list 1
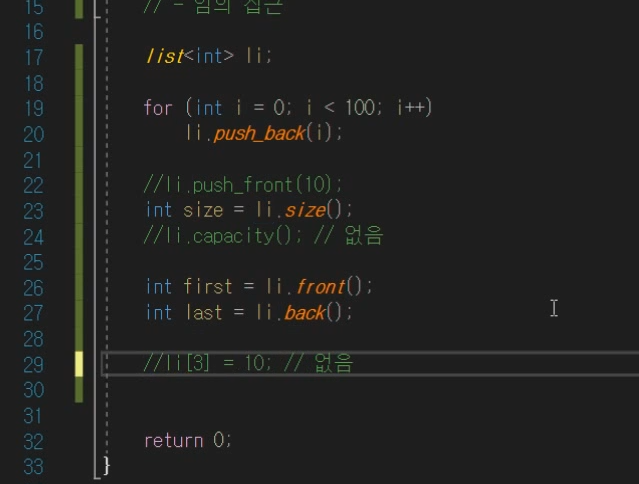
capacity 지원 ㄴ => 당연함. 동적으로 할당하는데 어케 예상?
임의 접근 지원 ㄴ => 당연함.
활용
벡터와 유사하게 동작함.
삽입/삭제
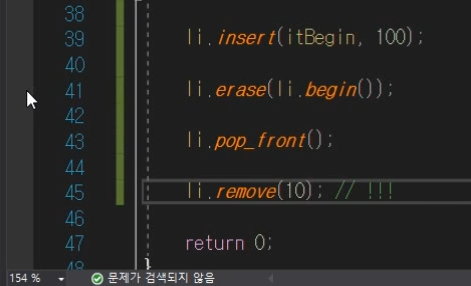
이런 remove와 같은 함수를 지원하는데
왜? 벡터와 다르게 지원을 하냐?
리스트에서는 에초에 이렇게 사용을 할려고 만든 자료구조 이기 때문에 그런 것이다.
이유는 생각해봐라 (동적으로 노드를 추가하니까...)
알아보기
벡터 : 동적 배열
리스트 : 단일 / 이중 / 원형
그중에서도 '단일' 알아볼 것이다.
노드안에 노드 이해?
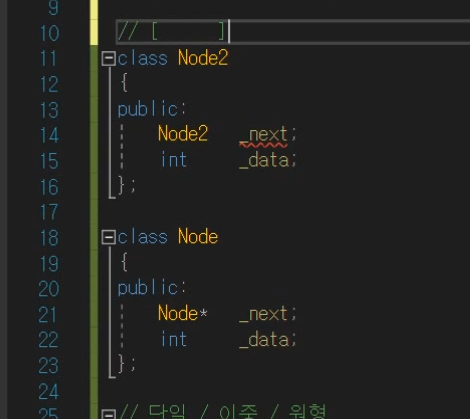
class Node안에 Node*가 들어있는것은 이해가되는데
만약에 class Node안에 Node가 들어가있다?
=> 프로그램 실행해서 Node라는 클래스 크기가 몇인지 올려주어야하는데
크기를 모르는데 어케 올리는데??
이게 무한정 실행이 됨.
Node*의 경우 32/64비트에 따라 4/8바이트로 크기가 메모리에 올라간다.
- 이중
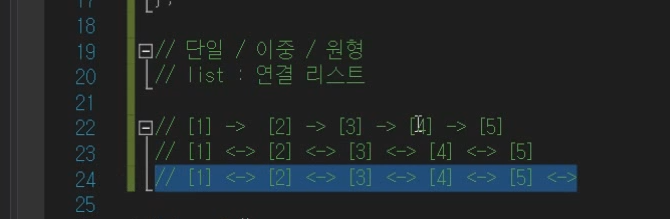
- 원형
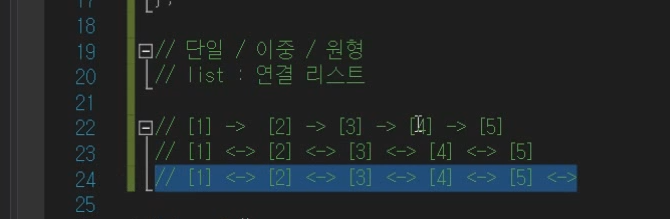
마지막이랑 첫번째 이어줌.
list 2
이런 중간 삽입/삭제에 유용하다.
