
1. 그래프 기초
정점과 간선으로도
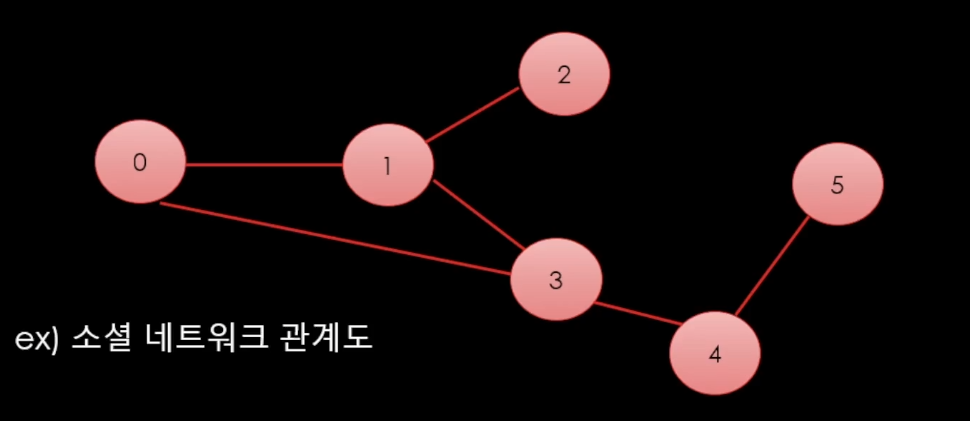
이렇게 만들 수 있고 이것 외에도ㅓ

"가중치"를 주어서 가중치 그래프 만들 수 있음
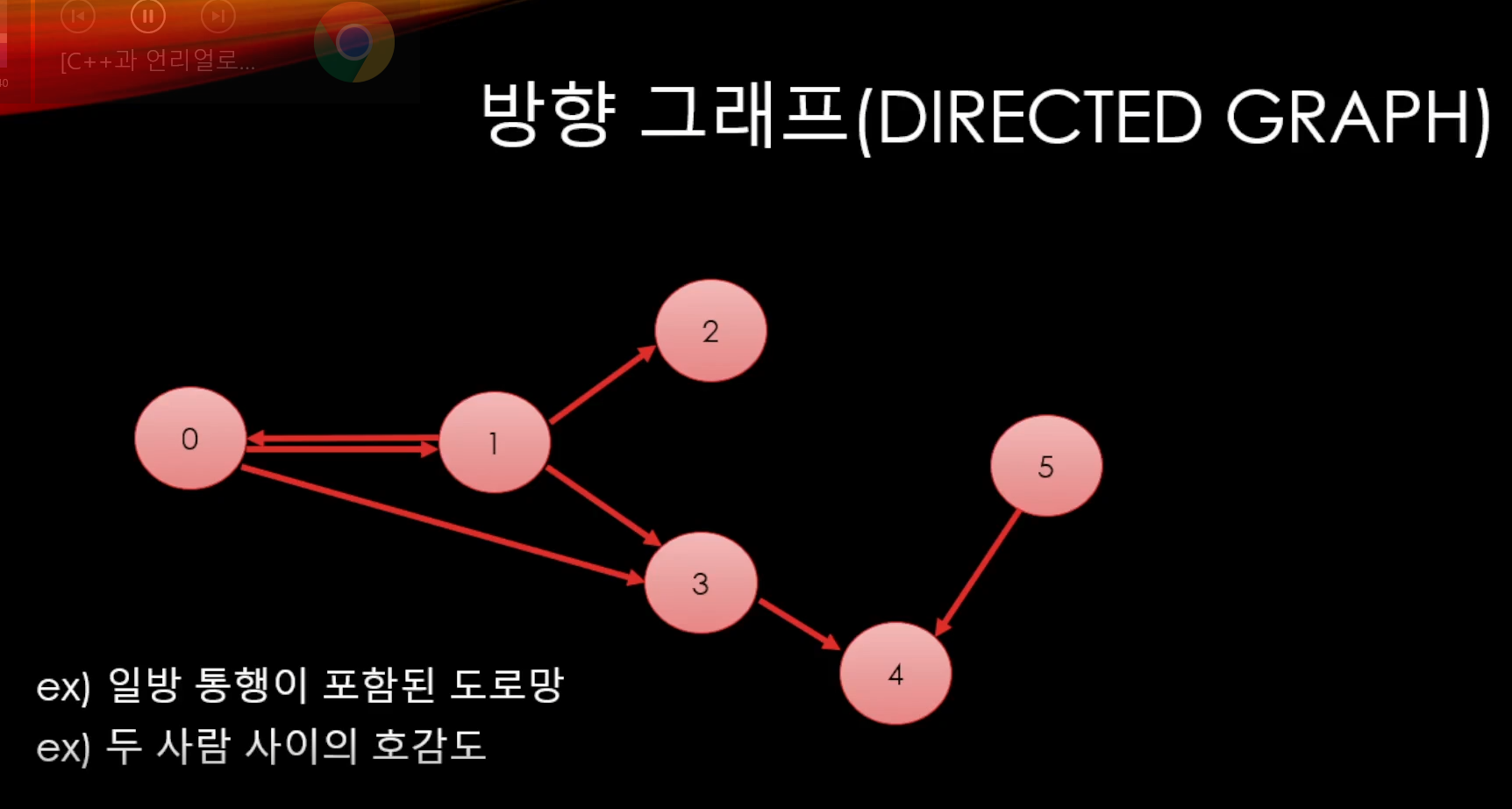
방향그래프도 있다.
