INDEX는 중요도를 평가할 수 없을 정도로 너무너무 중요하다.

책 후반이나
초반에 "색인 == INDEX"를 찾으면 쉽게 찾을 수 있다.
그런데 책은 한번 출판하면 바뀌지가 않는데
데베는 수정도되고 바뀌기도 하니까 실시간으로 페이지가 왔다갔다 할 테니까

그래서 데베에서는 실제로 "이진 검색 트리"를 사용한다.
트리를 만들어서 현재 값보다 작으면 왼쪽으로
현재값보다 크다면 오른쪽으로 가는것임
그래서 이진트리를 알아보기보다는
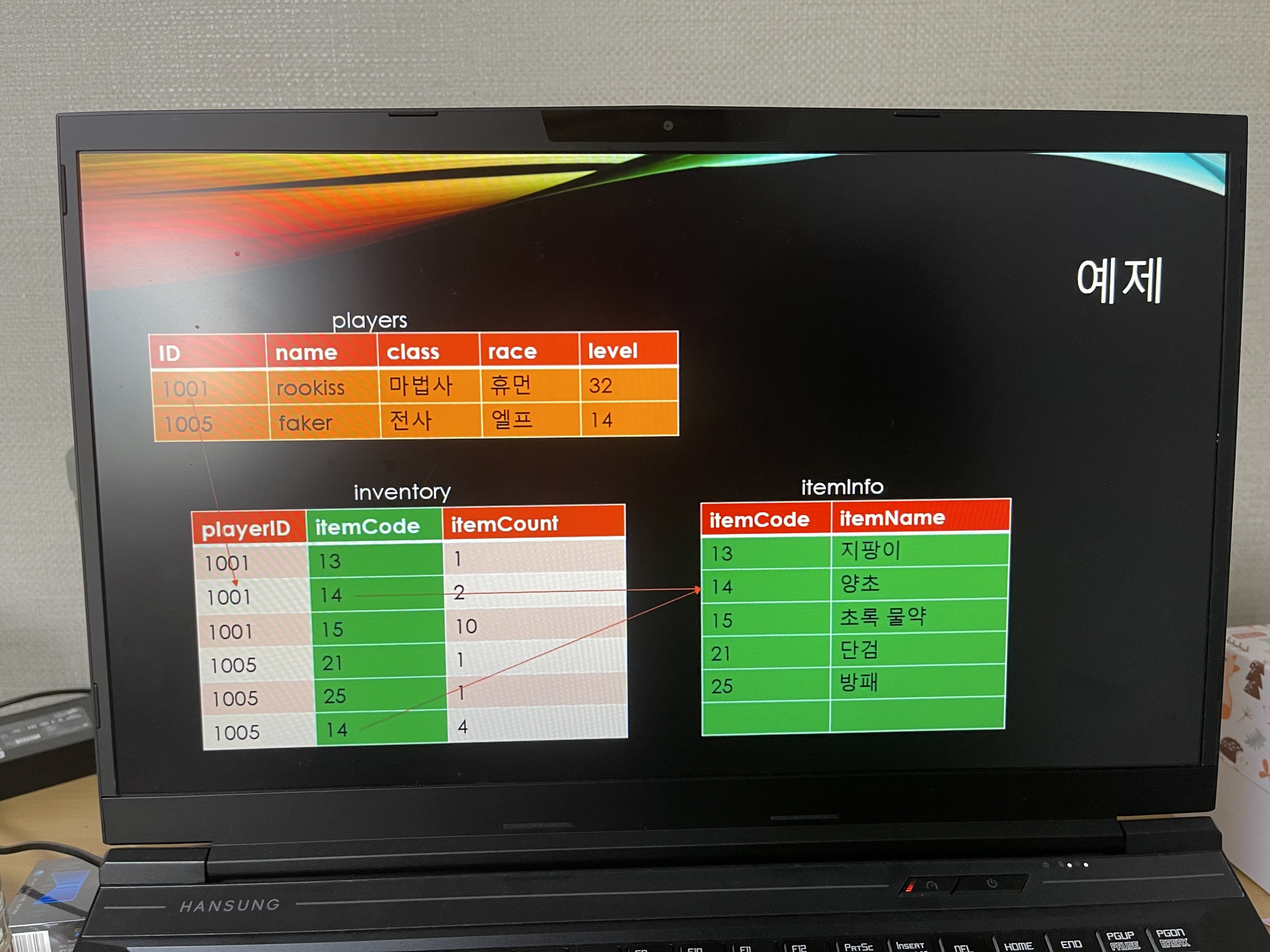