그런데 이런 '장점'만 있는 것은 아님.
'임의 접근'에 대해 생각해보도록 하자.
operator [ ] 엄청 느리다 => 지원하지 않는다.
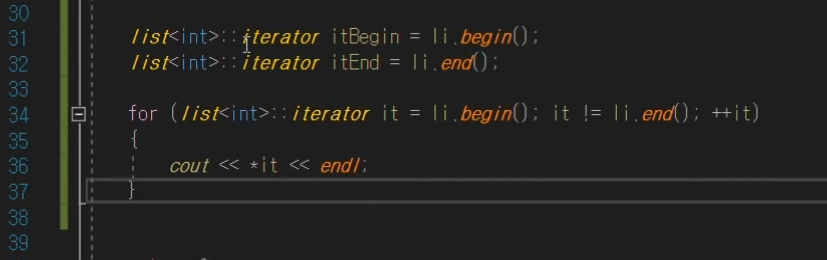
STL 리스트

이렇게 제일 뒤에 end() 지원하는데 더미 노드 하나 낑겨 놓음 이것으로
끝인지 아닌지 구분한다.
이 end()를 기준으로 앞으로가면 1있고 뒤로가면 6이있는 식이다.
근데 iterator를 통해서
첫번째 처럼 접근하면 크래쉬 난다.
막아놓음.
52번째 줄 --End는 가능.++end()도 에러난다.
operator 막아놓음

왜 막아 놓았을까??
벡터와 다르게 한칸이 아닌 여러칸을 움직이는게 빠르게 동작할 리 없다.
그래서 비효율적이라 지원하지 않음.
빠르다? ❗❗❗

임의 접근은 안되는데 중간 삽입/삭제는 왜 빠르나?
iterator가 해당 노드의 주소를 알면 되기 때문에 빠르지 않나?
이거 제대로 이해 해야 대답할 수 있다.
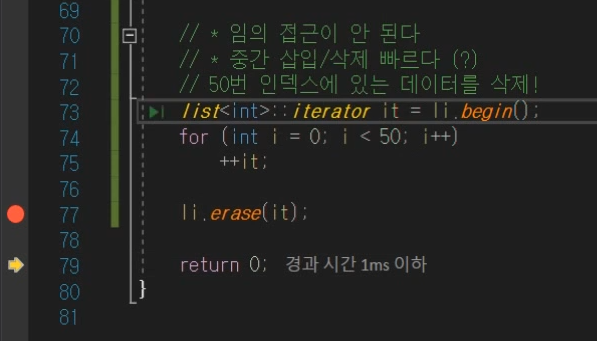
삭제하는 거 자체 erase함수가 빠른 것이지
'임의 접근'(for문으로 접근해서)을 해서 데이터를 찾는 것은 전혀 빠르지 않다.
임의의 숫자를 주고ㅓ 해당 숫자를 찾아서 삭제해라고 하면 전혀 빠르지 않은데
그런데 '삭제할 대상'을 iterator 와 같은 형식으로 들고있는다고 생각을 하면은
굳이 찾지를 않아도 erase자체는 빠르게 동작을 한다는 것이다.
그래서 사진처럼 for문과 erase분리를 해서 생각해야한다.
insert위치 기억 ❗
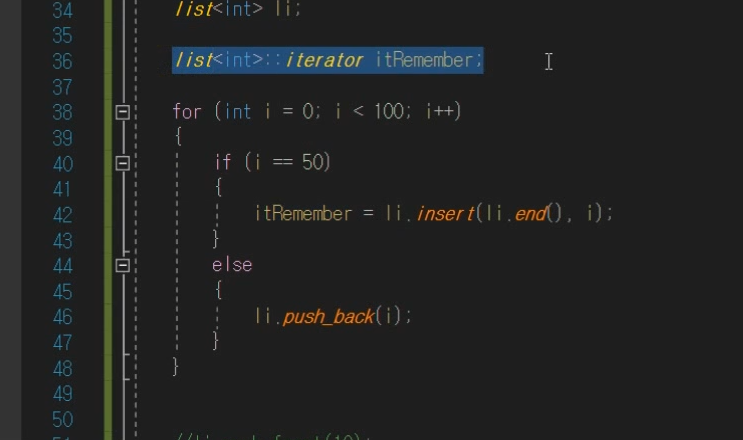
insert하면 해당 iterator를 반환하니까 이런식으로 가능하다.