구현
이거 C++로 구현을 하자면은
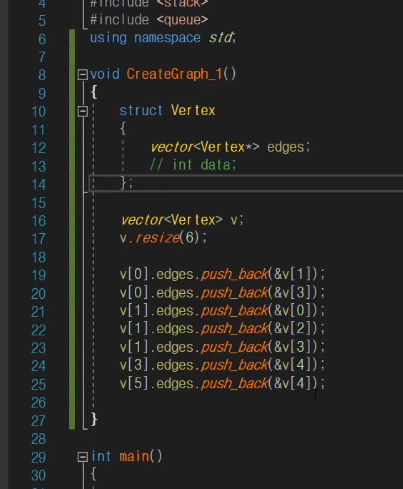
대충 이런식으로 된다.
for문 순회 ❗
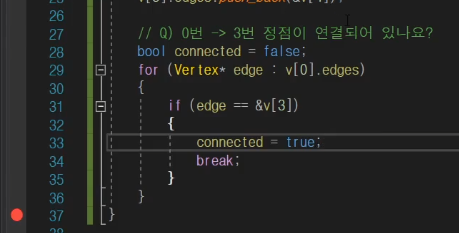
연결관리 하는 방법
3번확인
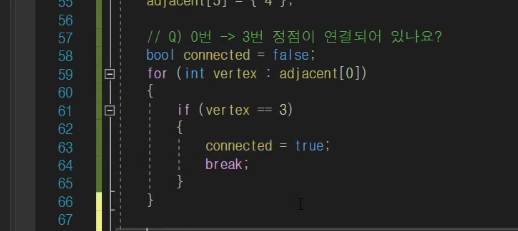
이렇게 loop를 돌아서 확인하는 방법도 있다.
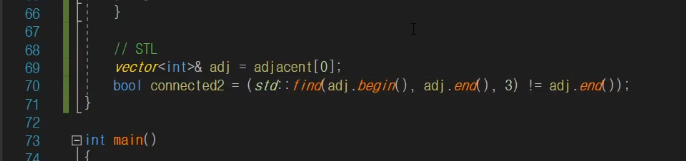
STL이용방법
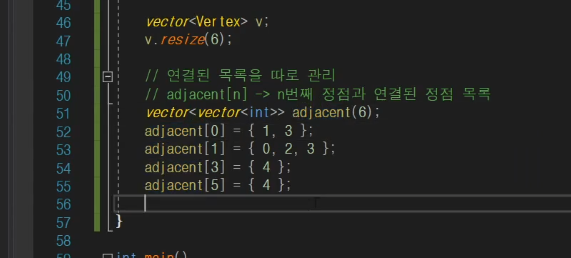
정점이 많을 경우?

페북 친추 같은 경우 100명이 99번씩 다 연결을 하면은 이것을 어떻게 관리를 할까?
즉, 빽빽하게 연결되어 있을 경우 행렬을 사용하는게 조금더 낫다.
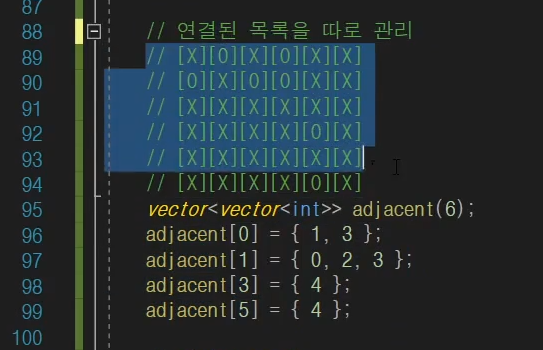
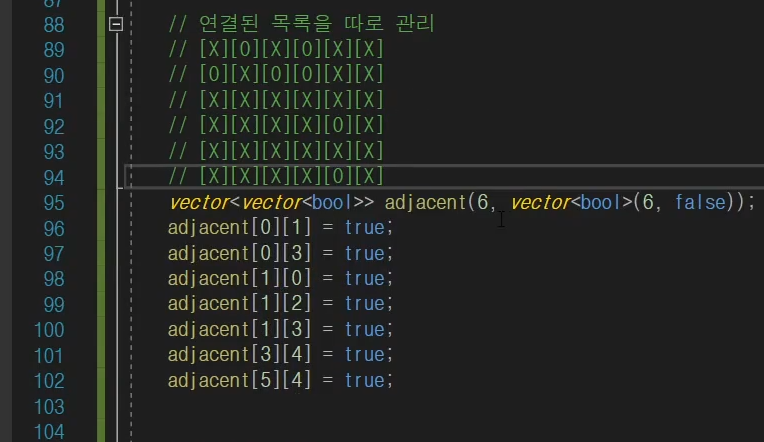
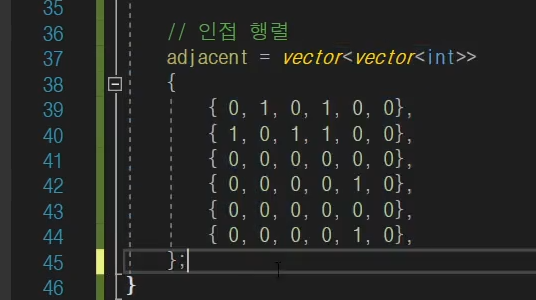
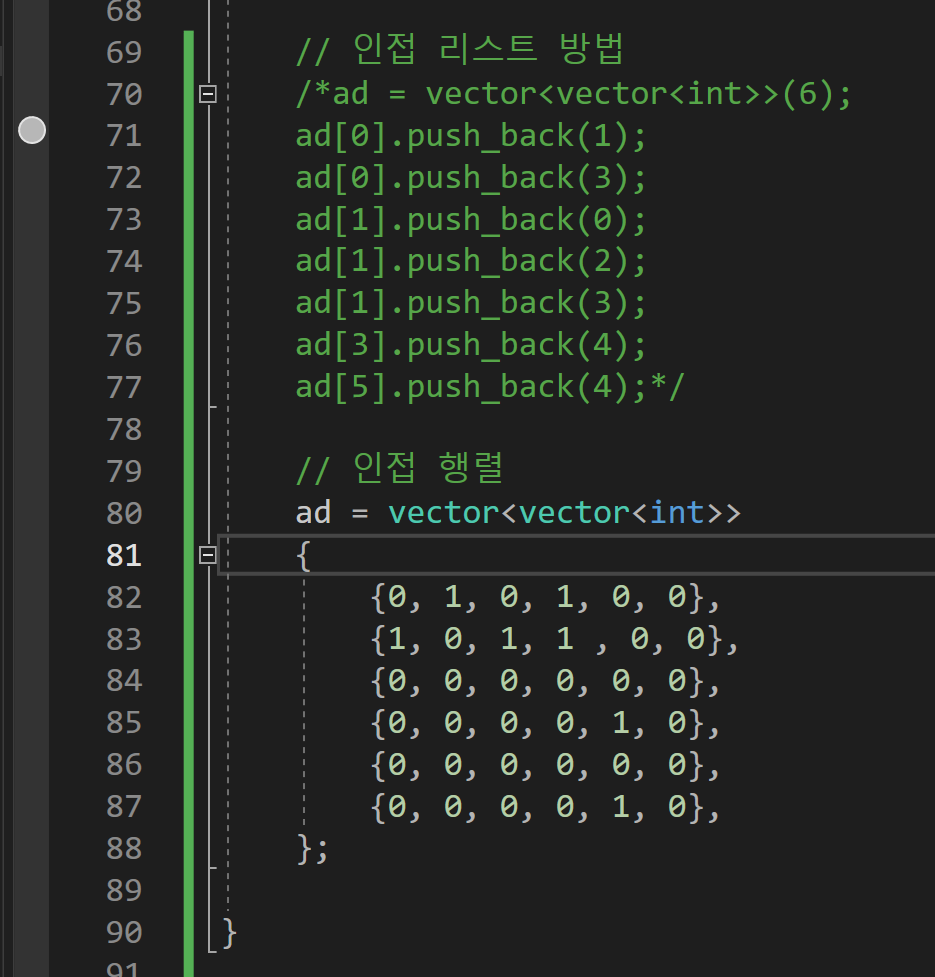
이렇게 2차 행렬로 표현을 하면은 vector<vector< int >> 이거랑 같은 표현이다.
초기화
