Question Answering?
question answering의 목표는 인간의 언어로 이뤄진 질문에 대해 자동적으로 대답하는 시스템을 만드는 것
시스템을 만드는데, text passage, 모든 웹 문서, knowledge bases, image 등이 쓰이고, question, answer의 종류도 여러가지가 있다
Reading comprehension
문제와 함께 주어지는 passage를 이해하고 질문에 답하는 것 (P, Q) → A
많은 실제 상황에 유용하고, 컴퓨터 시스템이 실제로 인간의 언어를 얼마나 잘 이해하는지 평가하는 중요한 요소가 된다.
Stanford question answering dataset (SQuAD)
(passage, question, answer)의 형태로 이뤄진 100k개의 dataset, reading comprehension을 위해 효과적으로 neural network를 학습시킬 중요한 supervised dataset.
영문 위키피디아에서 passage가 만들어졌고, 100~150단어로 이뤄져 있다. question은 crowd-sourced되어 있다. 각각의 답은 passage안에 존재하는 짧은 segment of word로 이뤄져 있다. → 이건 단점으로 꼽히는데 실제 문제들은 더욱 다양한 대답을 요구하기 때문. 하지만 여전히 인기있는 dataset
정확히 일치하는지 (0 or 1), F1 (부분 점수)로 평가한다. test set에서 3개의 gold answers가 수집된다. 왜냐하면 다수의 가능성있는 답들이 존재할 수 있기 때문에. 예측된 답과 각각의 gold answer와 비교한다.
BiDAF: the Bidirectional Attention Flow model
GloVe의 word embedding과 CNN을 이용한 character embedding을 concat하여 context, query에 사용한다.
두개의 독립적인 bidirectional LSTM을 사용해서 contextual embedding을 만들어 낸다.
Attention layer
- Context-to-query attention
- Query-to-context attention
Modeling layer
attention layer는 query와 context간의 상호작용이었다면, modeling layer는 context words간의 상호작용
Output layer
start, end 두 지점을 예측하는 두개의 classifiers
BERT for reading comprehension
question = segment A
passage = segment B
answer = predicting two endpoints in segment B
Open-domain question answering
reading comprehension과는 다르게 주어진 passage를 추정하지 않는다. 대신 우리는 large collection of documents를 사용하고, 어디에 답이 있는지를 찾는 것이 아니라, 어떤 open-domain에서든지 답을 return할 수 있어야 한다.
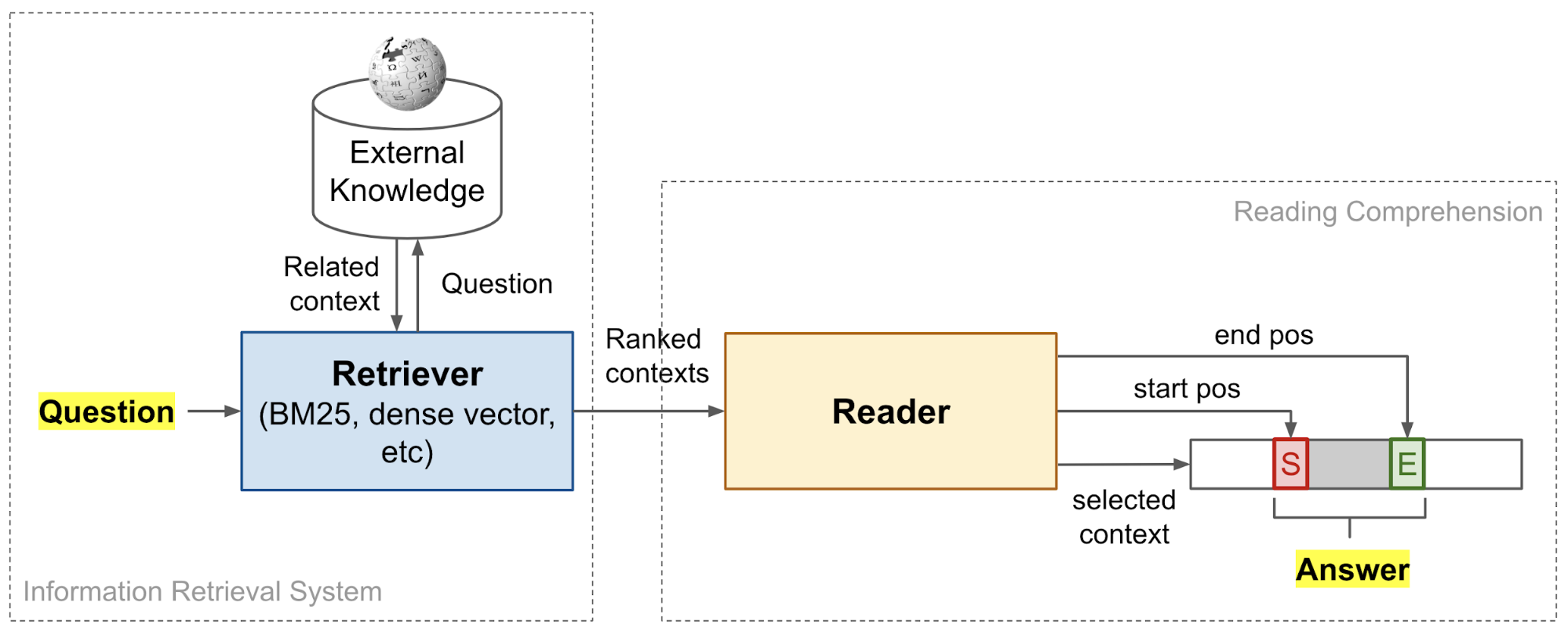
Retriever-reader framework
retriever 모델에 documents와 query를 넣어서 top-k개의 passage를 뽑아낸다. 그리고 나서 reader 모델에서 reading comprehension problem을 해결하면 된다.
Facebook의 DrQA는
- retrieval = standard tf-idf information-retrieval sparse model
- reader = neural reading comprehension model that we just learned
Dense retrieval + generative models
최근의 연구들은 답을 추출하는 것 보다, 답을 생성하는 것에 이득을 더 많이 본다는 것을 보여준다. → DPR + T5
retriever, reader model이 필요 없을 수도 있다.
- retriever → T5하나로 대체
- reader → dense vector를 사용해서 모든 phrase를 encoding하여 BERT 모델 없이 nearest neighbor를 사용한다.
