요약
- TFX 가 뭐고, 어떤 구성요소, 라이브러리를 포함하는지 확인한다. 또한 우리 시스템에 적용이 가능한 부분이 있는지 확인한다.
- 특히 TFX라이브러리 중 TFT(TensorFlow Transform)부분만 독립형 라이브러리로 사용해본 바 있는데, 아래 네개 구성요소에 대해서 활용해도 좋을 것 같다는 생각이 든다.
- StatisticsGen : 인풋데이터의 통계를 계산 → 지금은 feature null ratio 계산하는 부분 다른 잡으로 두고 있는데 이걸 대체 시켜도 될 듯
- ExampleValidator : 인풋 데이터에서 이상치 및 누락된 값 찾기 → 지금은 없음
- Tuner : 모델 hyperparameter 조정 → 지금은 hyper parameter tuning 전혀 안하고 있는데 이거 정기적으로 하도록 수정이 가능하다
- Evaluator : 학습 결과를 분석(auc등 도출)해서 이전 모델과 비교하여 현재 모델이 프로덕션에 푸시할 수 있을 정도로 '좋은' 상태인지 확인 → 지금은 검증 없이 그냥 올리고, 문제 있을 경우에만 확인해서 후 조치.
무엇?
- Google 에서 제공하는 MLOps 플랫폼 자체
- TensorFlow를 기반 머신러닝 시스템을 정의, 시작, 모니터링하는 데 공통으로 필요한 구성요소, 라이브러리들을 통합적으로 제공한다
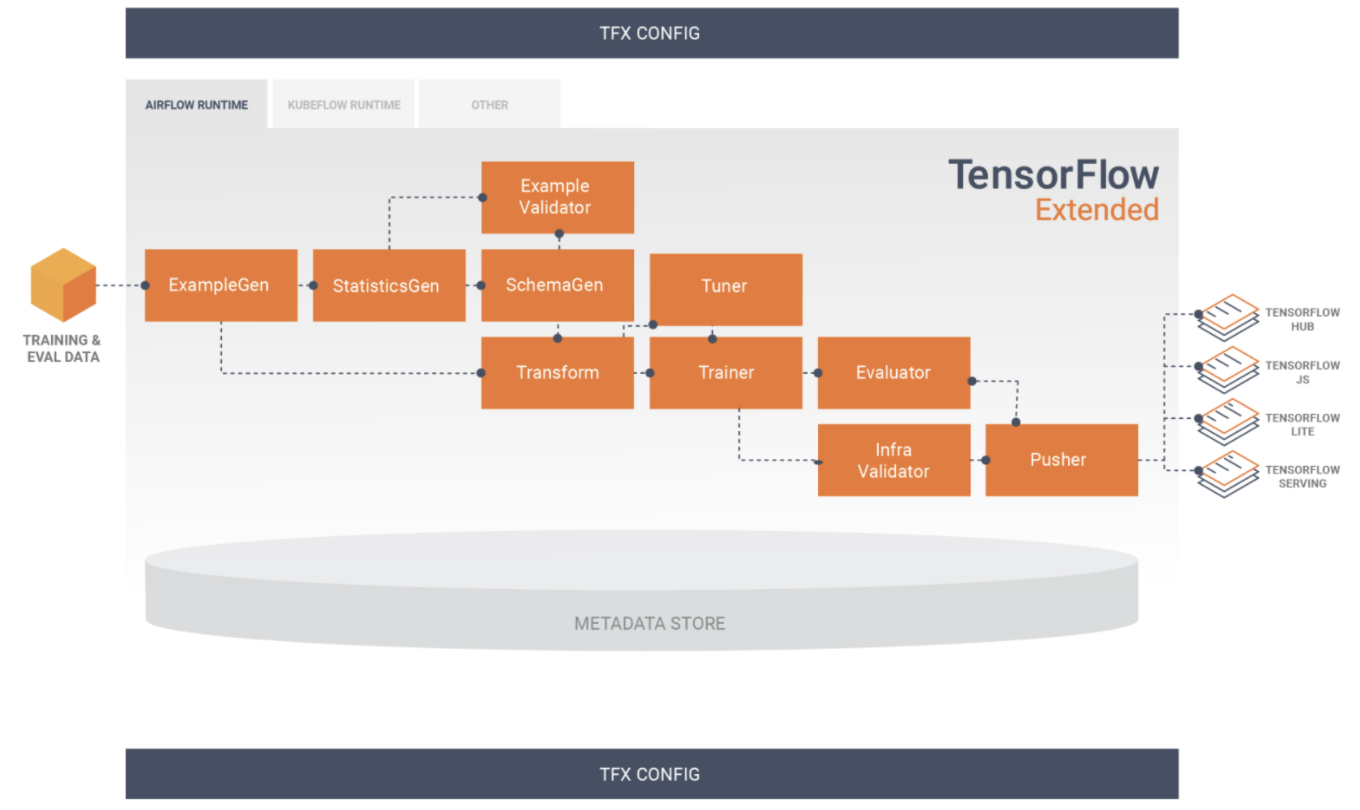