오 좀 신박? 생각못했던 방법이다.
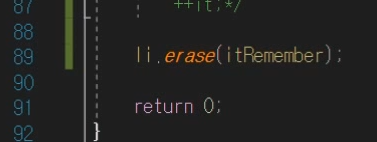
그다음에 이렇게 삭제하면 빠르다.
그런데 '임의의 데이터'를 찾고 '삭제하는 과정' 전체가 빠른 것은 아니다.
잘 구별해야한다 ❗❗❗
찾는 과정과 지우는 과정 다포함.
원리를 이해를 해라.
list 3
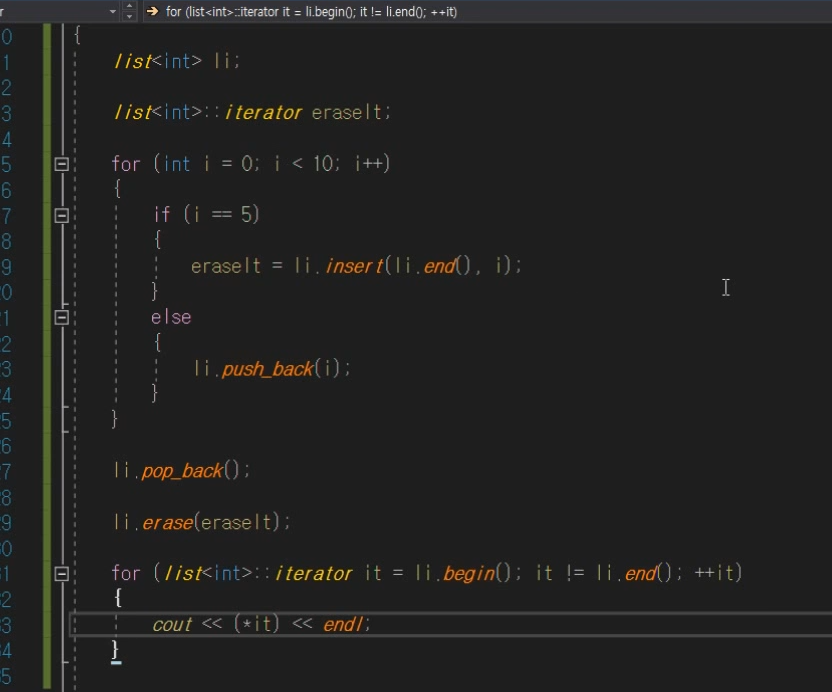
이거 구현해 볼 것이다.
구현
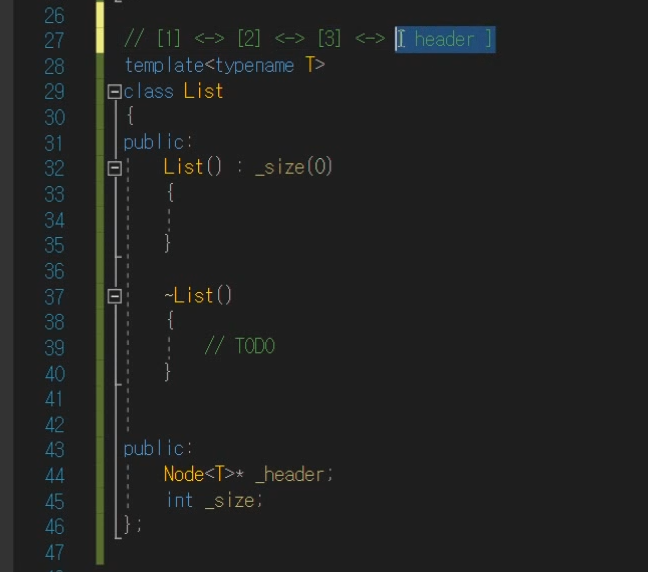
먼저 멤버 변수랑 어쩌구 이렇게 있는 상태이다.
