
Standard Template Library
-
STL?
프로그래밍할 때 필요한 자료구조/알고리즘을 템플릿으로 제공하는 라이브러리
-
컨테이너(Container)
데이터를 저장하는 객체 (즉, 자료구조 Data Structure를 의미)
오늘 알아봇 첫번째 '컨테이너'는 'vector'이다.
vector (동적 배열)
1) vector의 동작 원리 (size/capacity)
2) 중간 삽입/삭제
3) 처음/끝 삽입/삭제
4) 임의 접근
(C# 리스트 == 동적배열)
배열

이렇게 사용가능한데
배열의 단점은 배열의 '크기'를 유동적으로 왔다리 갔다리 못함.
동적 배열
어떤 마법으로 -> 배열 유동적?
방법
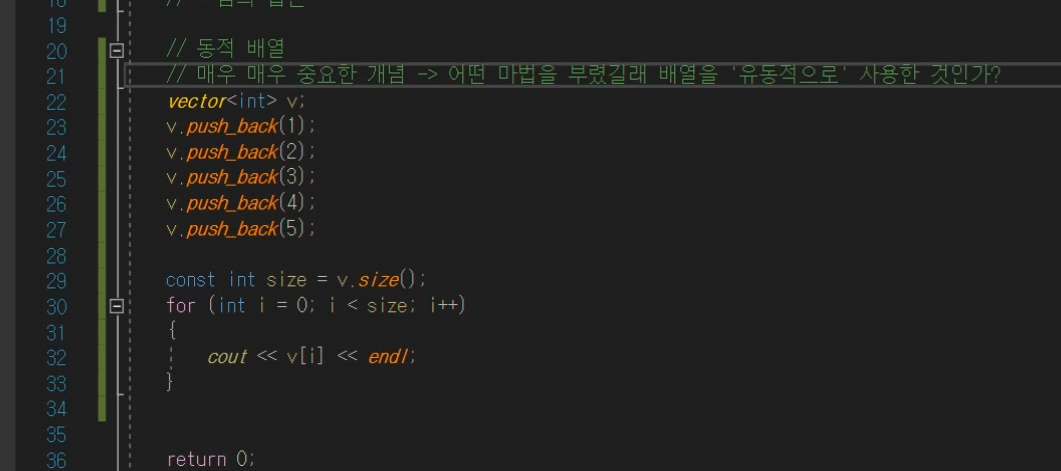
1) (여유분을 두고) 메모리를 할당한다.
-> 기존의 배열과 차이가 뭐임..??
2) 여유분까지 꽉 찼으면 메모리 증설한다.
-> 동적할당을 통해~
문제
1) 여유분이 얼만큼이 적당?
2) 증설을 얼마 만큼?
3) 기존의 데이터를 어떻게 처리?
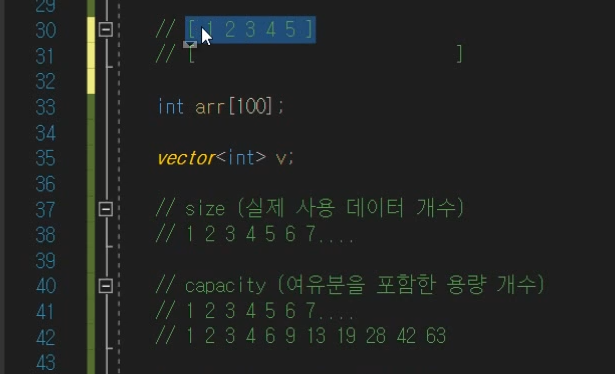
지금 capacity늘어나는 규칙이 1.5배씩 증설함.
이것은 컴파일러마다 다르다. 2배씩 늘리거나 1.5배 씩 늘리거나.
근데 왜 1.5배씩 늘리나?
reserve
벡터의 크기가 예상이 간다면
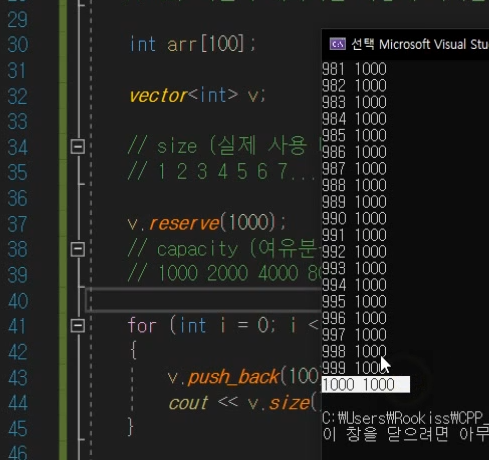
이렇게 미리 1000개짜리로 늘려줄 수 있음.
