개요
증권 데이터를 분석하고 AI 모델을 생성, 그 후 자동매매를 구현해본다.
이번 글에선 주식 데이터를 불러오고, 데이터를 분석한다.
내용은 해당 도서를 참조했다.
개발환경
OS : Window 11 Pro
RAM : 16.0GB
System type : 64bit
Python version : 3.12.2-64bit, 3.8.10-32bit(가상환경)
32비트 파이썬을 사용하는이유는 국내 증권사가 제공하는 대부분의 API가 32비트를 지원하기 때문이다.
32비트 가상환경 만들기
python -m venv 가상환경이름
notepad 가상환경이름\pyvenv.cfg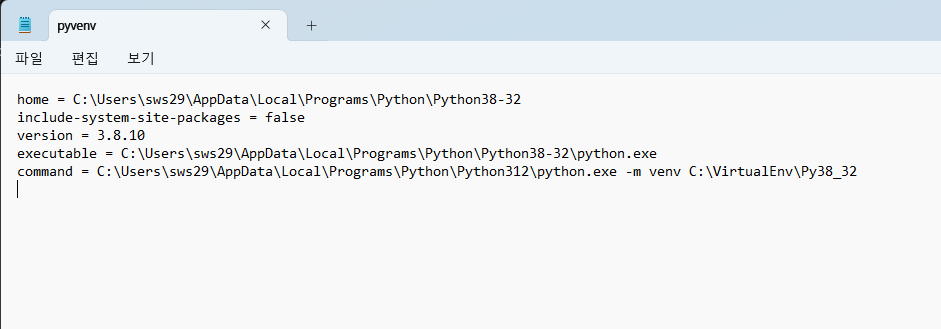
그 후 pyvenv.cfg 파일에서 home 및 excutable 경로를 다운받은 32비트 경로를 지정해준다.
야후 파이낸스로 주가 구하기
야후 파이낸스를 통해 주식 데이터를 얻을 수 있다.
미국 주식의 경우 데이터가 정확하지만, 국내 데이터의 경우 값이 누락되거나 틀린 경우가 있으니 주의하자.
pip install yfinance
pip install pandas-datareader주식 시세를 구하기 전 야후 파이낸스와 판다스-데이터리더 라이브러리를 설치해준다.
ModuleNotFoundError: No module named 'distutils’ 에러 관련
파이썬 3.12 버전부터 distutils를 제공하지 않는다고 한다
파이썬을 3.11로 다운그레이드하거나, pip install setuptools를 설치하여 해결한다
from pandas_datareader import data as pdr
import yfinance as yf
yf.pdr_override()
sec = pdr.get_data_yahoo('005930.KS', start='2023-04-01')
msft = pdr.get_data_yahoo('MSFT', start='2023-04-01')get_data_yahoo(주식 종목, start=시작일, end=종료일,)
pdr_override() 함수와 get_data_yahoo를 통해 주식 시세를 구할 수 있다.
국내 주식 데이터를 조회하기 위해선 6자리 코드 뒤에 코스피는 .KS, 코스닥은 .KQ를 붙인다.
미국 주식은 ‘AAPL’처럼 심볼을 사용한다
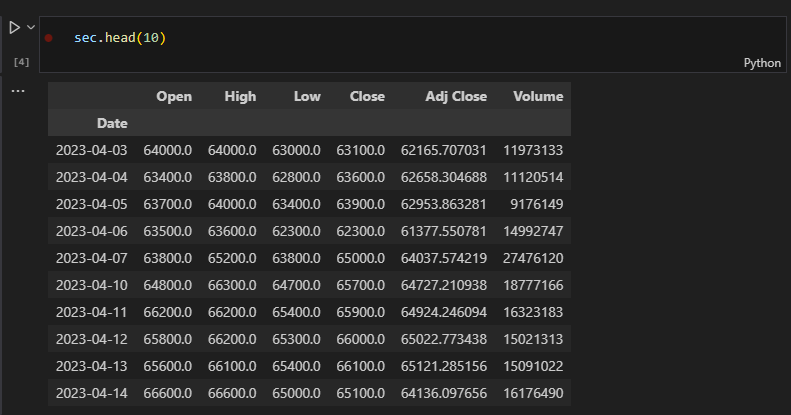
삼성전자의 2023년 4월 3일부터의 주가 데이터를 확인한다.