확인 하는 방법
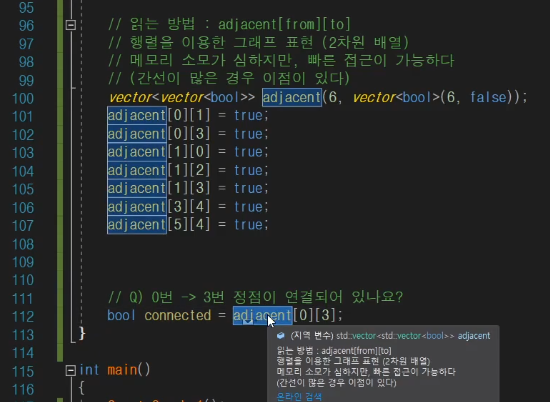
이렇게 바로 확인이 가능하다. 메모리는 조금 낭비를 하지만 성능을 챙기는 방법
가중치 넣기 ❗
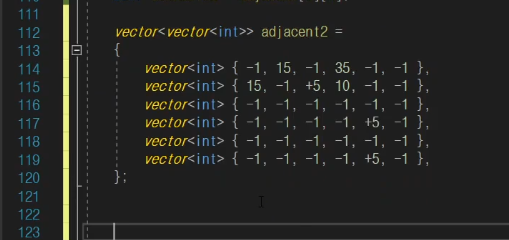
연결여부 판단
-1인지 아닌지를 보고 판단이 가능하다.
2. DFS
깊이 우선 탐색
그래프 탐색을 하는 방법이 크게 두가지가 있음
DFS, BFS
DFS는 끝이 날 때까지 계속 파고 들어가는 거임.
BFS는
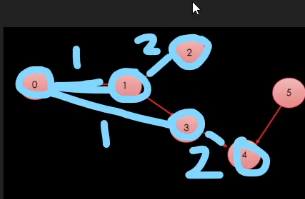
길이 있으면 그냥 막 들어감.
DFS는 재귀햠수로 많이 구현을 한다.
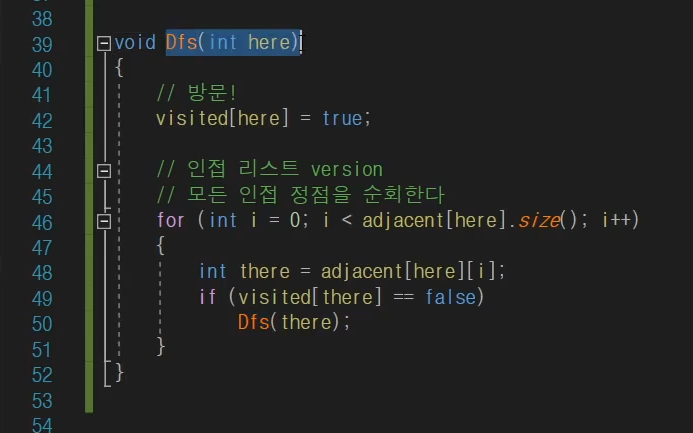
코드는 이런데
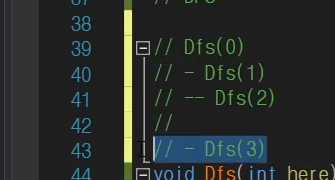
현재 DFS에 0을 넣은 부분부터 호출을 한다.
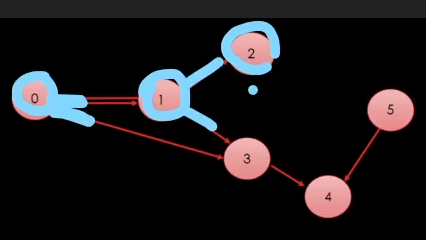
그리고 1을 넣은 부분 호출을 하고 2를 넣은 부분 true로 만들고
원래는 0번에서 호출한 Dfs(3)이 true로 만드는데
이런식으로 왔다고 확인을 해준다.
인접 행렬 버젼

DFS함수는 이렇게 수정이 된다.
