
2차원 히스토그램을 화면에 출력하기
컬러 영상에 대한 2차원 히스토그램(색상 및 채도)을 계산하고 화면에 출력한다.
해결 과정 및 주요 코드에 대한 설명
def histogram2D(img):
hist = cv2.calcHist([img], [0, 1], None, [180, 256], [0, 180, 0, 256])
return histHSV 영상에서 색상과 채도는 각각 채널 0과 1번에 해당하기 때문에 이에 맞게 빈의 개수와 색상 및 채도 범위를 설정하여 하나의 리스트에 모두 포함하여 인자로 넘겨준다. 또한 두 개 이상의 채널에 대한 히스토그램을 계산할 경우에는 하나의 리스트에 채널별 값의 범위를 모두 포함해 제공한다.
ap = argparse.ArgumentParser()
ap.add_argument('-i', '--image', required = True, \
help = 'Path to the input image')
args = vars(ap.parse_args())
filename = args['image']i로 2D 히스토그램을 생성할 영상의 경로를 입력받는다. 받아온 값은 filename 변수에 저장한다.
실행 결과
- python histogram_2D.py --image ../images/nature.jpg 으로 명령을 주었을 경우
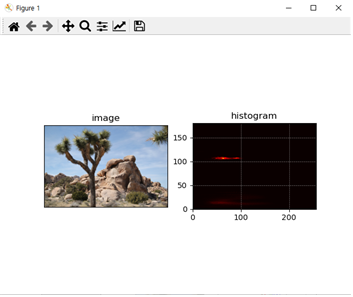
컬러 영상을 입력으로 주어 2차원의 히스토그램을 계산해 올바르게 화면상에 출력했음을 확인할 수 있었다.
코드
자세한 코드는 Github에서 확인할 수 있다.
컬러 히스토그램을 화면에 출력하기
그레이 스케일 영상뿐만이 아니라 컬러 영상에 대한 히스토그램을 계산하고 선 그래프를 사용하여 화면에 출력한다. 컬러 영상에 대한 히스토그램의 경우, 하나의 그래프로 세 개의 채널에 대한 히스토그램을 나타낼 수 있도록 한다.
해결 과정 및 주요 코드에 대한 설명
def histogram(img):
# 결과 히스토그램을 저장할 리스트
hist = []
if (len(image.shape) is 2):
temp = cv2.calcHist([img], [0], None, [256], [0, 256])
hist.append(temp)
else:
for i in range(3):
temp = cv2.calcHist([img], [i], None, [256], [0, 256])
hist.append(temp)
return hist그레이 스케일 영상인지 컬러 영상인지에 따라 calcHist의 횟수가 달라지기 때문에 if문을 통해 조건에서 입력 영상의 채널 수를 얻는다. 만약 len(image.shape) 값이 2일 경우 해당 영상은 그레이스케일 영상이라는 의미이기 때문에 calcHist 함수를 한 번만 사용하고 이 결과를 hist 리스트에 저장한다. len(image.shape) 값이 3일 경우 해당 영상은 컬러 영상이기에 그레이스케일 영상에서 진행했던 동일한 과정을 각각의 채널에 대해 3번 반복하여 이를 리스트에 모두 append하게 되면 하나의 그래프로 세 개의 채널에 대한 히스토그램 정보를 모두 나타낼 수 있게 된다.
ap = argparse.ArgumentParser()
ap.add_argument('-i', '--image', required = True, \
help = 'Path to the input image')
ap.add_argument('-t', '--histogram_type', \
type = int, required = True, \
help = 'histogram type(1: grayscale, 3: color')
args = vars(ap.parse_args())
filename = args['image']
histogram_type = args['histogram_type']i로 히스토그램을 계산할 영상의 경로를 입력받고 t를 통해 히스토그램의 타입을 입력받는다. type이 1일 경우 그레이 스케일 영상에 대한 히스토그램을 계산하여 그래프를 화면에 출력하게 되고, type이 3인 경우 컬러 영상에 대한 히스토그램을 계산하여 하나의 그래프로 세 개의 채널에 대한 히스토그램을 나타내게 된다. 받아온 값들을 filename, histogram_type 변수에 저장한다.
실행 결과
-
python histogram.py --image ../images/nature.jpg --histogram_type 1 으로 명령을 주었을 경우