OHLC와 더불어 거래량(Volume)과 수정 종가(Adj Close)도 표시된다.
수정 종가는 액면 분할 등으로 주식 가격에 변동이 있을 경우 가격 변동 이전에 거래된 가격을 현재 주식 가격에 맞춰 수정하여 표시한 가격이다.
국내 주식에 대한 액면 분할 처리가 제대로 되지 않았다고 하니 종가(Close)만 사용한다.
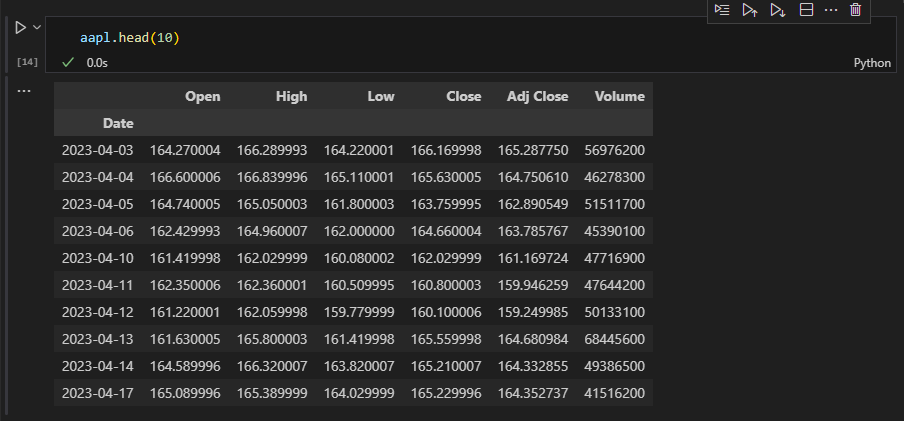
마이크로소프트의 주가 데이터도 정상적으로 출력된다.
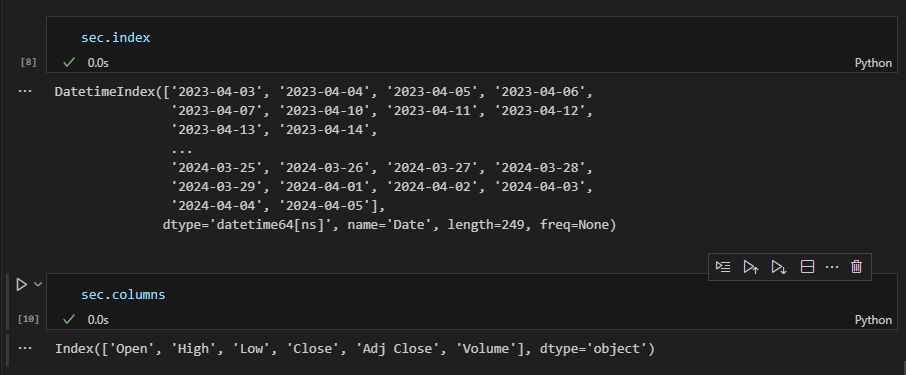
삼성전자 데이터프레임은 인덱스가 datatime형으로 되어 있으며 249개로 이루어져 있다.
columns 속성으로 가지고 있는 칼럼 정보를 확인한다.
