요약
- Multi-lingual bert 의 차원을 축소시킬 방법으로 auto encoder 를 사용할 수 있을지(loss 값이 줄어드는 등 학습이 잘 진행되는지), 적절한 layer 갯수와, layer dimension은 무엇일지 확인한다.
- 실험결과, auto encoder 로 dimension reduction을 하는 것이 유효함을 알 수 있고(loss 값이 줄어드는 등 학습이 잘 진행됨을 알 수 있었음), layer 는 4단, 이때 dense layer 의 dimension 구성은 input layer 부터 bottle neck까지 균일하게 줄일 때보다, bottle neck 과 유사한 dimension의 layer 이 더 많을때에 더 높은 성능을 보임을 알 수 있었다.
- 실험결과, 적절한 데이터의 양을 100만 row, epoch 10회 이하라고 가정한다면 layer 4단까지가 적절한 것으로 보인다.
- encoder 의 layer dimension을 input layer 부터 bottle neck까지 균일하게 줄일 때보다, bottle neck 과 유사한 dimension의 layer 를 더 많이 쌓을때에 loss 값이 더 낮음을 확인할 수 있다.
실험 목표
- Multi-lingual bert 의 차원을 축소시킬 알고리즘으로 auto encoder 를 사용할 수 있을지(loss 값이 줄어드는 등 학습이 잘 진행되는지), 적절한 layer 갯수와, layer dimension은 무엇일지 확인한다.
Auto encoder 란?
- input vector 를 encoder layer 를 거쳐서 bottle neck layer 의 dimension 만큼 줄였다가, 다시 decoder layer 를 통해 output 을 input 의 크기만큼 확장한다.
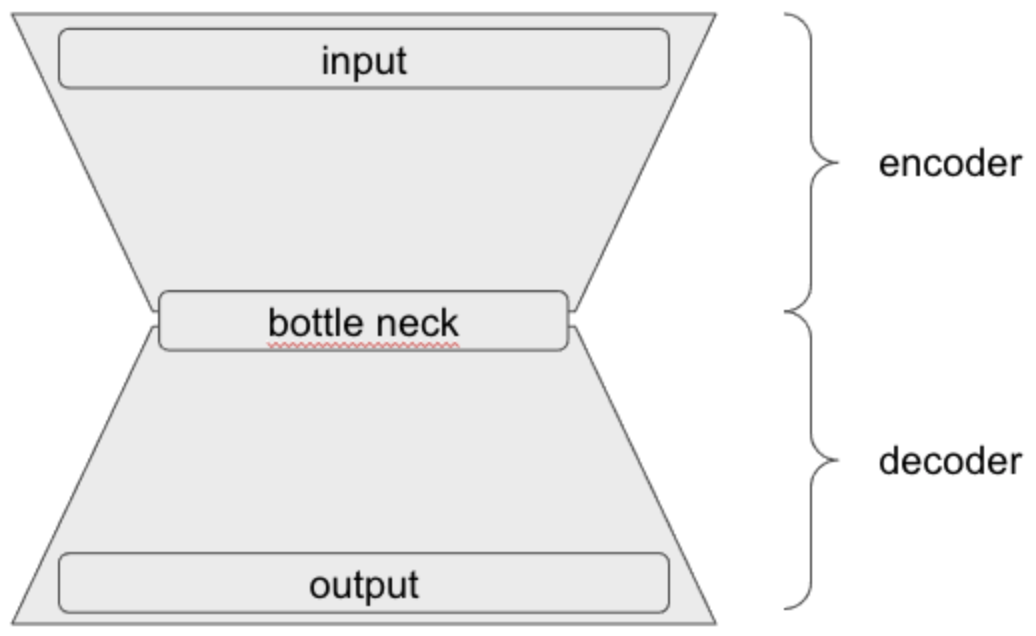
- output 을 input 과 최대한 가까운 값을 낼 수 있도록 학습하는 과정을 통해서, encoder layer 를 활용한 차원 축소와 decoder layer 를 통한 데이터 복원을 가능하게 한다.
- 우리는 이 중 encoder를 사용하여, bert 의 차원 축소에 활용할 수 있을지 그 가능성을 보고자 한다.
실험 방법
- input 과 auto encoder 를 통과한(차원을 축소 한 후 다시 복원한) 결과의 차이를 mse loss 로 계산한다.
- auto encoder 의 encoder layer 수와 layer내부의 차원을 바꿔가면서 loss 값을 비교하여 더 적절한 Layer 구성을 알아낸다.
- 단, 이때 decoder 성능에 의한 loss 값 차이를 막기 위해 decoder부분의 layer 는 1단으로 모든 실험에서 동일하게 유지한다. (우리의 목표는 차원축소를 잘 하는 것 이므로)
- activation function과 optimizer, learning rate 는 실험 대상이 되는 autoencoder 중 가장 작은 것에 일단 최적화 시킨 후 나머지 모델에도 동일하게 적용하여 학습한다.
데이터
- 크롤링한 뉴스기사 제목, 내용 데이터(약 100만건) 활용하여 autoencoder 학습
(2021-10-29 01시 ~ 2021-10-31 04시) - 100만 개 데이터에서 10%를 test, 90%를 train 에 활용하여 loss 값을 비교한다.
실험 결과
encoder layer 갯수에 따른 test set loss값 비교
input 에서 bottle neck 까지 layer 크기를 균일하게 감소시키기