만약 1001개가 되면은?
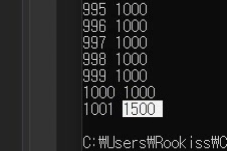
1000 -> 1500 1.5배 증가함.
resize
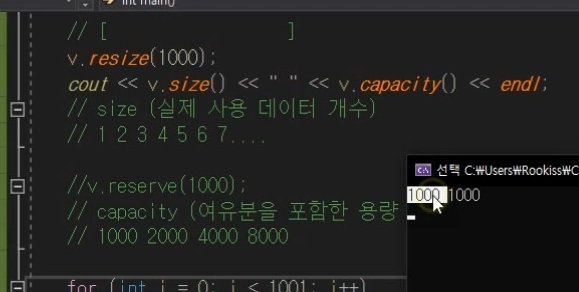
강제로 size1000개로 늘림.
여기서 push_back면 데이터 1000개쌓은 상태에서 더 넣음.
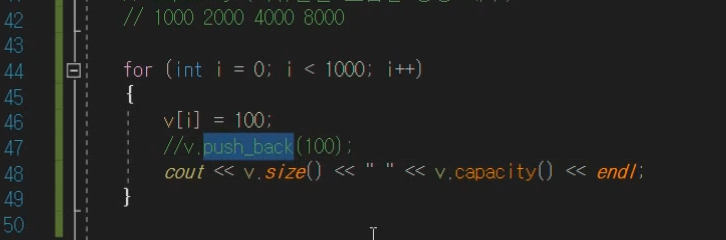
그래서 이렇게 사용하면됨.
왜 reserve를 사용하냐? ❗❗❗
reserve를 사용하지 않고 그대로 놔두면 capacity가 적은 상태로 데이터를 넣기 시작해서
capacity가 변화할 때마다 delete하고 복사하는 비용이 들어가서
처음부터 복사비용이 발생안하도록 capacity를 크게 잡는다.
'복사비용'이 많이 발생할 수 있기 때문에.
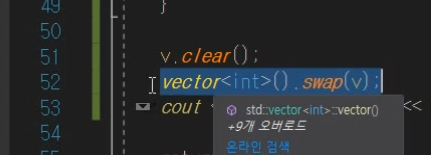
clear
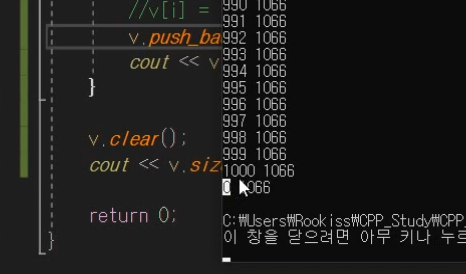
데이터 넣고 clear하면 size는 0되고
capacity는 그대로 이다.
그런데
"아 나는 capacity도 0으로 만들래!" 이런경우는
꼼수이기는한데
swap함수를 통해서 할 수 있다.
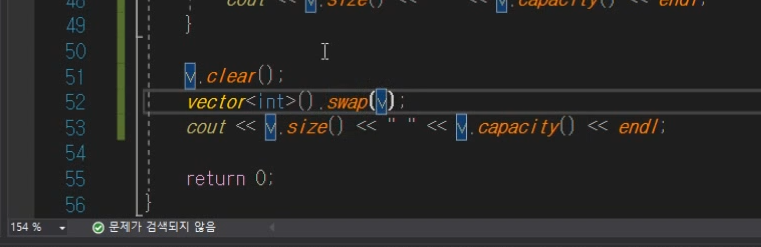
기존에 v가 가지고있던 데이터를 vewctor< int >가 가지고있는 것이고
vector < int > 가 가지고있는 것을 v가 가지고 있게됨.
그리고
이 벡터가 임시 벡터이다 보니까 이 줄이 실행되자마자 소멸됨.
임시 벡터??
