
배운거
-
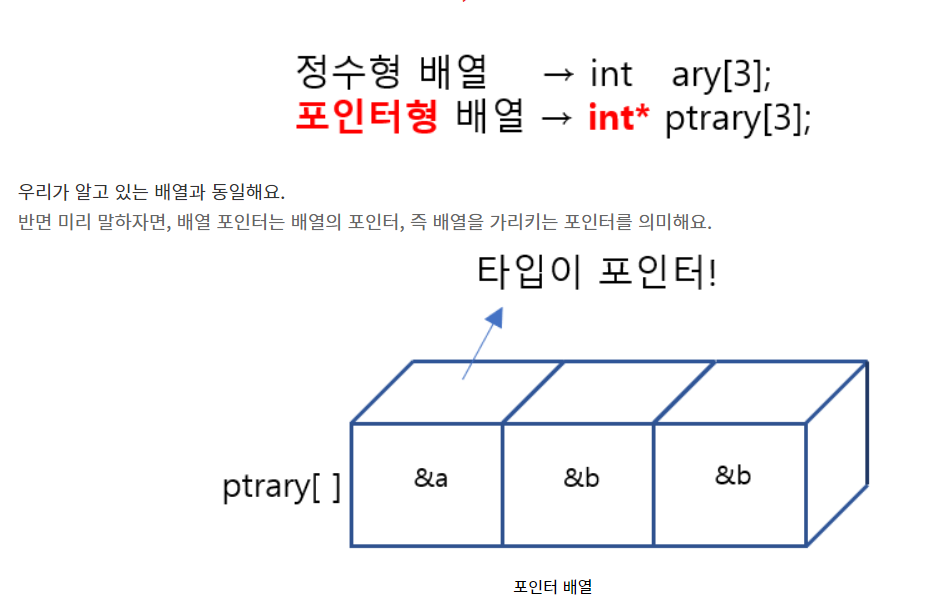
포인터 배열
-
enum, enum class 다른점 (모호성)
#pragma once
#include <iostream>
#include <assert.h>
enum class NodeType
{
PARENT,
LCHILD,
RCHLID,
END,
};
template <typename T1, typename T2>
struct Pair
{
T1 first; // 키값
T2 second; // 데이터
};
template <typename T1, typename T2>
struct BstNode
{
Pair<T1, T2> pair;
BstNode* nodeArr[(int)NodeType::END];
BstNode()
:
pair(),
nodeArr{}
{
}
BstNode(const Pair<T1, T2>& pair, BstNode* parentNode, BstNode* leftNode, BstNode* rightNode)
:
pair (pair),
nodeArr { parentNode, leftNode, rightNode }
{
}
};
template <typename T1, typename T2> // T1 키값, T2 실제 데이터를 가질 부분
class CBST
{
private:
BstNode<T1, T2>* m_rootNode; // root 노드 주소
int m_dataCount; // 데이터 갯수
public:
CBST()
:
m_rootNode(nullptr),
m_dataCount(0)
{
}
public:
bool insert(const Pair<T1, T2>& insertPair);
};
template<typename T1, typename T2>
inline bool CBST<T1, T2>::insert(const Pair<T1, T2>& insertPair)
{
BstNode<T1, T2>* newNode = new BstNode<T1, T2>(insertPair, nullptr, nullptr, nullptr);
// 루트노드가 없을 경우
if (nullptr == m_rootNode)
{
m_rootNode = newNode;
}
else // root Node가 아닐 경우
{
// rootNode가 훼손될 가능성을 없애기 위한 지역변수 (루트는 고정되어야 하기 때문에)
BstNode<T1, T2>* pNode = m_rootNode;
// 가야할 방향 (오른쪽인지 왼쪽인지)를 enum으로 정해주자
NodeType nodeType = NodeType::END; // 아직 갈 방향 안정해서 END로 놔둠.
while (true)
{
if (pNode->pair.first < newNode->pair.first)
nodeType = NodeType::RCHLID;
else if (pNode->pair.first > newNode->pair.first)
nodeType = NodeType::LCHILD;
else
return false;
if (nullptr == pNode->nodeArr[(int)nodeType])
{
pNode->nodeArr[(int)nodeType] = newNode;
newNode->nodeArr[(int)NodeType::PARENT] = pNode;
break;
}
else
pNode = pNode->nodeArr[(int)nodeType];
}
}
// 데이터 증가
++m_dataCount;
return true;
}
BST
바뀐점
-
enum, enum class 개념 -> 활용
-
포인터 배열을 사용하여 인덱스 번호에 접근
-
enum class 를 사용하여 포인터 배열의 주소와 인덱스 접근이 가능하게 만듦.