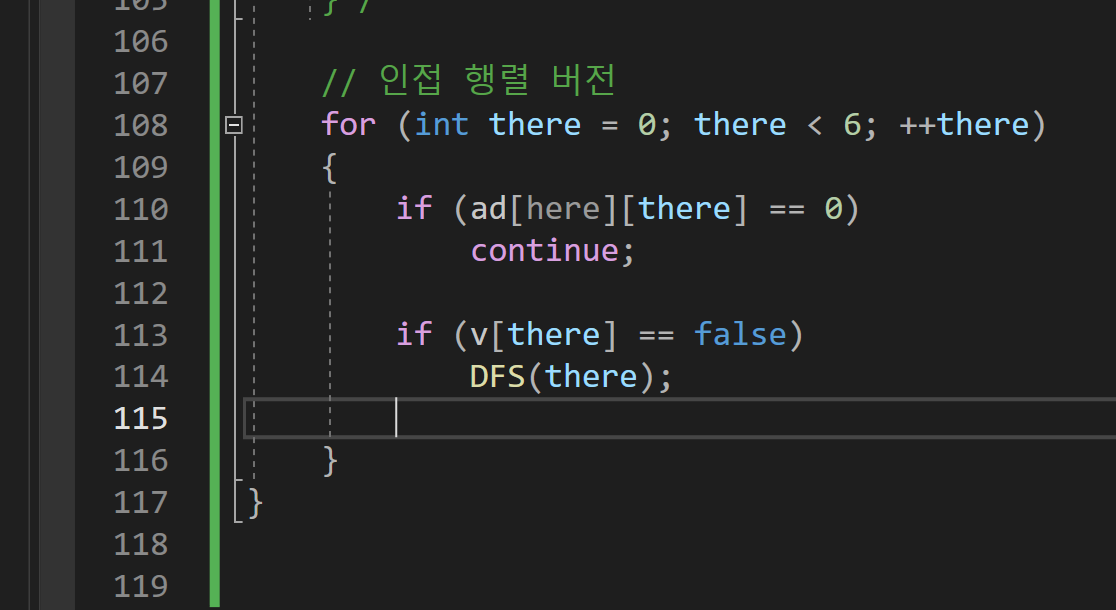
이렇게.
3. BFS
너비 우선 탐색
사용범위가 좀 제한 적임.
사용할 수 있는 범위는 보통 길찾기 정도.
가까운애들 부터 들어갈려는 특성이 있다.
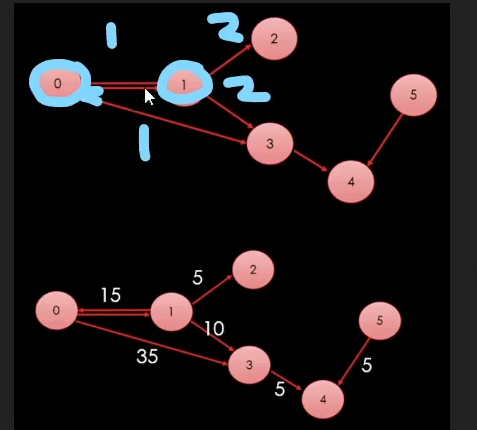
DFS라면은 0에서 출발을 해서 1로 갔다가 2로 갔다가 3으로 갈테지만
BFS의 경우에는 "진입점"을 기준으로 항상 가장 가까운 곳부터 가기 때문에
0 -> 1 갔다가 0 -> 3으로 간다.
입구를 기준으로 가장 가까운 곳부터 간다.
DFS의 경우 재귀함수를 사용하지 않았다면은 조금 힘들었을 텐데
마찬가지로 BFS도 Queue를 사용을 해서 예약시스템을 사용하면 좀더 편하다.
코드
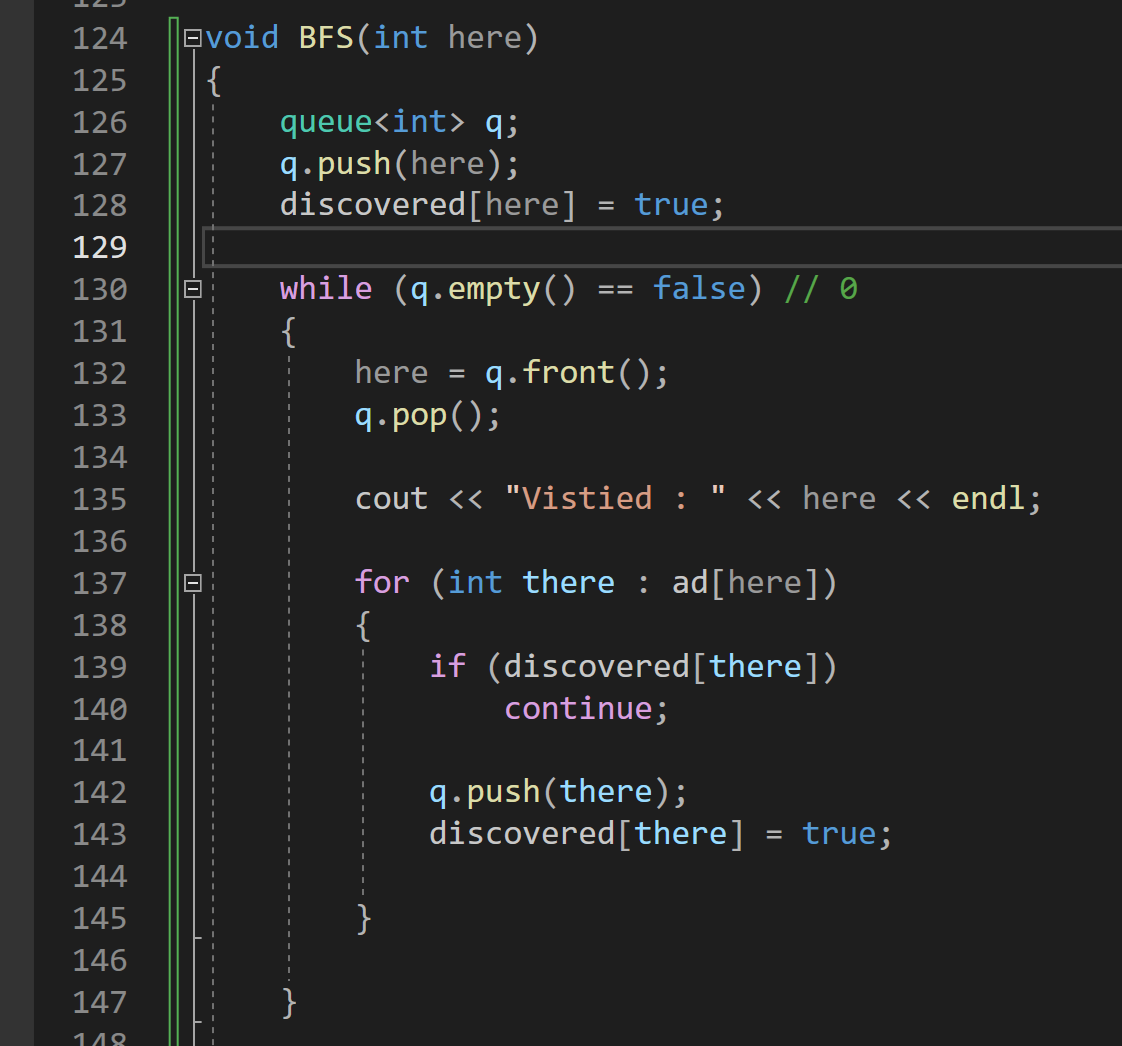
이게 다라고 보면은 된다.