- 데이터 입력(csv, tfrecord 등등의 형태, 선행 플랫폼은 gcp) → kubeflow, airflow, beam 등으로 orchestrating → TFT(TensorFlow Transform)으로 feature화 및 전처리 → Tensorflow 로 학습해서 모델 내보내기(Pusher) → Tensorflow serving 으로 서빙 → TFDV(TensorFlow DataValidation)등으로 모니터링
제공
구체적으로는 아래 세가지를 제공한다고 함
- ml pipeline과 build 를 위한 toolkit
- 표준 구성 요소
- TFX 라이브러리
1. ml pipeline과 build 를 위한 toolkit
- tfx pipeline 쓰면 airflow, apach beam, kubeflow 등에서 ml 워크플로우 조정 가능
- ml 의 주기적 학습과 데이터 적재를 위해서 에어플로우, 쿠베 플로우 등을 사용할 수 있을텐데, 이걸 tfx pipeline에 통합해서 사용이 가능한 듯
2. 표준 구성 요소
-
파이프라인의 일부 혹은 모델 학습 스크립트에 일부로 사용될 수 있는 표준 구성요소의 집합
-
즉, ml pipeline을 구현하는 일련의 구성요소 자체들(모델링, 학습, 추론 제공 및 배포 관리가 포함됨)
-
여러가지가 있지만 이것들중 일부는 kubernetes에서만 지원한다거나 tfx 전체를 써야만 이용 가능하다거나 한 게 있어서 주의해야한다.
-
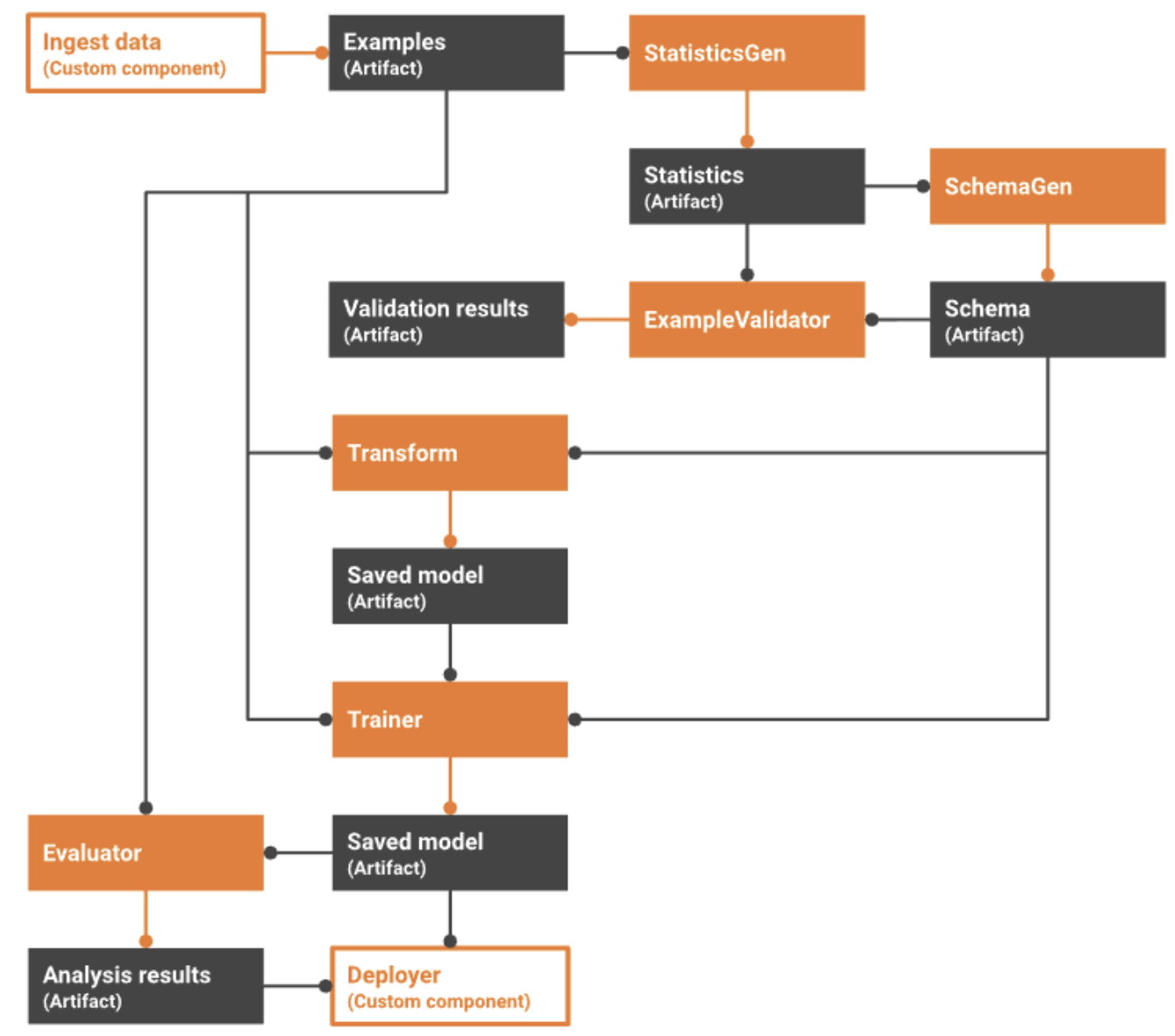