포인터 배열
https://jhnyang.tistory.com/344
find 함수 구현
find구현을 하려면 iterator있어야한다.
iterator
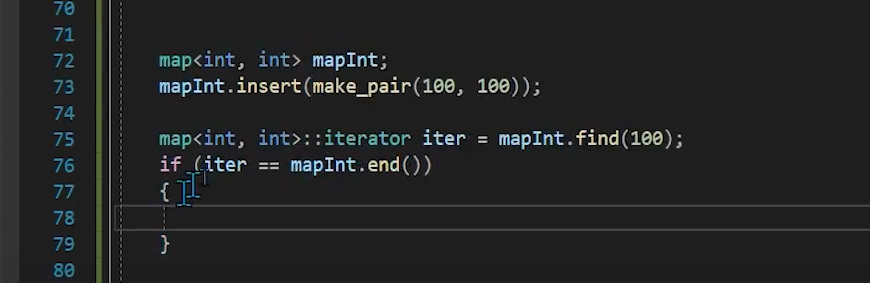
find해서 만약 안나온다면
end() iterator를 돌려주어야한다 (프로그램이 터지면 안됨)
make_pair함수
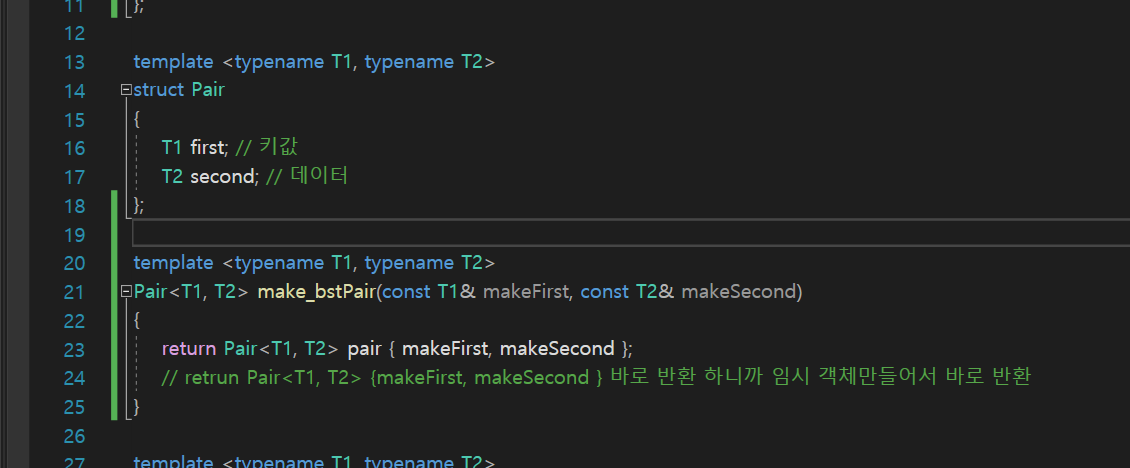
직접 pair를 구현을 하지 않고 함수를 사용하여 전달하기 위하여 만든 함수임.
그러면
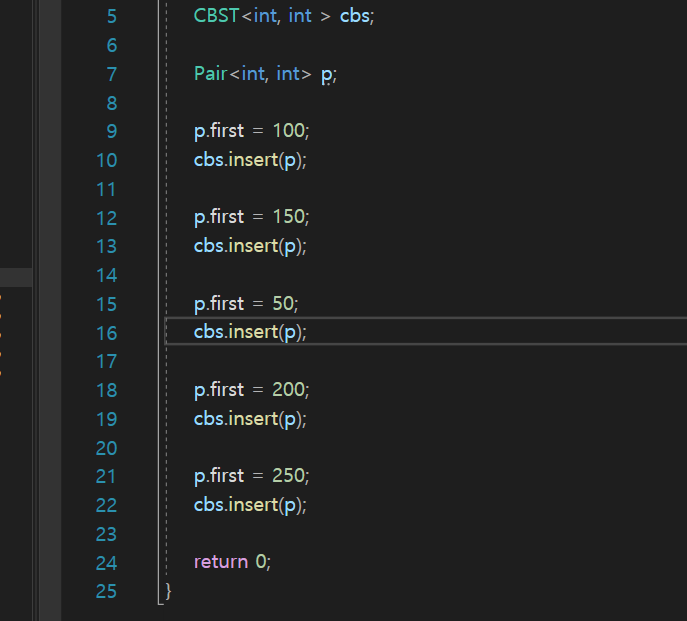
이했던 부분이
cbs.insert(make_bstPair(100, 0));
cbs.insert(make_bstPair(150, 0));
cbs.insert(make_bstPair(50, 0));이런식으로 줄어듦.