입력받은 영상에 대한 히스토그램을 계산하여 그래프로 나타낸 결과를 확인할 수 있었다. -
python histogram.py --image ../images/nature.jpg --histogram_type 3 으로 명령을 주었을 경우
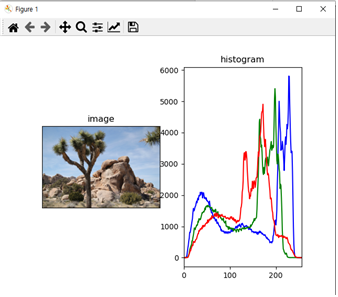
의도한 대로 하나의 그래프에 세 개의 컬러 채널에 대한 히스토그램 정보를 모두 출력했음을 확인할 수 있었다.
코드
자세한 코드는 Github에서 확인할 수 있다.
피부색 영역만을 검출하여 화면에 출력하기
비디오 또는 카메라 영상(컬러 영상)에서 피부색 영역을 검출하여 화면에 출력한다.
해결 과정 및 주요 코드에 대한 설명
def histogram_slicing(img, lowerb, upperb):
mask = cv2.inRange(img, lowerb, upperb)
blur = cv2.GaussianBlur(img, (5, 5), 0)
dst = cv2.bitwise_and(blur, blur, mask=mask)
return dstOpenCV의 inRange 함수를 사용해 histogram_slicing 함수에서 인자로 받은 영상에 대해 지정한 lowerb, upperb 범위 내부의 값으로만 구성되는 마스크를 생성한다. 이로부터 생성한 마스크에 (5, 5) 크기로 Gaussian Blurring을 처리해 노이즈를 제거한다. 마지막으로 비트 단위의 and 연산을 수행해서 최종적으로 피부색에 해당하는 영역만 검출될 수 있도록 하고, 이에 대한 결과값에 해당하는 영상을 함수 return 값으로 지정한다.
ap = argparse.ArgumentParser()
ap.add_argument("-v", "--video", required = False, \
help = "path to the video file")
args = vars(ap.parse_args())
fvideo = args.get("video")v로 피부색을 검출하고자 하는 영상의 경로를 입력받는다. 이는 옵션이기 때문에 생략 가능한데, 생략한 경우에는 카메라를 입력으로 사용하게 된다. 파일 경로를 받아온 값은 fvideo 변수에 저장한다.
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
dst = histogram_slicing(hsv, lowerb, upperb)
skin = cv2.cvtColor(dst, cv2.COLOR_HSV2BGR)먼저 cvtColor 함수를 이용하여 BGR 컬러 모델이었던 영상을 HSV 컬러 모델의 영상으로 변환한다. 이후 histogram slicing을 수행하고, slicing한 결과를 다시 BGR 컬러 공간으로 변환하는 작업을 거친다.
실행 결과
-
python skin_detector.py --image ../images/nature.jpg 으로 명령을 주었을 경우

-
python skin_detector.py --video ../videos/hand.avi 으로 명령을 주었을 경우

카메라를 입력받은 경우와 비디오 영상을 입력으로 받았을 때 모두 손에 해당하는 영역이 무난히 검출되었음을 확인할 수 있었다.
코드
자세한 코드는 Github에서 확인할 수 있다.
Watershed 변환을 사용한 영상 분할
Watershed 변환을 사용하여 영상 분할 결과를 확인한다.
해결 과정 및 주요 코드에 대한 설명
ap = argparse.ArgumentParser()
ap.add_argument('-i', '--image', required = True, help = 'Path to the input image')
args = vars(ap.parse_args())
filename = args['image']i로 watershed 변환을 적용할 영상의 경로를 입력받는다. 받아온 값은 filename 변수에 저장한다.
kernel = np.ones((3,3),np.uint8)
opening = cv2.morphologyEx(thresh,cv2.MORPH_OPEN,kernel, iterations = 2)
sure_bg = cv2.dilate(opening,kernel,iterations=3)
dist_transform = cv2.distanceTransform(opening,cv2.DIST_L2,5)
ret, sure_fg = cv2.threshold(dist_transform,0.7*dist_transform.max(),255,0)
sure_fg = np.uint8(sure_fg)
unknown = cv2.subtract(sure_bg,sure_fg)(3,3) kernel을 지정하여 morphology 연산 중 opening 연산을 적용하고, 침식을 통해 경계에 해당하는 픽셀을 제거한다. 이어서 object끼리 서로 접촉해 있을 경우에 대한 거리 변환 값을 찾아 적절히 threshold를 적용하는 과정도 진행한다. 이러한 과정을 거쳐 확실한 배경과 전경을 구해내면 subtract를 통해 실제 배경인지 아닌지를 확인할 수 있게 된다.
ret, markers = cv2.connectedComponents(sure_fg)
markers = markers+1
markers[unknown==255] = 0
markers = cv2.watershed(img,markers)
img[markers == -1] = [255,0,0]배경과 전경을 알게되면 connectedComponents 함수를 이용하여 영역에 레이블을 지정한다. 배경에는 0을, object에는 1부터 시작하는 정수로 레이블을 지정하게 된다. 최종적으로 watershed를 적용하면 boundary 영역에 대해서는 –1로 수정되어 마킹된다.
실행 결과
-
python watershed.py --image ../images/coins.jpg 으로 명령을 주었을 경우

-
python watershed.py --image ../images/nature.jpg 으로 명령을 주었을 경우

-
python watershed.py --image ../images/pumpkin.jpg 으로 명령을 주었을 경우

코드
자세한 코드는 Github에서 확인할 수 있다.