ExampleGen : 입력 데이터 세트를 수집하고 선택적으로 분할하는 파이프라인의 초기 입력 구성요소 (즉, 데이터 입력 부분)
- 입력: CSV,
TFRecord, Avro, Parquet 및 BigQuery와 같은 외부 데이터 소스의 데이터 / 출력: 페이로드 형식에 따라tf.Example레코드,tf.SequenceExample레코드 또는 proto 형식 - 빅쿼리 쓰고 있다면 쿼리기반으로 바로 연결할 수도 있음 (이게 빅쿼리만 되는게 너무 아쉬움 ㅠ 회사에서 주로 아테나 쓰는데 이게 가능한거면 앞에 있는 데이터 밸런스 맞추는 전처리 spark 코드 다 드러낼 수 있을 것 ㅠ)
- 빅쿼리 안쓰고 있으면 파일을 읽어와서 쓰면 됨(
https://www.tensorflow.org/tfx/guide/examplegen#%ED%8C%8C%EC%9D%BC_%EA%B8%B0%EB%B0%98_examplegen) - 이 다음으로 statistics gen, schema gen, example validator, transform, trainer, tuner, evaluator 를 쭉 쓸 수 있음
- 입력: CSV,
-
StatisticsGen : 데이터 세트의 통계를 계산
- 입력: ExampleGen 파이프라인 구성 요소로 만들어진 데이터세트 / 출력: 데이터세트 통계
-
SchemaGen : 통계를 검사하고 데이터 스키마를 생성
- examplegen 이랑 statistics gen 의 결과 받아서 스키마 생성한다.