begin() 구현 && 중위순회 ❗❗❗
이진 탐색 트리는 -> "중위 순회" 기준으로
탐색한다.
begin은 시작인데 중위 순회 기준으로 첫번째를 반환해야함.
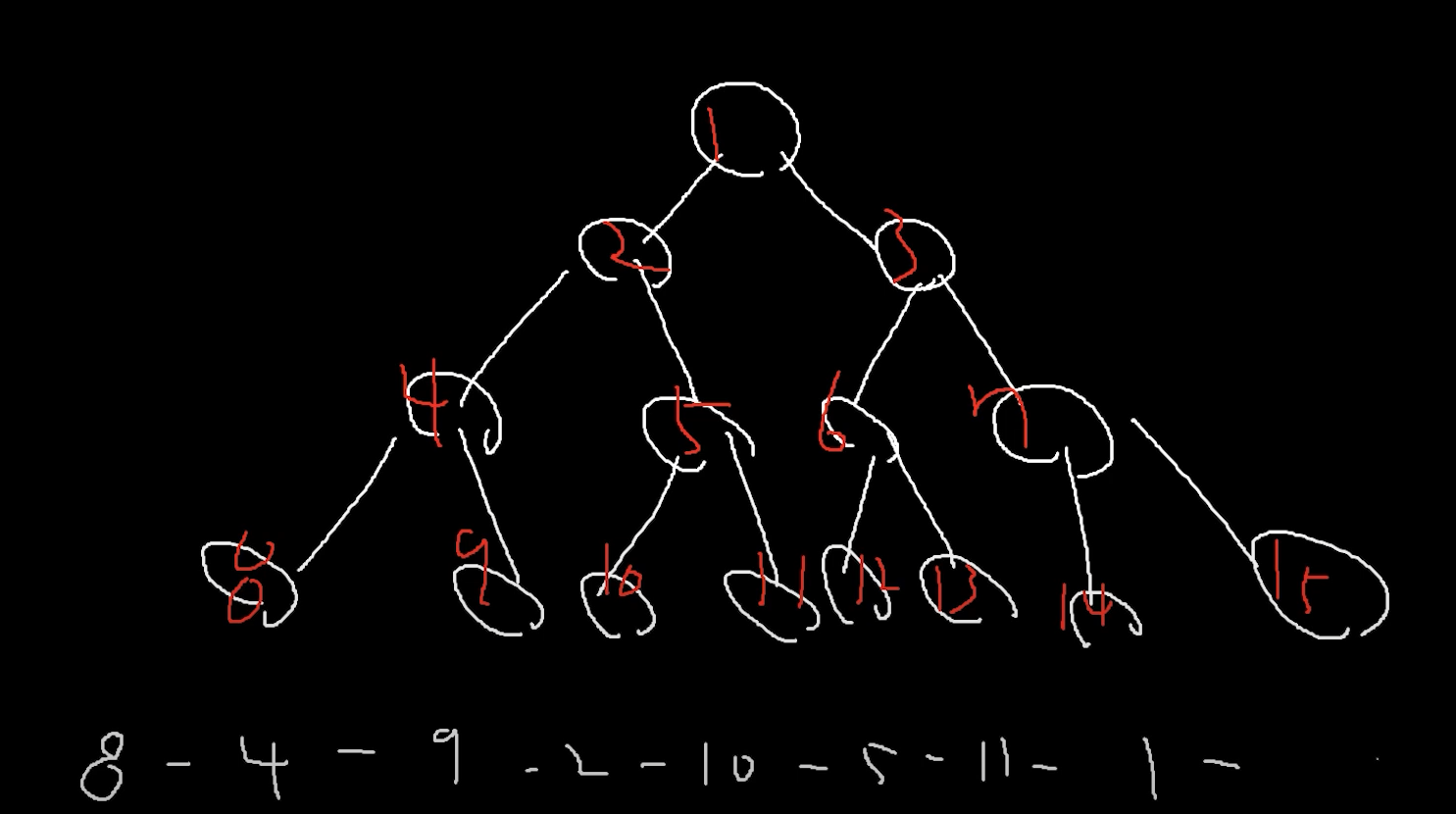
이런순서임 그 다음 12 - 6 - 13 - 3 - 14 - 7 - 15
end() 구현
find() 구현

find함수는 마찬가지로 iterator를 반환을 해줄 것인데
내가 찾고자 하는 데이터를 보유하고있는 "노드"를 가르키는 iterator를
만들어서 반환을 해줄 것이다.