일간 변동률로 주가 비교하기

파이썬의 shift() 함수를 사용하여 일간 변동률을 구한다.
sec_dpc = (sec['Close'] / sec['Close'].shift(1) - 1) * 100
sec_dpc.iloc[0] = 0
sec_dpc.head()
plt.hist(sec_dpc, bins=10)
plt.grid(True)
plt.show()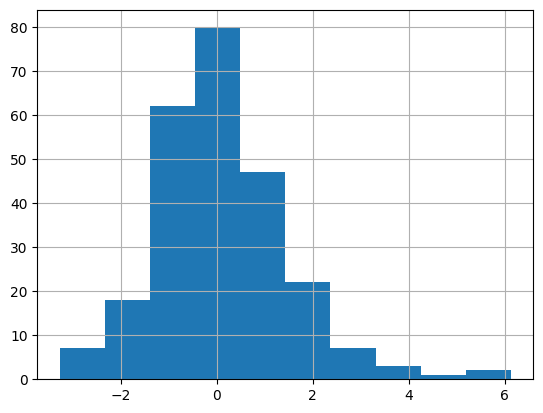
일간 변동률을 구한 후 히스토그램을 출력한다.
이전 데이터가 없기 때문에 첫 번째 변동률이 NaN인데, 항후 계산을 위해 0을 입력한다.
출력된 결과를 보면 0을 기준으로 우측의 데이터가 많다.
가운데가 뾰족할수록 주가의 움직임이 작은 범위 안에서 발생한다는 것을 의미한다.
sec_dpc_cs = sec_dpc.cumsum()
sec_dpc_cs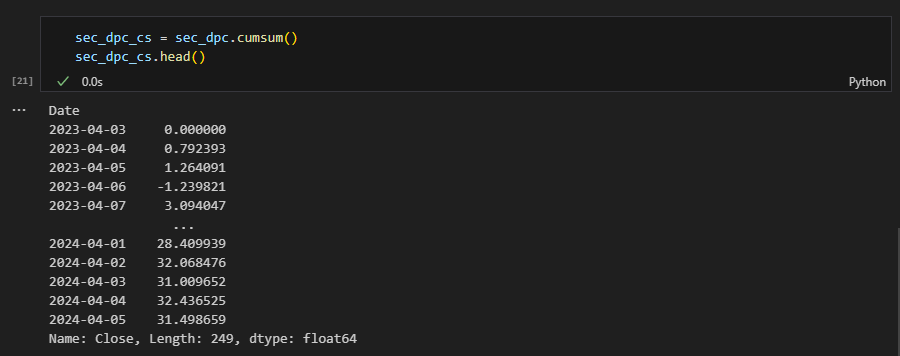
전체적인 변동률을 비교하기 위해선 누적합(Cumulative Sum)을 계산해야 한다.
시리즈에서 제공하는 cumsum() 함수를 이용하여 구할 수 있다.
근데 수익률이 31%?
sec_dpc = (sec['Close'] / sec['Close'].shift(1) - 1) * 100
sec_dpc.iloc[0] = 0
sec_dpc_cs = sec_dpc.cumsum()
aapl_dpc = (aapl['Close'] / aapl['Close'].shift(1) - 1) * 100
aapl_dpc.iloc[0] = 0
aapl_dpc_cs = aapl_dpc.cumsum()
plt.plot(sec.index, sec_dpc_cs, 'b', label='Samsung Electronics')
plt.plot(aapl.index, aapl_dpc_cs, 'r--', label='Apple')
plt.ylabel('Change %')
plt.grid(True)
plt.legend(loc='best')
plt.show()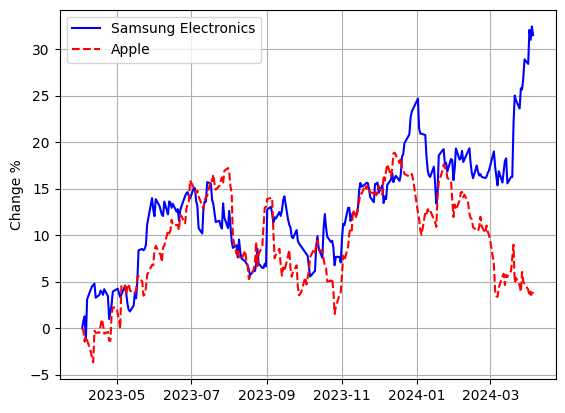
2023년 4월 1일에 삼성전자에 투자를 했으면 30% 이상의 수익을 얻고, 애플에 투자를 했으면 4%의 수익을 얻었을 것이다.