여러가지 기능

맨처음 데이터
맨 마지막 데이터
마지막 데이터 pop하기
생성자
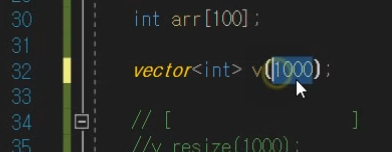
만들자마자 크기를 이렇게 정해줄 수 있고,
그 크기에 들어갈 데이터들의 데이터를
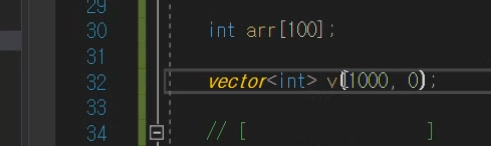
특정 초기값을 이렇게 넣어 줄 수 있다.
또한 '복사대입 연산자'로 싹다 복사가능
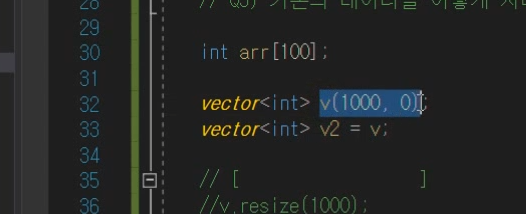
이렇게.
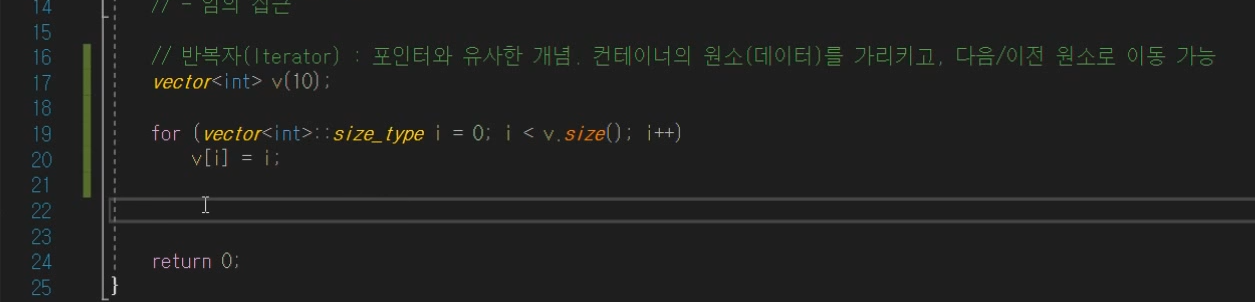
iterator
포인터와 유사한 개념
컨테이너의 원소(데이터)를 가르키고, 다음/이전 원서로 이동 가능.
vector < int > size_type 하면은 알아서 알맞는 타입을 정해준다.
(지금은 unsigned int)
연산자
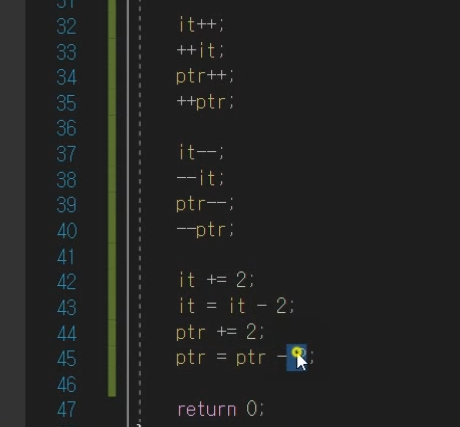
이런식으로도 활용할 수 있다.
begin() end()
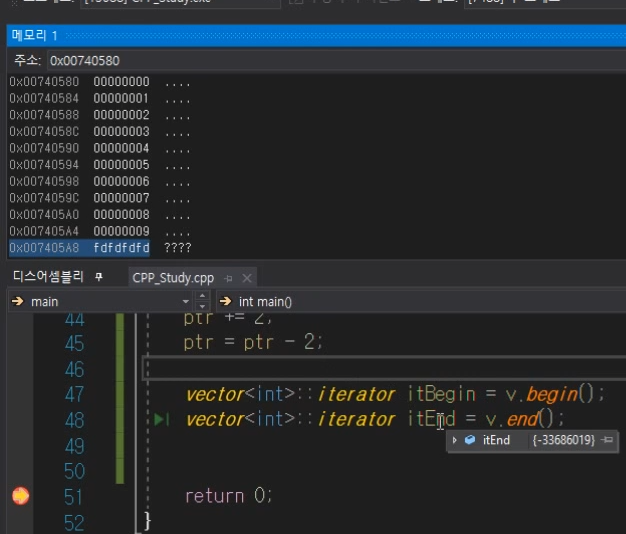
end()의 경우 마지막 데이터 다음의 쓰레기값이 들어있는 주소를 가르키고있는 상태이다.