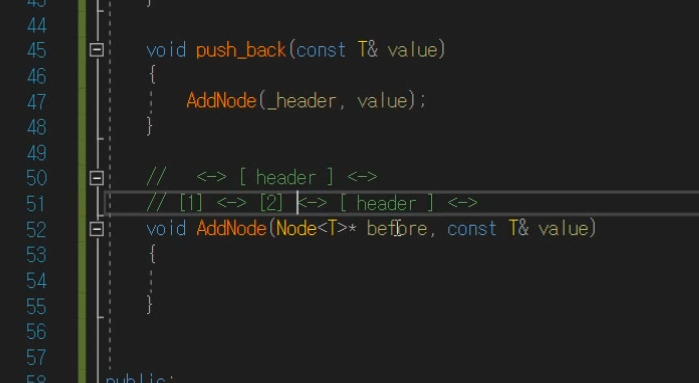
push_back을 할때
AddNode 를 추가를 해줄 것이다.
header만 알면 header바로 전에 데이터 넣어줄 수 있을 것이다.
처음 데이터 넣을 때를 생각
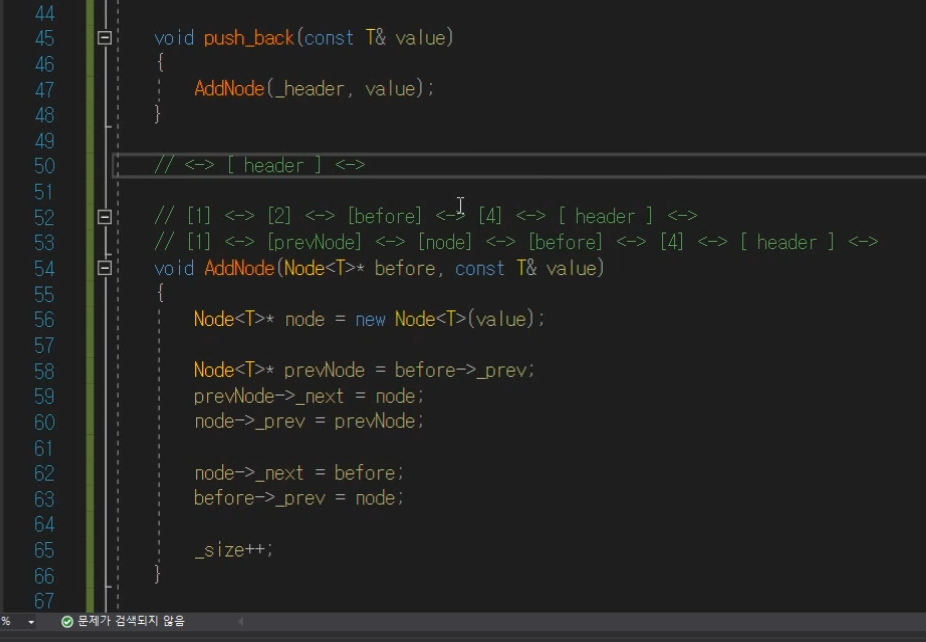
header가 양옆으로 자기 자신 가르키는 중임.
현재 before의 prev도 자기 자신임.
이렇게 됨.
pop_back
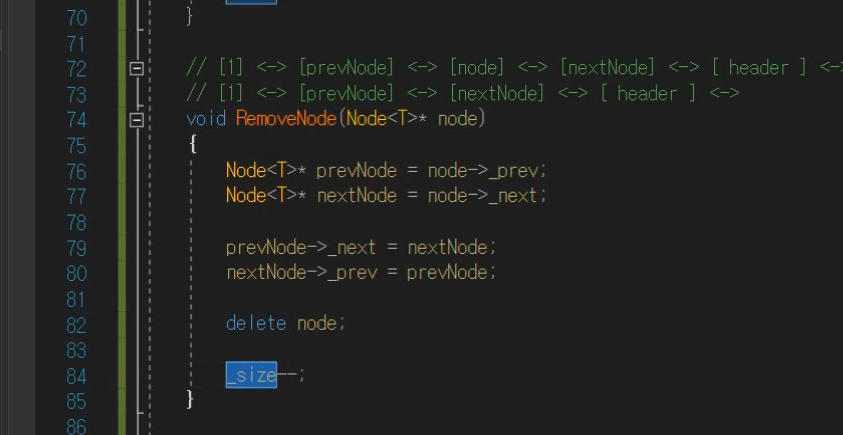
잘~ 생각해봐라
최종
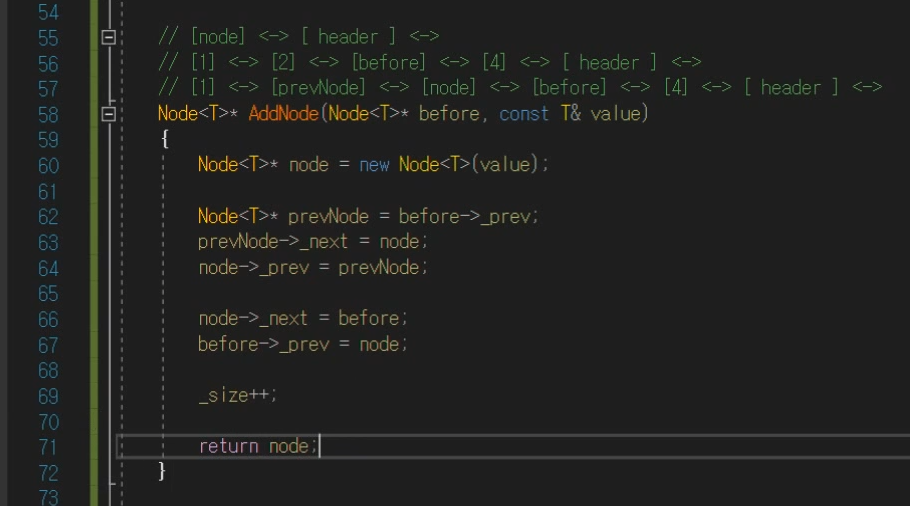
AddNode의 반환 값이 Node< T > 가 되어야함.