BFS는 두가지 정보 추적가능
누구에 의해 발견 되었는지?
시작점에서 부터 얼만큼 떨어져있는지?
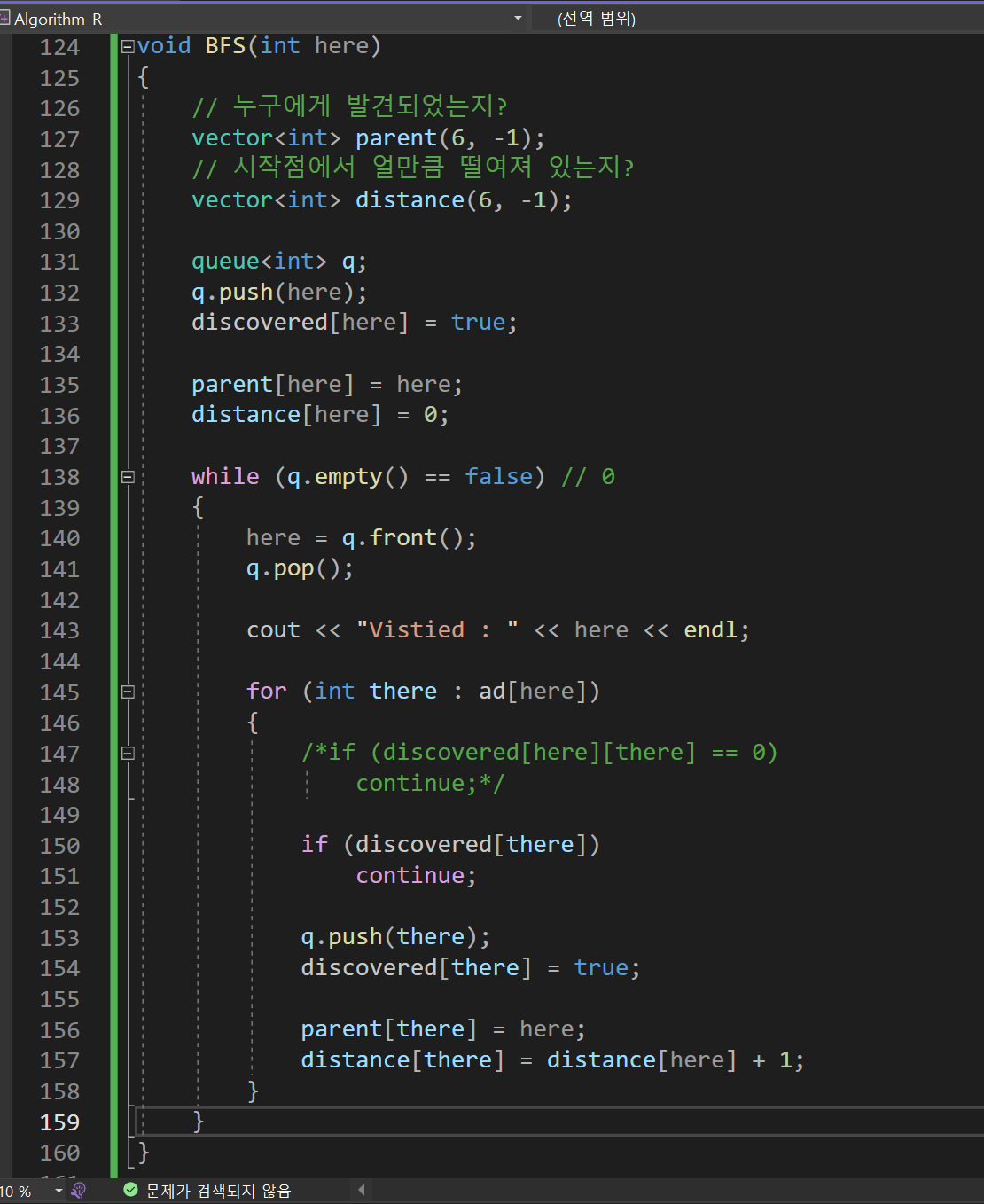
정리
큐로 먼저 방문했다고 해주고 난다음
큐에있는 front부터 인접한 녀석들을 중에 방문한게 있는지 없는지 확인을 한다음에
큐에다가 다시 넣어준다.
그리고 다시 while문을 돌리는 식이다.
DFS든 BFS든 혼자 구현할줄 알아야함.
BFS를 이용한 길찾기 구현
이중 vector초기화 ❗
이거는 이해가 감.