end() == 끝을 판별할 때
데이터 확인
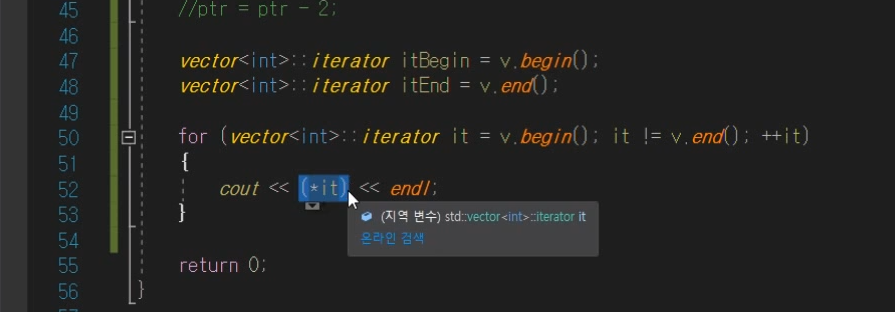
이렇게 사용가능.
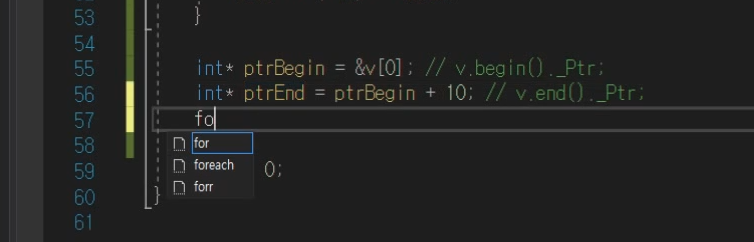
시작과 끝.

위와 아래가 완전히 똑같다.
근데 조금 복잡해 보인다. 왜 쓰나??
=> iterator는 vector뿐 아니라 다른 컨테이너에도 공통적으로 있는 개념이다.
const_iterator
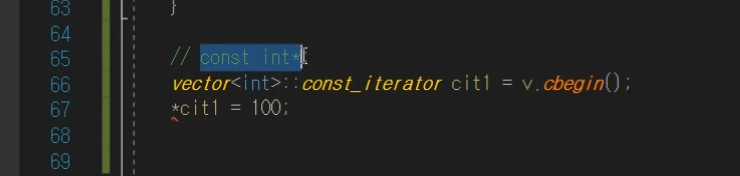
데이터를 수정하지 않을 것이고 읽기만 할려고 할 때 사용하는
iterator이다. (값 수정 불가능)
reverse_iterator
역방향으로 이동하는 iterator이다.
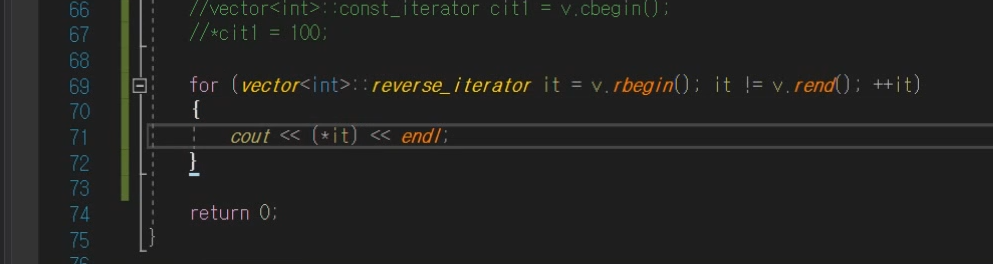
맨마지막 값부터 거꾸로 나온다.
이거 사용을 거의 하지 않는다.
중간 삽입/삭제, 처음/끝 삽입삭제, 임의 접근
중간 삽입/삭제
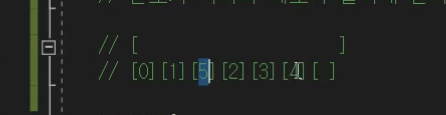
고정된 크기 안에서 iterator가 가르키는 곳을 기준으로 오른쪽으로 싹다 한칸씩 다 옮긴다음에
데이터를 넣어주어야한다.
=> 너무 비효율적이다. 이럴꺼면 벡터가 아니라 리스트 써야함.
삭제도 마찬가지.
즉, 중간 삽입/삭제 가 비효율 적이다.
