Issues with recurrent model
- Linear interaction distance Recurrent Model은 left-to-right, 멀리 떨어진 단어들끼리의 관계를 나타내기 위해서 O(sequence length)만큼이 소요된다. 따라서 Long-distance dependencies가 나타남 (gradient problems)
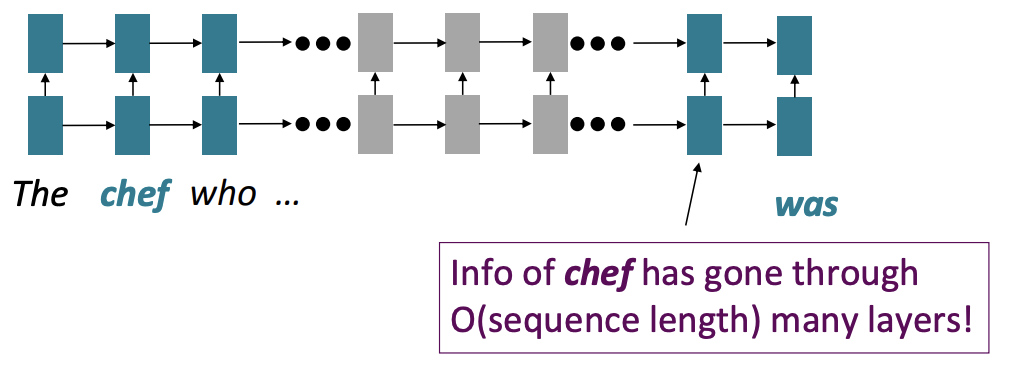
- Lack of parallelizability forward and backward pass에 O(sequence length)만큼이 소요된다. 또한 이전 hidden states를 계산하지 않고서 현재 state를 계산할 수 없다. GPU는 여러 독립적인 계산을 한번에 수행해주는데, 이러한 GPU의 이점을 활용할 수 없다 → 따라서 너무 느림
How about word windows?
word window models는 local contexts를 잘 활용한다. 그런데 sequence가 너무 길면, window 안에 있지 않은 토큰들이 발생해서, window안에 있는 token은 그것들과 상호작용할 수 없다.
How about attention?
attention은 단어의 representation을 query와 value로 다룬다. maximum interation distance → O(1) 왜냐하면 모든 단어들이 서로 상호 작용하기 때문에.
Self-Attention
attention은 queries, keys, values를 다룬다. self-attention에서는 query, key, value가 모두 같은 source에서 나온다.

self-attentions는 순서를 고려하지 않는다. 근데 자연어는 필연적으로 순서가 존재하는데?
self-attention problem
- sequence order가 없다. self-attention은 순서 정보를 만들지 않기 때문에, key, query, value의 순서 정보를 encoding 해야함. query, key, value vector에 순서 벡터를 더한다. sin, cos 함수로 순서 벡터를 구함. 주기 함수는 절대적인 위치가 중요하지 않음, 그러나 학습 불가능. absolute position representation은 모든 순서 벡터가 학습가능한 파라미터, 각각의 position은 data에 맞게 학습된다.
- attention만으로 non-linear를 구현할 수 없음, feed-forward network를 attention layer이후에 추가한다.
- “don’t look at the future when predicting a sequence” → decoder의 input으로 들어가는 문장을 처음부터 다 봐버리면, 이것을 그대로 기억하고 decoder의 output으로 내보낼 가능성이 있기 때문에, decoder에 들어가는 input에 masking을 한다. (-inf로 매핑)
Transformer
기본적으로 encoder + decoder, 이 외에도 몇 가지 트릭이 있다.
- Residual connections
- layer normalization
- scaling the dot product
이 트릭들은 성능을 높여주는 것이 아닌 학습을 도와주는 것
key, query, value는 모두 같은 source에서 나오고, 각각의 서로 다른 matrix로 weighted된다. 이게 세개를 서로 다른 역할을 하도록 만든다.
Multi-headed attention은 문장 내에서 한번에 다수의 places를 보려고 사용. h개의 head마다의 attention을 구함. 각각의 head는 서로 다른 것을 보게 되고 서로 다른 value vector를 구성.
residual connection은 학습을 좀 더 smooth하게 쉽게 만들어줌
layer normalization도 학습을 좀 더 빠르게 하도록 만들어주는데, hidden vector values에서의 uninformative variation을 cut down (각각의 layer마다)
model dimension이 커지면 attention score가 너무 커지게 되어, gradient가 작아지는 현상이 발생하게 된다. 이 경우를 막기 위해, sqrt(d/h)로 나눠준다 → scaled dot product
Cross-attention은 decoder에서 나오는 attention인데, 기존의 self-attention과는 달리, key, value는 encoder에서, query는 decoder의 input으로 주어진다.
transformer는 많은 태스크에서 좋은 성능을 달성하였다.
단점으로는,
- parallelizable하지만, self-attention의 연산은 너무나도 비용이 크다는 것, O(T^2d) (quadratic하게 증가, recurrent model은 linear하게 → sequence의 길이만큼)
- position representations