이녀석은 초기화를 해주면서 vector를 만들것인데
크기가 size이고 초기화 되는 값이 vector< bool > (size, false) 라는 것이다.
구현
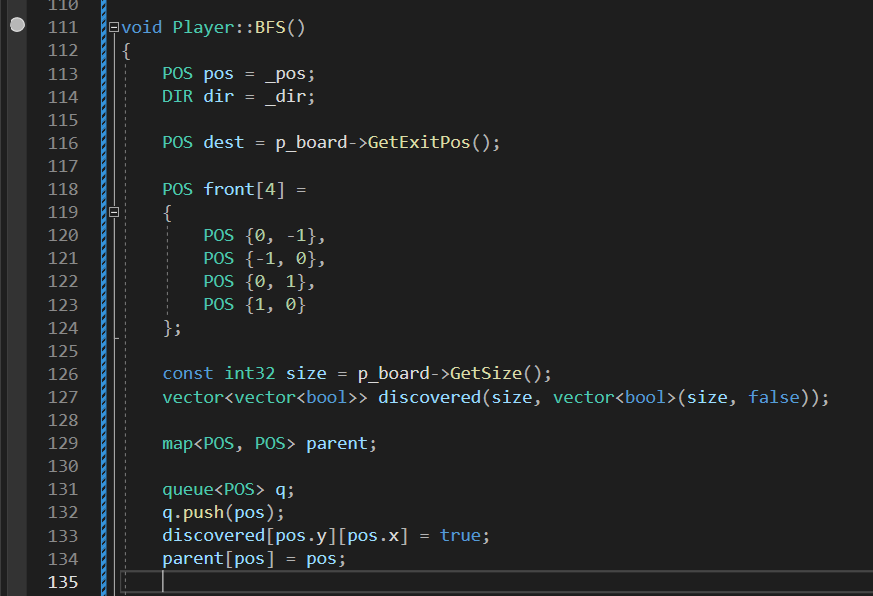
이까지는 잘 이해도 되고 DFS랑 다른게 거의 없다.
이전에 했던 BFS랑 똑같은 형태임.
queue를 만들어주고 현재 pos를 push해주고난뒤 discovered안에 넣고 parent설정까지
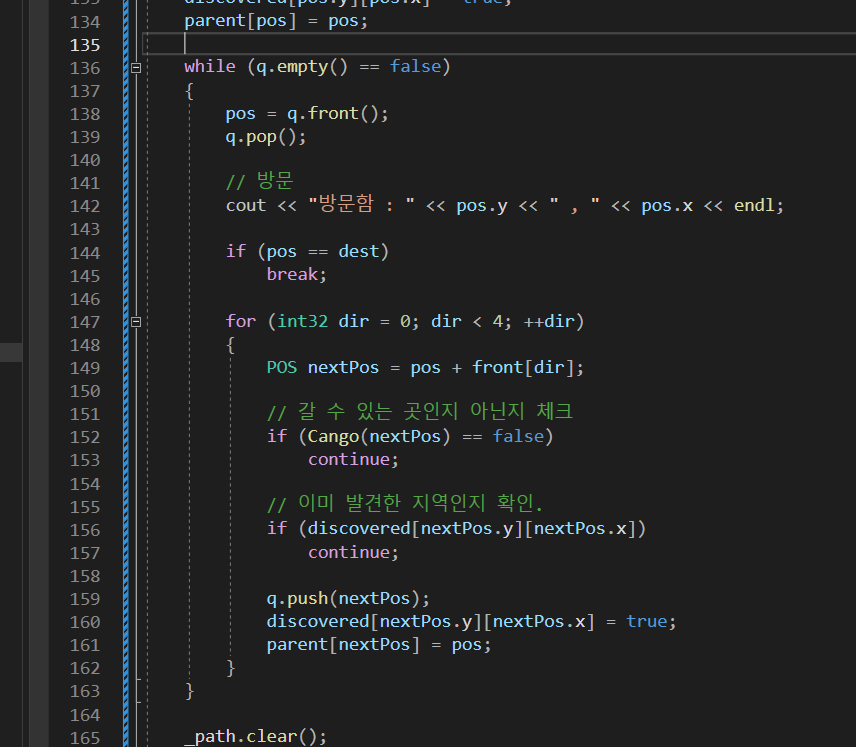
이후 while문 안이 이해가 잘 가지 않는데,
현제 출발점으로 부터 가장 가까운 곳부터 방문하는게 BFS의 핵심이다.
그러니까

맵이 이렇게 있으면 지금 우리는 목적지를 찾은 부모의 부모를 거슬러 올라간 것을 거꾸로 해서 보고있기 때문에 최단 거리로 움직이고 있지만
사실 BFS는
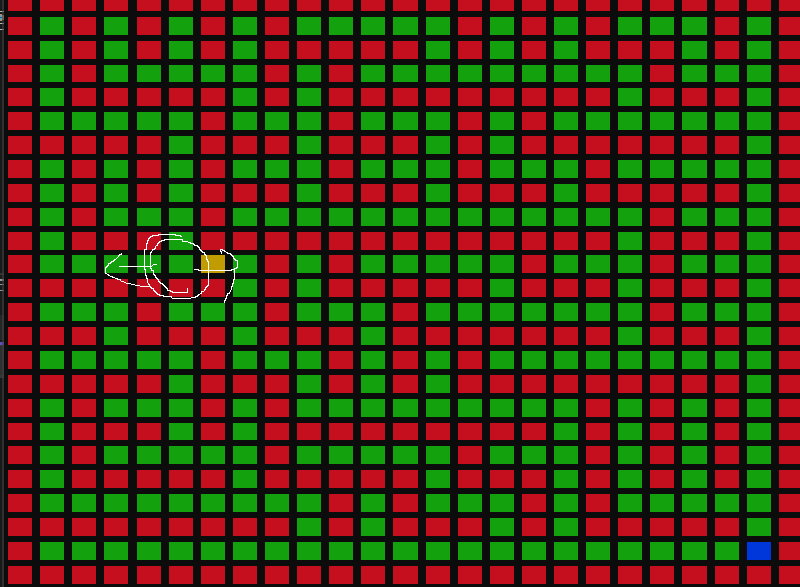
이런 갈림길에 왔을 때 왼쪽, 오른쪽 둘다 다 들려보는 것이다.