이렇게 테이블이 있을 때
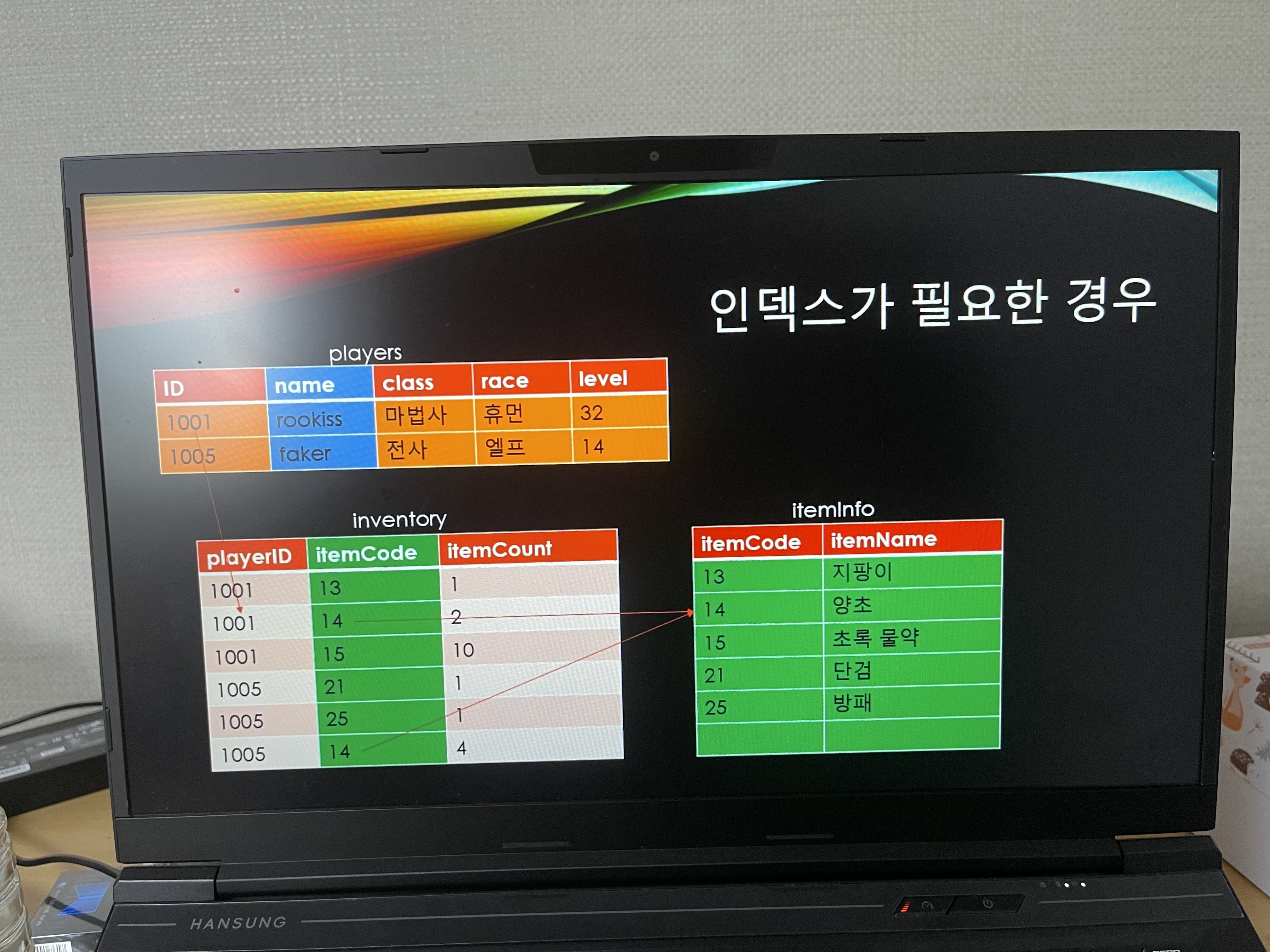
뭐를 인덱스로 할지 생각을 해야한다. ID, name은 인덱스를 걸면 좋지만
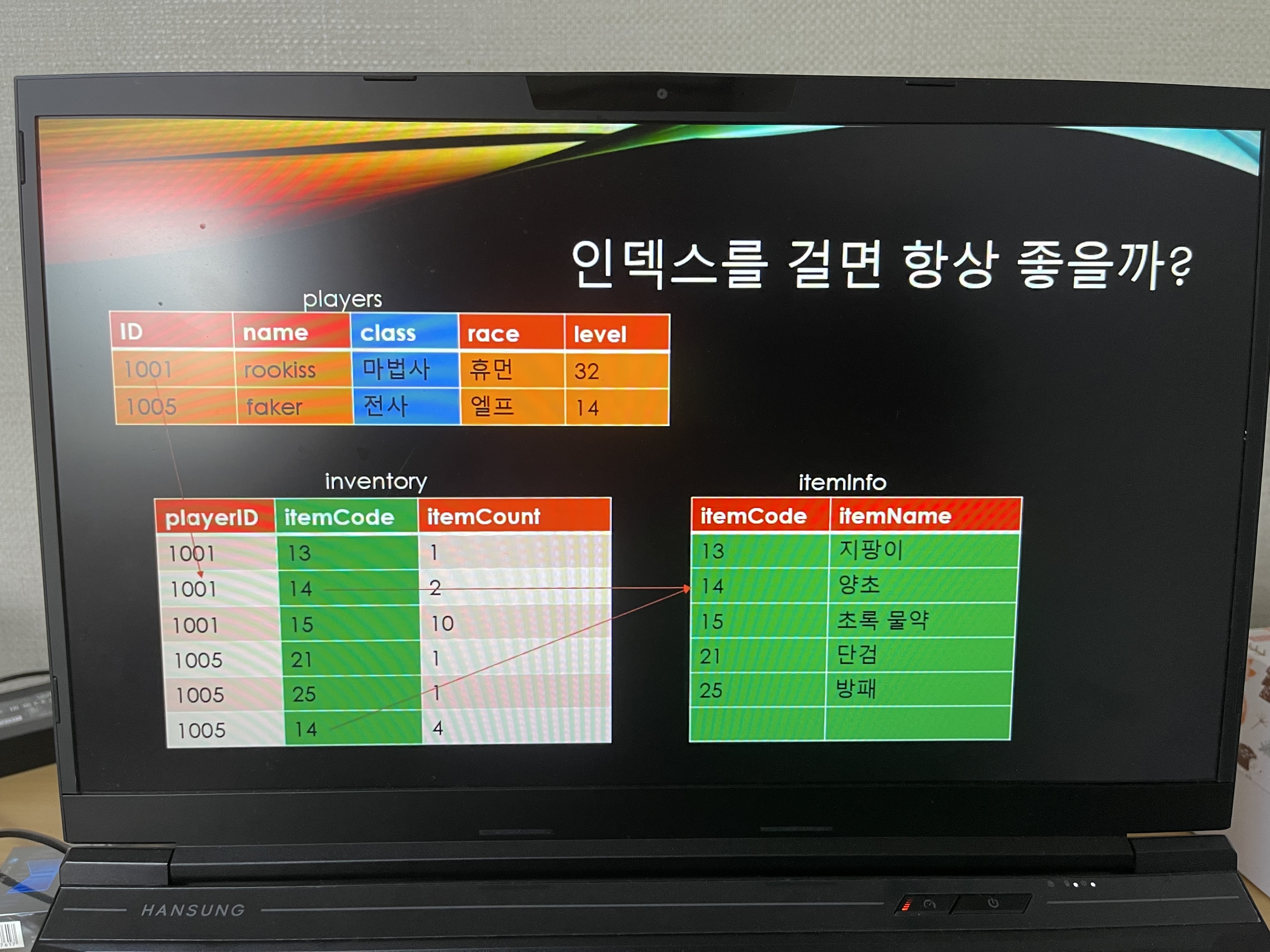
이렇게 class같은데다가도 인덱스를 걸면 좋지가 않다.
왜냐하면 마법사를 찾았을때 해당하는 유저들의 정보가 엄청 많이 나올 수도 있기 때문이다.
색인을 한 이유가 없어진다(직업이 마법사 인경우가 많을테니까)