- epoch 을 10회까지 증가시키면 2단, 3단까지 쌓은 layer 에서는 오히려 epoch 5회일때보다 loss 값이 증가한다.
- epoch 상관없이 layer 갯수당 최소 loss 값 : 3단 > 2단 > 5단 > 4단
- encoder 에 layer 를 추가하면 capacity 는 커지는 반면 tuning 이 필요한 parameter 는 증가한다. 2단에서 3단으로 갈 때, 4단에서 5단으로 갈 때에는 이런 이유로 오히려 loss 값이 증가하는것으로 볼 수 있다. (epoch 을 이 이상으로 증가시킨다면 5단에서 더 성능이 좋을지도)
- epoch 을 증가시킬수록, 데이터를 증가시킬수록, 더 많은 layer 를 쌓았을때에 좋은 성능을 보여줄수도 있지만, 그 만큼 학습에 들어가는 비용이 커진다.
- 적절한 데이터의 양을 100만 row, epoch수를 10회 이하라고 가정한다면 layer 4단까지가 적절할 것이라 생각된다.
4단 auto encoder에서 layer 구성에 따른 loss 값 비교
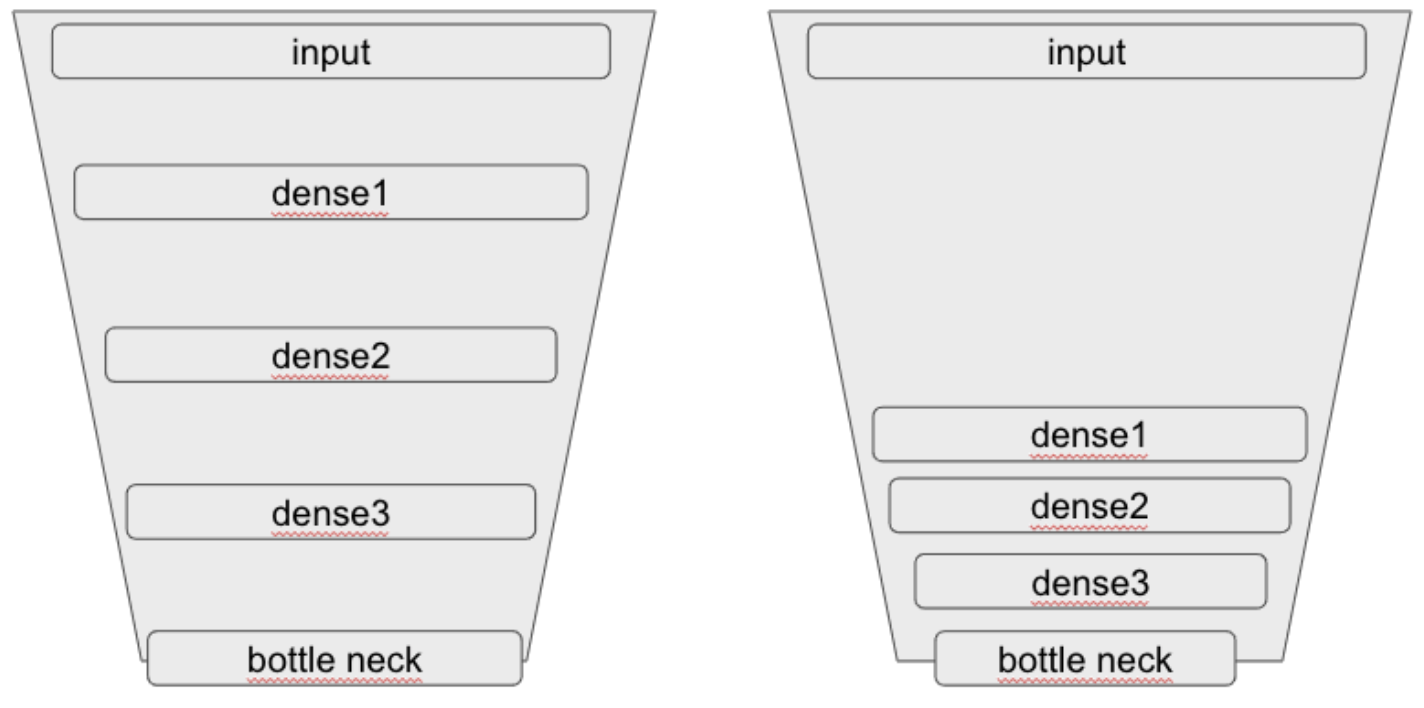
- 이전 실험을 진행하면서, layer 쌓는 방식을 다양하게 시도해봤는데, bottle neck layer 주변에 layer 를 더 많이 쌓았을 경우에 loss 값이 더 많이 감소하는 것 같은 모습이 관찰됐다. 이와 같은 관찰에 대해 정량적으로 확인하기 위해 실험을 진행했다.
- 위의 그림과 같이 layer 의 dimension을 bottle neck 까지 균일하게 감소시켰을때와, bottle neck 부분에 더 많이 쌓았을 때 각각에 대해 학습시키고 loss 값을 비교했다

- 위의 표를 보면 bottle neck 주변으로 layer 를 모았을때에 loss 값이 점점 더 낮아지고 있음을 확인할 수 있다.

data scientist