처음/끝 삽입/삭제
이거도 중간 삽입/삭제랑 똑같이 존나 비효율적이다.
상식적으로...
끝에는 별 상관없음. 삽입하든 삭제하든.
임의 접근
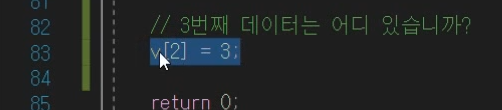
뭐 별거는 아니고 [ ] 연산자 사용하는 것을 말한다.
데이터가 메모리가 연속적이라 가능 한 것이다.
다른 컨테이너들은 '임의 접근'이 안됨. (리스트 같은거)
insert()
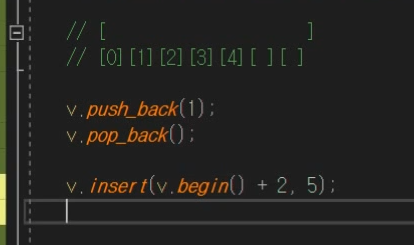
애는 사용하는거도 좀 귀찮은데
비효율적이니까 인지를 하고 사용해라! 라는 말이다.
erase()
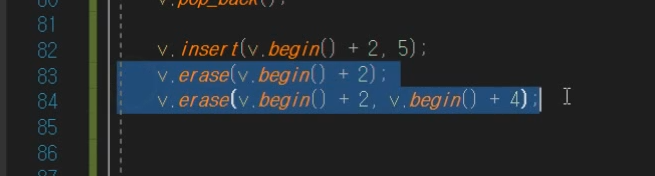
첫번째는 딱하나만 삭제를 하는 것이고
범위를 지정해서도 삭제가 가능함.
insert, erase 반환 값

insert의 경우
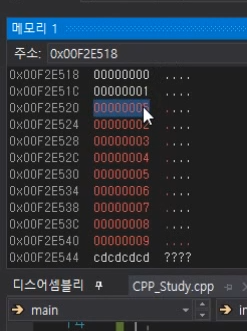
딱 5를 넣었을 때 그 주소를 반환한다.
(나머지 한칸씩 싹다 밀리고)
erase한 경우

이렇게하면\
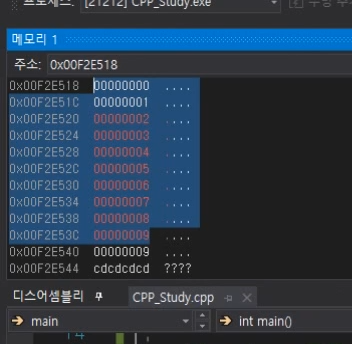
아까 넣었던 데이터 싹다 없어지고 다시 한칸씩 앞으로.
삭제했던 그 자리(주소)를 반환한다.
그런데 end()자리에 9가 들어가 있는데
이것은 유효범위는 드래그 한 부분이라고 알려주기만하면 된다.
굳이 데이터를 밀어줄 필요는 없다.
범위를 지정해준 경우
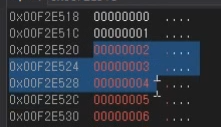
드래그 한부분을 없애기로 한 것이다.
그런데 4가 들어있는 애는 포함이 되지 않고
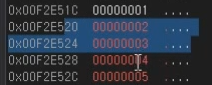
딱 이부분까지만 삭제를 해준다.
에러? 예시 ❗❗❗
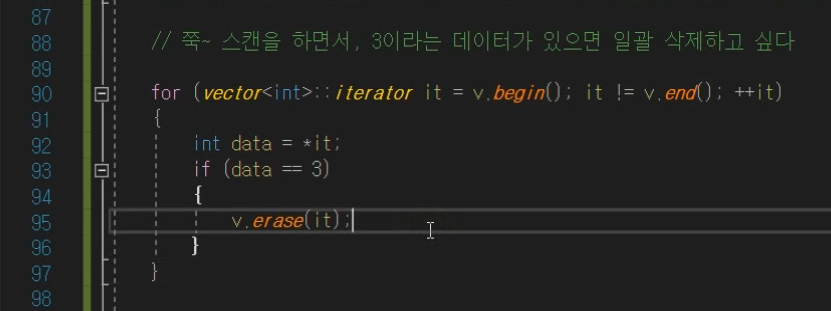
이렇게 할 경우 '문제'가 있다.
크래쉬 나는데
일반적인 포인터와 iterator가 비슷하게 동작은 하지만
iterator는 포인터만 쌩으로 들고있는게 아니라 추가적인 정보를 가지고있다.
iterator에 대한 이해 ❗
강의에서도 똑같은 말한다.