INDEX는 CLUSTERED && NON-CLUSTERED INDEX 두가지 종류가 있다.


CLUSTERED INDEX는 영한사전을 생각하면 좋다.
데이터를 저장을 할때부터 순서에 맞게 한것이다.
이것을 영어 순서대로 하세요 & 단어길이 따라 배열을 또 하세요 는 말이 안된다 (왼쪽을 보면서 오른쪽을 보세요 와 같다)
요약을 하자면

그래서 SQL상에서 INDEX만들어보고 삭제하는 작업 해보도록 하자.
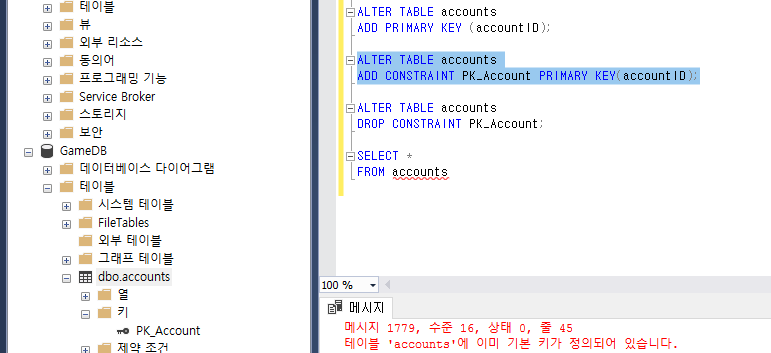
일단 이부분 실행해주고 보면 키가 잘 걸려있다.