라고 할 때 샀어야했다.
최대 손실 낙폭
MDD(Maximum Drawdown)은 특정 기간에 발생한 최고점에서 최저점까지의 가장 큰 손실을 의미한다.
퀀트 투자에서는 수익률보다 MDD를 낮추는 것이 더 중요하다고 말할 만큼 중요한 지표로서, 특정 기간 동안 최대한 얼마의 손실이 날 수 있는지를 나타낸다.
2004년부터 현재까지의 KOSPI 지수 데이터를 통해 KOSPI의 MDD를 구해보자.
그러기 위해선 rolling() 함수를 알아야 한다.
Serise.rolling(윈도우 크기 [, min_periods=1]) [.집계 함수()]
rolling() 함수는 시리즈에서 윈도우 크기에 해당하는 개수만큼 데이터를 추출하여 집계 함수에 해당하는 연산을 실시한다.
집계 함수로는 max(), mean(), min()을 사용할 수 있으며, min_periods를 지정하면 데이터 개수가 윈도우 크기에 못미치더라도 min_periods로 지정한 개수만 만족하면 연산을 수행한다.
kospi = pdr.get_data_yahoo('^KS11', '2004-01-04')
window = 252
peak = kospi['Adj Close'].rolling(window, min_periods=1).max()
drawdown = kospi['Adj Close']/peak - 1.0
max_dd = drawdown.rolling(window, min_periods=1).min()
plt.figure(figsize=(9, 7))
plt.subplot(211)
kospi['Close'].plot(label='KOSPI', title='KOSPI MDD', grid='True', legend=True)
plt.subplot(212)
drawdown.plot(c='blue', label='KOSPI DD', grid=True, legend=True)
max_dd.plot(c='red', label='KOSPI MDD', grid=True, legend=True)
plt.show()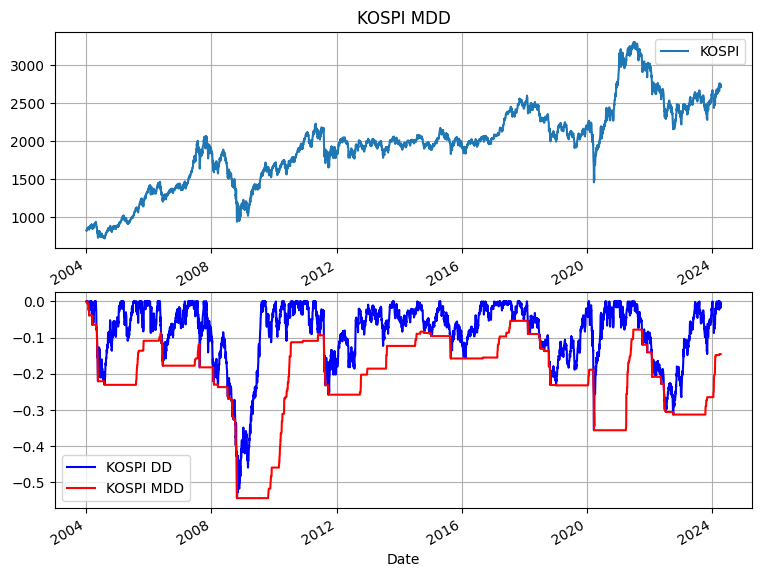
- KOSPI 지수 데이터를 다운로드한다. KOSPI의 심볼은 ^KS11이다.
- 산정 기간에 해당하는 window값은 1년 동안의 개장일을 252일로 어림잡아 설명했다.
- KOSPI 종가 칼럼에서 1년 기간 단위로 최고치 peak를 구한다.
- drawdown은 최고치(peak) 대비 현재 KOSPI 종가가 얼마나 하락했는지를 구한다.
- drwadown에서 1년 기간 단위로 최저치 max_dd를 구한다. 마이너스 값이기 때문에 쵀ㅣ저치가 바로 최대 손실 낙폭이 된다.
서브프라임 금융 위기였던 2008년 10월 24일에 KOSPI 지수가 10.57% 하락하면서 MDD가 -54.5%를 기록했다.