목적지라는 게 없고 BFS로 탐색을 하다보니까 23, 23이 나와서 끝난거임.
4. Dijkstra
BFS의 한계
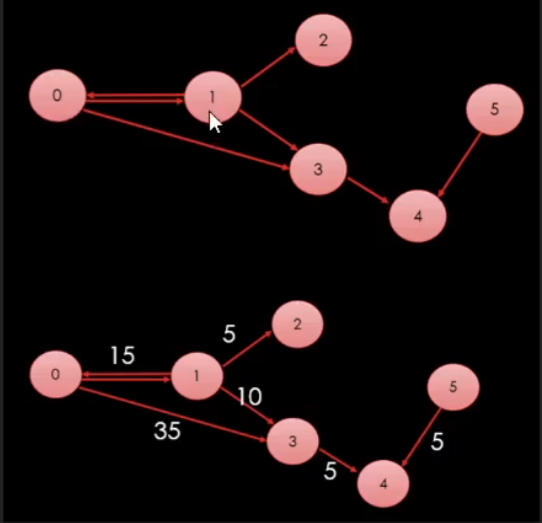
가중치가 있을 경우 구현할 수 없다.
뒤는게 더 효율적인 경로를 찾을 경우 해당 경로로 수정을 하는게 BFS와 다른점이다.
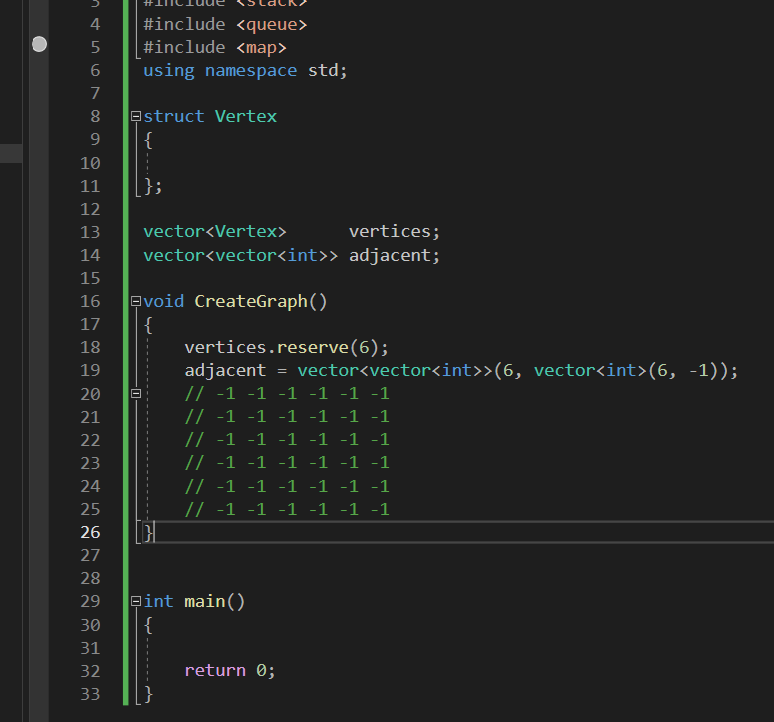
일단 이까지 만들어주도록 하자.
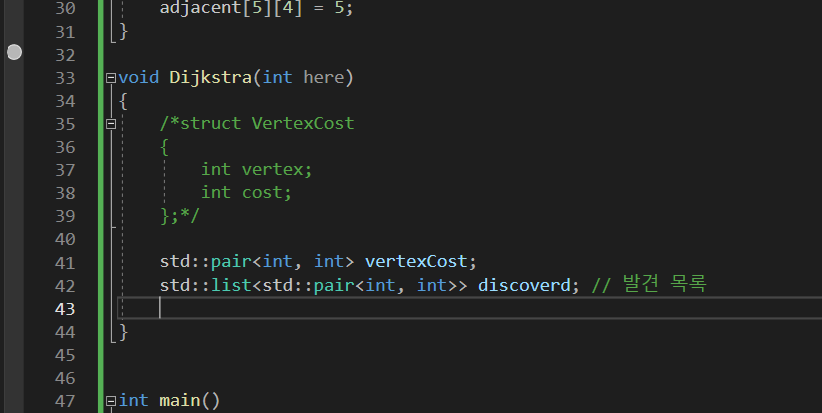
이전에는 std::quque로 발견한 녀석부터 찾는 것이였는데 이제는 비용을 계산해야하기 때문에 다른 자료구로를 사용할 것이다.
make_pair
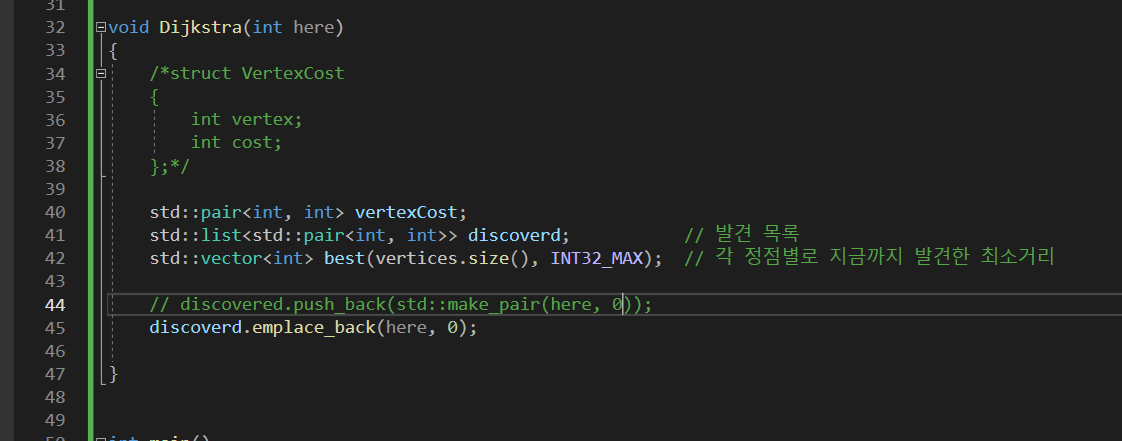
push_back에서 바로 객체를 만들어서 전달해줌. 이거
resize VS reserve

resize(10000)하면 싹다 0으로 초기화 하는 것이고
reserve는 할당만 해놓고 아무것도 안채운 상태임.