- (회사에서는 tfx 안쓰고 transform 만 썼는데, 그러다보니 여기서 생성해주는 schema 없어서 이런 경우에는 schema 정의를 수동으로 해주면 된다)
-
ExampleValidator : 데이터 세트에서 이상치 및 누락된 값을 찾는다.
- 여기서 TFDV(TensorFlow Data Validation) 라이브러리 이용하는 것(https://www.tensorflow.org/tfx/guide/tfdv)
- 스키마가 잘못들어온건 없는지, 학습 데이터가 imbalanced 돼있는지는 않은지를 체크해준다.
-
Transform : feature 추출
- 입력: ExampleGen 구성 요소의 tf.Examples 및 SchemaGen 구성 요소의 데이터 스키마 / 출력: SavedModel을 Trainer 구성 요소로
- 들어온 데이터를 feature 화 하는것까지 담당하는걸 목표로 하는 듯
- 근데 사실 해주는게 embedding, scaling 등 같은 기본적인것들밖에 없고 이 안에 또다른 모델을 삽입하거나 하는게 없어서, 거기까지 기대하기는 쉽지 않음
- 이부분은 TFT(TensorFlow Transform) 라이브러리 쓰는건데, 이거는 TFX 전체를 쓰지 않더라도 따올 수 있는 부분이라 현재 우리 모델에서도 이용하고 있음
- 이게 있으면 scaling 등의 전처리를 모델 그래프에 포함시킬 수 있게 돼서 데이터 관리가 매우 쉬워짐
- 이걸 안쓴다면 학습 데이터 앞에, 그리고 inference 하기 직전에 각각 따로 전처리 과정을 적용하게 된다. 즉 전처리 코드를 python구현, typescript 구현 두가지가 각각 존재하게 되어 그 관리가 매우 어려워짐.
-
Tuner : 모델 hyperparameter 조정
- 올해(2021년) 9월까지만해도 이 내용 없었던 것 같은데 새로 생겼나보다!
- 모델 재학습할때마다 계속 조정하게 할 수도 있고, 이전에 조정했던 내용을 갖고 오게 할 수도 있다고 한다
- 지금은 keras 모델만 가능하다.
- 업무에 새로 적용하는거 생각해보자!
-
Evaluator : 학습 결과를 분석(auc등 도출)해서 이전 모델과 비교하여 현재 모델이내보낼 모델을 검증하여 프로덕션에 푸시할 수 있을 정도로 '좋은' 상태인지 확인
- 검증이 활성화되면 Evaluator는 새 모델을 기준선(예: 현재 제공 중인 모델)과 비교하여 기준선에 비해 "충분히 좋은지" 확인. 이를 위해, 평가 데이터세트에서 두 모델을 모두 평가하고 메트릭(예: AUC, 손실)의 성능을 계산. 새 모델의 메트릭이 기준선 모델과 관련하여 개발자가 지정한 기준을 충족하면(예: AUC가 더 낮지 않음) 모델이 "탄생"(양호로 표시됨)하여 Pusher에 모델을 프로덕션 환경으로 푸시해도 괜찮음을 나타낸다.
- TMA(TensorFlow Model Analysis) 라이브러리 이용하는 부분
- 이것도 독립형 라이브러리로 사용이 가능하다(tfx사용 안해도 쓸 수 있다.)
- 지원되는 모델 유형(tf2 keras 등)이 몇가지로 정해져있어서 주의해야한다
-
InfraValidator: 모델이 인프라에서 실제로 제공 가능한지 확인, 잘못된 모델이 푸시되지 않도록 한다.