template <typename T1, typename T2>
inline typename Cbst<T1, T2>::iterator Cbst<T1, T2>::findData(const T1& find)
{
// rootNode가 훼손될 가능성을 없애기 위한 지역변수 (루트는 고정되어야 하기 때문에)
BstNode<T1, T2>* pNode = m_rootNode;
// 가야할 방향 (오른쪽인지 왼쪽인지)를 enum으로 정해주자
NodeType nodeType = NodeType::END; // 아직 갈 방향 안정해서 END로 놔둠.
while (true)
{
if (pNode->pair.first < find)
nodeType = NodeType::RCHLID;
else if (pNode->pair.first > find)
nodeType = NodeType::LCHILD;
else
{
// 찾은 경우
return iterator(this, pNode);
}
if (nullptr == pNode->nodeArr[(int)nodeType])
{
// 못찾은 경우
return end();
}
else
{
pNode = pNode->nodeArr[(int)nodeType];
}
return iterator();
}
}
현재는 insert가 이런데 while문 안에서 무조건 return 이 되긴 할껀데
마지막에 저렇게 return 하는 부분이 있다면 오류 날 수도있다.
그래서
template <typename T1, typename T2>
inline typename Cbst<T1, T2>::iterator Cbst<T1, T2>::findData(const T1& find)
{
// rootNode가 훼손될 가능성을 없애기 위한 지역변수 (루트는 고정되어야 하기 때문에)
BstNode<T1, T2>* pNode = m_rootNode;
// 가야할 방향 (오른쪽인지 왼쪽인지)를 enum으로 정해주자
NodeType nodeType = NodeType::END; // 아직 갈 방향 안정해서 END로 놔둠.
while (true)
{
if (pNode->pair.first < find)
nodeType = NodeType::RCHLID;
else if (pNode->pair.first > find)
nodeType = NodeType::LCHILD;
else
{
// 찾은 경우
break;
}
if (nullptr == pNode->nodeArr[(int)nodeType])
{
// 못찾은 경우
pNode = nullptr;
break;
}
else
{
pNode = pNode->nodeArr[(int)nodeType];
}
return iterator(this, pNode);
}
}break;로 바꿔줄 수도 있다.
또한 pNode = nullptr;로 해주고 break; 한 다음에
return 해주어도 end()랑 같은 의미이니까 ㄱㅊ을듯.
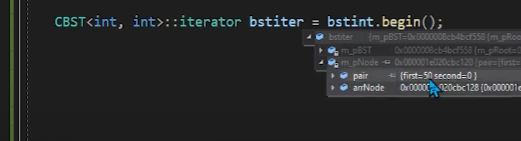
being은 제일 왼쪽이니까
잘 작동한다.
find 테스트
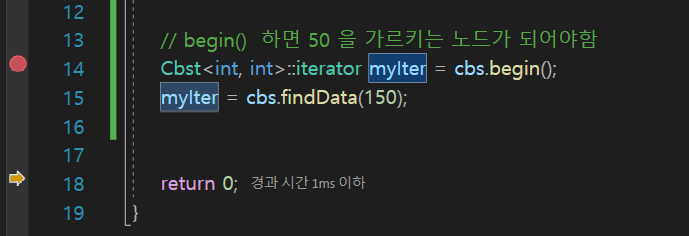
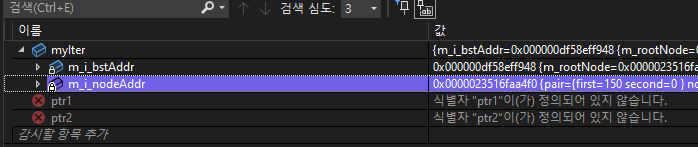
지금 pair의 first보면은 150이다.
굿굿

https://cjbworld.tistory.com/ <- 이사중