그래서
여기서 reserve를 해주게되면은 size는 0이 나오게되어서

이부분 에러남. 즉, resize로 변경해야한다.
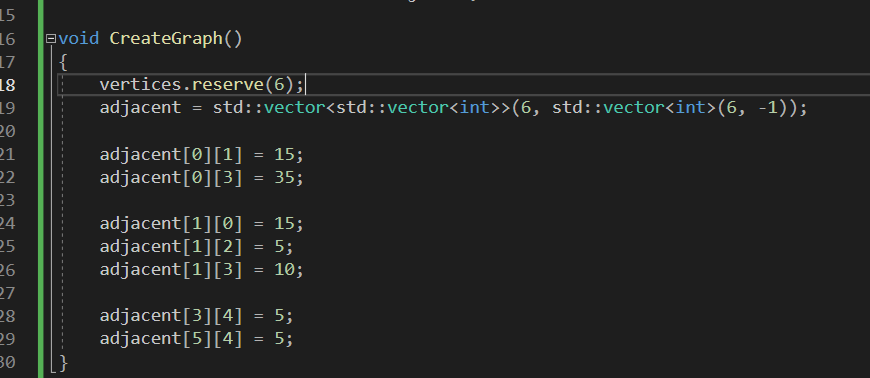
코드 정리
void Dijkstra(int here)
{
std::pair<int, int> vertexCost;
std::list<std::pair<int, int>> discovered; // 발견 목록
std::vector<int> best(vertices.size(), INT32_MAX); // 각 정점별로 지금까지 발견한 최소거리
std::vector<int> parent(6, -1);
// discovered.push_back(std::make_pair(here, 0));
discovered.emplace_back(here, 0);
best[here] = 0;
parent[here] = here;
while (discovered.empty() == false)
{
// 제일 좋은 후보를 찾는다.
std::list<std::pair<int, int>>::iterator bestIter;
int bestCost = INT32_MAX;
for (auto iter = discovered.begin(); iter != discovered.end(); ++iter)
{
const int vertex = iter->first;
const int cost = iter->second;
if (cost < bestCost)
{
bestCost = cost;
bestIter = iter;
}
}
int cost = bestIter->second; // 0
here = bestIter->first; // 0
discovered.erase(bestIter);
// 방문? 더 짧은 경로를 뒤늦게 찾았다면 스킵.
if (best[here] < cost)
continue;
// 방문! (인접한 애들 다 등록을 해주어여한다)
for (int there = 0; there < 6; ++there)
{
// 연결되지 않았다면 스킵
if (adjacent[here][there] == -1)
continue;
// 더 좋은 경로를 과거에 찾았다면 스킵.
int nextCost = best[here] + adjacent[here][there];
if (nextCost >= best[there])
continue;
best[there] = nextCost;
parent[there] = here;
discovered.emplace_back(there, nextCost);
}
}
}best에는 가장 cost가 적게 들어가고 parent도 보면은 부모가 다 들어가있게된다.
목적지가 있는 것은 아니고 시작점을 기준으로 가장 가까이에 있는 녀석을 방문할려고 노력을 함.
문제점 ❗❗
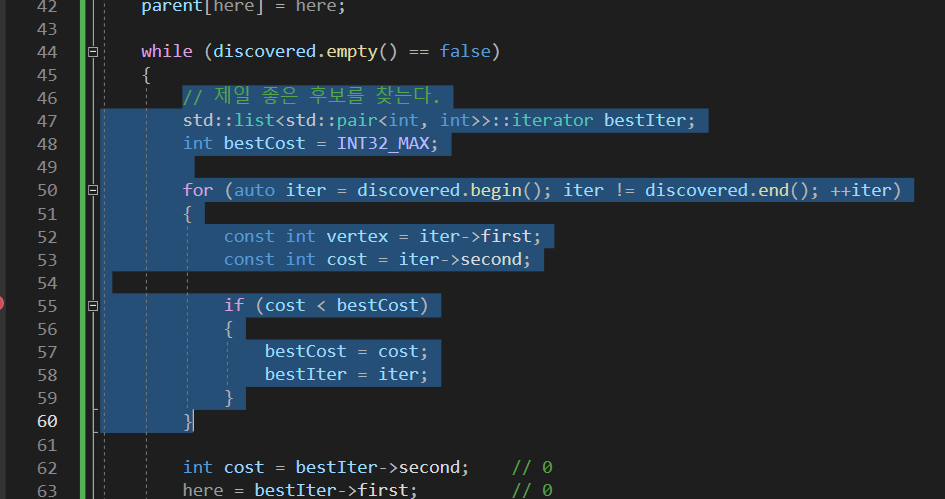
지금은 데이터가별로 없어서 상관없는데 스타같은거 데이터 개많을 경우
제일좋은 후보를 찾는 부분에서 굉장히 심한 낭비가 된다.
그래서 그냥 제일 좋은 후보를 바로 찾아주는 자료구조가 있다면 어떨까??
그렇다면 훨씬더 효율적이 된다.
그래서 이부분을 가장 효율적으로 처리를 해주는 부분이
PriorityQueue 우선순위 큐가 있다.
std::priority_queue를 제공을 하지만 어떻게 동작을 하는지 반드시 숙지를 해야한다.