정확한 MDD는 min() 함수로 구할 수 있다.
회귀 분석과 상관관계
회귀 분석은 데이터의 상관관계를 분석하는 데 쓰이는 통계 분석 방법이다.
회귀 모형을 설정한 후 실제로 관측된 표본을 대상으로 회귀 모형의 계수를 추정한다.
독립변수라고 불리는 하나 이상의 변수와 종속변수라 불리는 하나의 변수 간의 관계를 나타내는 회귀식이 도출되면, 임의의 독립변수에 대하여 종속변수값을 추측할 수 있는데, 이를 예측이라 한다.
다우존스 지수와 KOSPI 지수화 비교
dow = pdr.get_data_yahoo('^DJI', '2000-01-04')
kospi = pdr.get_data_yahoo('^KS11', '2000-01-04')
d = (dow.Close / dow.Close.loc['2000-01-04']) * 100
k = (kospi.Close / kospi.Close.loc['2000-01-04']) * 100
plt.figure(figsize=(9, 5))
plt.plot(d.index, d, 'r--', label='Dow Jones Industrial Average')
plt.plot(k.index, k, 'b', label='KOSPI Average')
plt.grid(True)
plt.legend(loc='best')
plt.show()
- 다우존스와 코스피의 데이터를 다운로드 한다.
- 현재 종가를 특정 시점의 종가로 나누어 변동률을 구하여 출력한다.
2.1 각 지수를 2000년 1월 4일 지수로 나눈 뒤 100을 곱하여 변동률을 구한다.
이를 지수화라고 하며, 누적합을 구하는 것보다 수월하게 처리할 수 있다.
지난 20년간 상승률이 서로 비슷함을 확인할 수 있다.
import pandas as pd
df = pd.DataFrame({'DOW': dow['Close'], 'kospi': kospi['Close']})
df = df.fillna(method='bfill')
df = df.fillna(method='ffill')
df다우존스 지수와 코스피의 관계를 산점도로 표현하자.
산점도는 독립변수 x와 y의 상관관계를 확인할 때 쓰는 그래프다.
산점도를 그리려면 x, y의 사이즈가 동일해야 하기 때문에 fillna() 함수를 사용해 NaN을 채워준다.
bfill은 NaN 뒤에 있는 값으로 덮어씌우고, ffill은 반대의 역할을 수행한다.
plt.figure(figsize=(7, 7))
plt.scatter(df['DOW'], df['KOSPI'], marker='.')
plt.xlabel('Dow Jonse Inustrial Average')
plt.ylabel('KOSPI Average')
plt.show()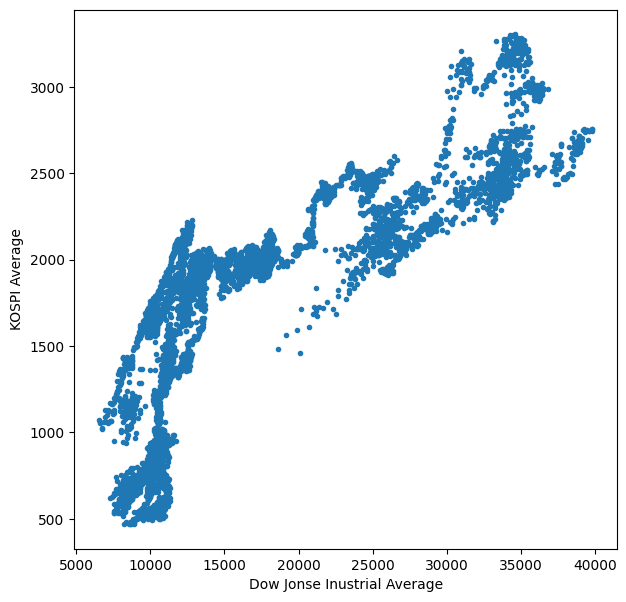
점의 분포가 직선에 가까울수록 상관관계가 강하다고 볼 수 있는데, 다우지수와 코스피는 어느 정도 영향이 있지만 강하다고 보기 어렵다.