그래서 PRIMARY KEY도 CLUSTERED INDEX라 했는데
이것을 보면은
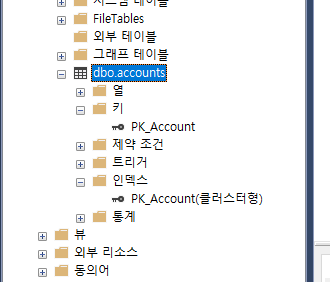
이렇게 CLUSTERED라고 잘 되어있다.
PRIMARY KEY는 고유성을 보장하고 이녀석 자체를 키로 사용하겠다는 의미이다.
그리고
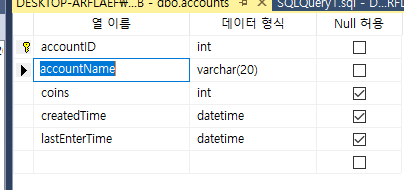
이런 accountName같은 경우에는 충분히 INDEX를 걸어 줄 수 있는데
만약 백만명의 유저가 있다고 했을 때
회원가입을 하고 닉네임을 만들때 중복이 되는지 안되는지 살펴봐야하는데
INDEX를 걸어주지 않는다면 백만번을 다 searching해서 찾아야 할 것이다.
그래서 INDEX를 걸어줘서 보다 빠르게 중복체크를 할 수 있도록 해야한다.
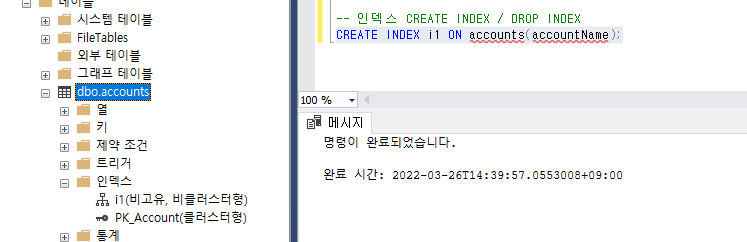
이렇게 만드러 줄 수 있다.
그리고 날리고 싶을때는
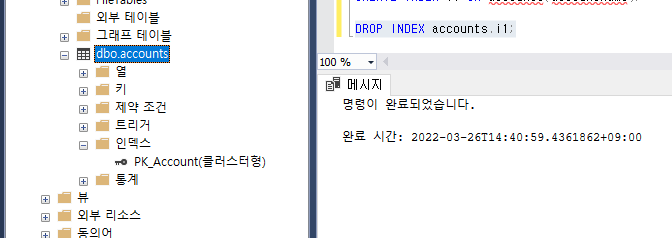
이렇게 날리면됨
그리고 INDEX만들때 UNIQUE를
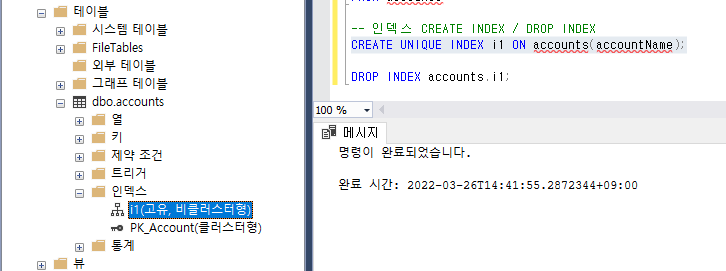
이렇게 붙여주면 고유한 인덱스가 만들어진다. 말그대로 유니크하다
즉, 곂치는 정보가 없다라는 것이다.
그리고
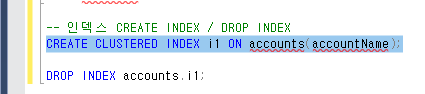
이런식으로도 CLUSTERED를 넣어줄 수 있는데
이렇게하면 "에러"가 뜬다
왜냐하면 애초에 CLUSTERED INDEX는 딱! 하나만 존재 할 수 있다.
그 이유는 물리적으로 데이터가 정렬되는 순서가 CLUSTERED INDEX와 연관성이 있기 때문이다.
두가지 방법으로 정렬한다는 것은 말이 안되니까 CLUSTERED INDEX를 두개를 사용하는 것은 말이 안된다.