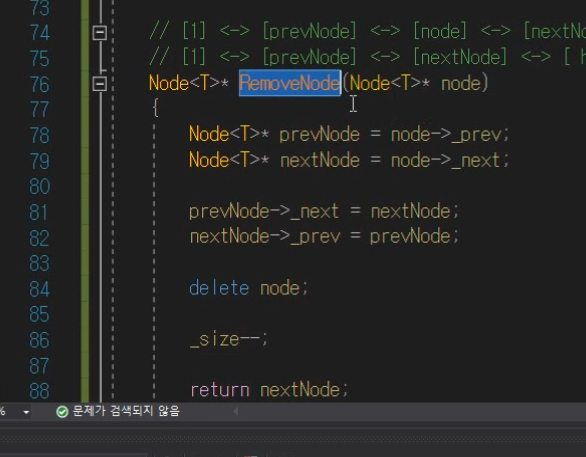
RemoveNode의 경우도 Node * 반환하도록.
~List()
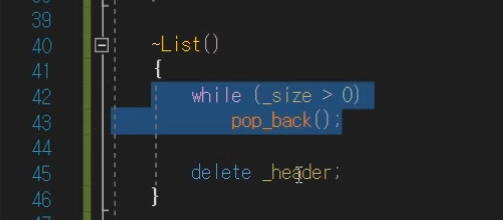
while문을 돌면서 다 delete해주어도 되는데
구현해놓은 기능을 사용하자.
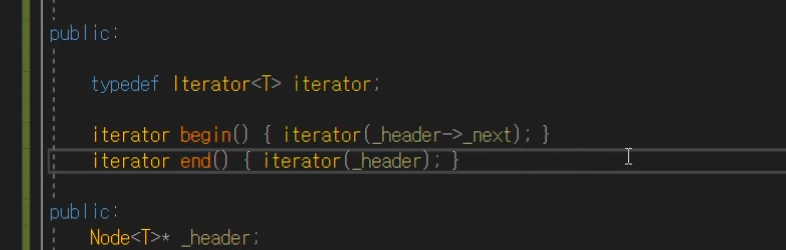
iterator 구현
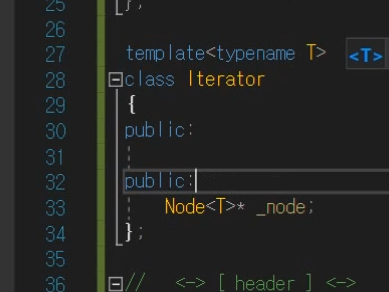
지금 나의 주인님 == List가 누구인지 포인터로 들고있어도 되지만
Release모드로 실행할 경우 내가 어떤 Container에 소속되어 있는지 '생략'이 되어있을 수 있다.
header와 begin