- 앞에서의 Evaluator 가 모델의 성능을 보장한다면, InfraValidator는 모델이 기계적으로 정상인지 확인하고 잘못된 모델이 배포되는 것을 방지한다.
-
Pusher: 인프라에 모델 배포
- 위의 evaluator 랑 infra validator에서 검증이 만족되면, tensorflow serving 등에 배포한다.
3. TFX 라이브러리
-
아래의 라이브러리들은 tfx구성을 다 쓰지 않더라도 독립형 라이브러리로 제공한다.
-
TensorFlow Data Validation(TFDV): 머신러닝 데이터를 분석하고 검증하기 위한 라이브러리. 확장성이 뛰어나고 TensorFlow 및 TFX와 원활하게 연동되도록 설계됐다.
- 학습 및 테스트 데이터에 관한 요약 통계의 확장 가능한 계산
- 데이터 분포 및 통계를 위한 뷰어와의 통합 및 데이터세트 쌍(패싯)의 패싯 구조 비교
- 필수 값, 범위 및 어휘와 같은 데이터에 관한 기대치를 설명하는 자동화된 데이터 스키마 생성
- 스키마를 검사하는 데 도움이 되는 스키마 뷰어
- 누락된 특성, 범위를 벗어난 값 또는 잘못된 특성 유형 등과 같은 이상치를 식별하기 위한 이상 감지
- 이상치가 있는 특성을 확인하고 문제를 수정하기 위해 자세히 알아볼 수 있는 이상치 뷰어
-
TensorFlow Transform(TFT): TensorFlow를 사용하여 데이터를 전처리하기 위한 라이브러리.
- 평균 및 표준 편차로 입력 값을 정규화
- 모든 입력 값에 걸쳐 어휘를 생성하여 문자열을 정수로 변환
- 관찰된 데이터 분포를 기반으로 부동 소수점 수를 버킷에 할당하여 부동 소수점 수를 정수로 변환
-
TensorFlow: TFX를 통한 모델 학습에 사용됩니다. 학습 데이터 및 모델링 코드를 수집하며 SavedModel 결과를 생성. 또한 입력 데이터 사전 처리를 위해 TensorFlow Transform에서 생성한 특성 추출 파이프라인을 통합한다.
-
TensorFlow Model Analysis(TFMA): 모델을 평가하기 위한 라이브러리. TensorFlow와 함께 사용되어 EvalSavedModel을 생성하며, EvalSavedModel은 분석의 기초가 됩니다. TFMA를 통해 사용자는 트레이너에 정의된 것과 동일한 측정항목을 사용하여 분산된 방식으로 대량의 데이터에서 모델을 평가한다. 이러한 측정항목은 다양한 데이터 슬라이스에 걸쳐 계산되어 Jupyter 메모장에서 시각화될 수 있다.
-
TensorFlow Metadata(TFMD): TensorFlow를 사용하여 머신러닝 모델을 학습시킬 때 유용한 메타데이터의 표준 표현을 제공. 메타데이터는 입력 데이터 분석 중에 수동으로 또는 자동으로 생성될 수 있으며, 데이터 유효성 검사, 탐색 분석 및 변환에 사용된다. 메타데이터 직렬화 형식에는 아래 두가지가 포함된다.
- 테이블 형식 데이터를 설명하는 스키마(예: tf.Examples)
- 이러한 데이터 세트에 걸친 요약 통계 컬렉션
-
ML Metadata(MLMD): ML 개발자 및 데이터 과학자 워크플로와 관련된 메타데이터를 기록하고 검색하기 위한 라이브러리. 대체로 메타데이터는 위에서 말한 TFMD 표현을 사용한다.. MLMD는 SQL-Lite, MySQL 및 기타 유사한 데이터 저장소를 사용하여 지속성을 관리한다.
- validator 결과를 여기다가 쭉 저장해놨다가 나중에 검색해서 쓰는 용도
- 이것도 쓰면 좋을텐데, 시간이 될지 모르겠다.
