 (int)로 명시적으로 캐스팅 해주어야함.
"어떤 기능을 제한하는 것도 기능이다"
전처리기와의 차이점??
#define CLASS_1 0
#define CLASS_2 1
#define CLASS_3 2
#define CLASS_4 3
#define CLASS_5 4
int main()
{
int a = CLASS_1;
return 0;
}이렇게하면 enum || enum class와 굉장히 유사하지 않나?
그러면 차이가 뭐냐?
이 "전처리기" #define 에 주목을 해야한다.
전처리기란❓
컴파일이 되기 이전에 먼저 실행이 되는 것이다.
따라서 main함수 내의 int a 의 값에는 1이 적혀있는 상태인 것이다.
그러면 만약
enum class My_Type
{
type_1,
type_2,
type_3,
};
int main()
{
int a = (int)My_Type::type_1;
return 0;
}이렇게
int a = (int)My_Type::type_1;해준다면 enum이라는 "정보 자체"가 (My_Type이라는)
"심볼" 테이블에 남는다.
그러면 "디버깅"을 할 때 a에다가 단순히 0을 집어 넣었다고 생각하지 않고
컴파일러가 My_Type 이라는 enum타입에 있는 type_1의 값을 넣었다라고 생각을 한다.
나중에 디버깅 할 경우 어떠어떠한 타입을 넣었다고 알 수가 있다.
그런데 전처리기 사용하면...??
=> 컴파일러가 못잡겠지... ㅇㅋ? ㅇㅋ.

https://cjbworld.tistory.com/ <- 이사중