Subwords models
training set에 들어있는 수만개의 단어로 vocab을 만들어낸다. 하지만, test time때 새로 본 단어는 UNK로 mapping한다. 따라서 유한한 vocabulary로는 많은 언어들에 대해서 조금 밖에 추정하지 못함.
따라서 현재 NLP에서는 subword modeling을 사용해서 단어를 쪼개서 vocabulary를 만듦. 주된 패러다임은 parts of words (subword tokens)
Byte-pair encoding은 subword vocab을 만드는 간단하고 효율적인 전략
다음과 같은 과정을 거침
- 문자와, end-of-word symbol로 시작
- corpus of text를 사용해서 가장 많이 인접한 문자들을 찾음 (ex. a,b이면 ab를 subword에 넣음)
- vocab size를 만족할 때까지, 문자를 subword로 대체한다.

Pretrained word embeddings
”You shall know a word by the company it keeps” (J. R. Firth 1957: 11)
지금까지 word embedding만을 pre-training했다. 이 결과 두 가지 문제점이 발생했는데,
- downstream task를 수행하기 위해 많은 충분한 데이터를 필요로 한다.
- 모델의 파라미터가 대부분 random initialized 되어 있다. (따라서 전부 다 학습해야 한다 → cost가 너무 많이 든다)
따라서 현대 NLP에서는 모든 모델이 pretraining으로 파라미터를 초기화 한다.
Pretraining through language modeling
Language modeling이란, 이전 context가 주어졌을 때, 다음 단어의 확률 분포를 예측하는 task이다. (Decoder만 사용) 두 가지 과정으로 모델을 학습한다
- pre-train (on language modeling) → 많은 텍스트로 일반적인 것을 학습함
- Finetune (on your task) → 많은 레이블이 없어도 된다. task specific하게 학습
Pretraining for three types if architectures
세 가지 종류의 pre-train 방법이 있다.
- Decoders
- language modeling task로 학습하고, 생성하는 task에 유리하다
- Encoders
- 양방향 context를 얻게 된다. 어떻게 학습해야 할지?
- Encoders-Decoders
- encoder-decoder의 장점을 모아둠
- 어떻게 학습할 수 있을까?
Pretraining Decoders
마지막 단어의 hidden state에서의 classifier를 학습하면서 finetuning함
decoder를 language model로 여기고 학습하는 것이 자연스럽고 주로 generator로 사용된다. 즉 output이 sequence인 task에서 유리하다 (dialogue, summarization)
GPT
2018년에 나온 GPT가 pretraining을 한 decoder의 대명사.
- 12 layer의 transformer decoder
- 768d의 hidden states, 3072d의 feed-forward hidden layers
- 40000개의 byte-pair encoding
- 7000개가 넘는 책들로 이뤄진 dataset → 긴 문장들이 많아서 long-distance dependencies를 학습하기 편함
finetuning task로 NLI를 수행 → 두 문장이 주어지면, 두 문장이 비슷한지 모순인지 중립인지 결정하는 task
GPT2
더 많은 데이터로 학습한 GPT의 large version
Pretraining Encoders
language modeling pretraining을 봤는데, encoder pretraining은 language modeling으로 학습할 수 없다. → 양방향 context를 얻기 때문에.
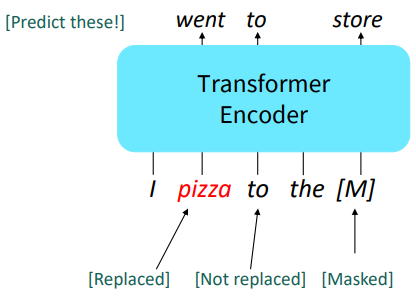
따라서 문장의 일부를 special token [MASK]로 대체한 다음, 그것을 예측하는 task를 수행하면 된다. → Masked LM
BERT
2018년에 Masked LM으로 pretraining한 BERT가 나오게 되었다.
- random하게 선택된 15%의 word를 예측한다
- training time의 80%동안, 단어를 mask로 바꾼다
- 10% 시간 동안은 random한 단어로 바꾼다
- 나머지 10% 시간 동안은 그대로 놔둔다 (그래도 예측은 함)
- 두개의 모델이 공개되었는데, base와 large. dimension, attention heads, parameter에서 차이가 난다
- GPT가 학습했던 BooksCorpus와 더불어 영문판 위키피디아도 학습에 사용하였다
- pretraining은 비싸지만, finetuning은 실용적이다.
Limitation of pretrained encoders
이렇게 성능이 좋은데 왜 모든 task에 pretrained encoder를 사용하지 않을까?
→ 기본적으로 BERT와 같은 pretrained encoders의 경우, auto-regressive(1-word-at-a-time) 하지 않음 , 즉 text를 생성하는 task에는 약함.
Extensions of BERT
BERT의 성공으로 여러 확장 버전이 나오게 되었다. 그중에서 살펴볼 것은 RoBERTa, SpanBERT
RoBERTa는 BERT를 더 길게 학습하고 다음 문장 예측하는 부분을 제거했다. BERT가 아직 underfitting되어있다는 것을 확인하고, 더 많은 데이터로 더 많은 연산을 오래 했다.
SpanBERT는 단어를 masking할때, contiguous 하게 masking을 해서 좀 더 효율적인 pretraining을 이뤄냈다.
Pretraining encoder-decoder
encoder-decoder는 language modeling처럼 작동하지만, encoder로 들어온 input은 예측하지 않는다. encoder부분은 양방향 context를 가진다는 점에서 장점을 가지고 decoder 부분은 language modeling으로 전체 모델을 학습할 수 있다는 점에서 장점을 가짐
T5
input으로 들어오는 일부분을 다른 길이의 spans로 대체한다. decoder에서 그걸 예측. T5는 넓은 영역의 질문에 대해서 답을 하도록 fine-tuning되었다.
GPT-3
지금 까지 두가지 흐름으로 모델을 학습했다. pretrain → finetuning
매우 큰 language model의 경우 gradient step없이 학습 할때 제공한 context안의 example로 학습한다. GPT-3은 무려 175billion의 파라미터로 이를 가능하게 했다. (in-context learning)