현재 *it은 iterator의 주수를 말하는거 맞다.
iterator가 뭐냐? => 벡터의 원소(데이터)를 가르키는 역할을 한다.
이녀석은 추가적으로 벡터의 주소도 가지고있다.
그런데 erase동작방식은 인자로 넘겨준 iterator도 삭제하고 iterator가 가르키던 곳의 '데이터도' 삭제를 한다.
iterator를 삭제하고 나니까 당연히 사용못하는 iterator가 되어
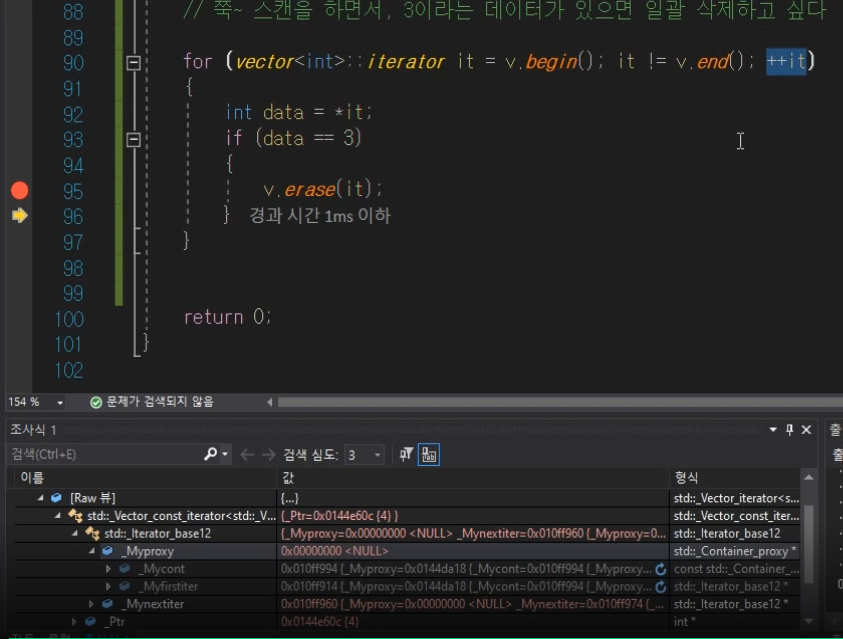
iterator가 가르키던 벡터주소가 nullptr로 밀림.
(벡터의 주소값이 nullptr로 밀린게 아니라)
ㅇㅋㅇㅋ.
그런데 for문에서 연산자로 오버로딩 한거 operator ++계속해서 접근 할라니까 크래쉬가 난다.
또한 이렇게 for문이 있다면 4를 넘기는 문제가 발생함.
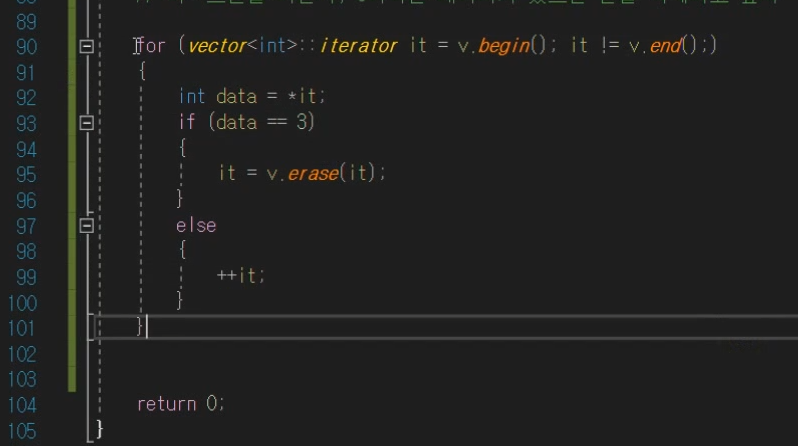
그래서 이렇게 해주어야함.
vector구현
이런 기능들을 만들어 볼 것이다.
전위 / 후위 연산자
전위의 경우 참조값을 뱉어주어서
++(++a) 이런거 가능한데
후위의 경우
(a++)++; 복사값을 내뱉어 주기 때문에 이거 안됨.
clear의 경우
메모리를 어떻게 하는게 아니라 _size만 0으로 바꿔치기 해주도록 하자.
