웹 스크래핑을 사용한 데이터 분석
웹에서 일별 시세 구하기
네이버 금융에 접속하면 한국거래소에 상장된 종목의 일별 시세를 확인할 수 있다. 삼성전자를 검색해본다.
주소 끝에 있는 숫자 005930은 삼성전자의 종목코드다. 따라서 다른 종목의 가격을 확인하려면 종목코드를 바꾼다.
삼성전자의 일별 시세 데이터를 전부 가져오자. 삼성전자의 주가가 페이지당 10개씩 표시되고 있고, 첫 페이지의 주가는 최신 날짜의 주가다.
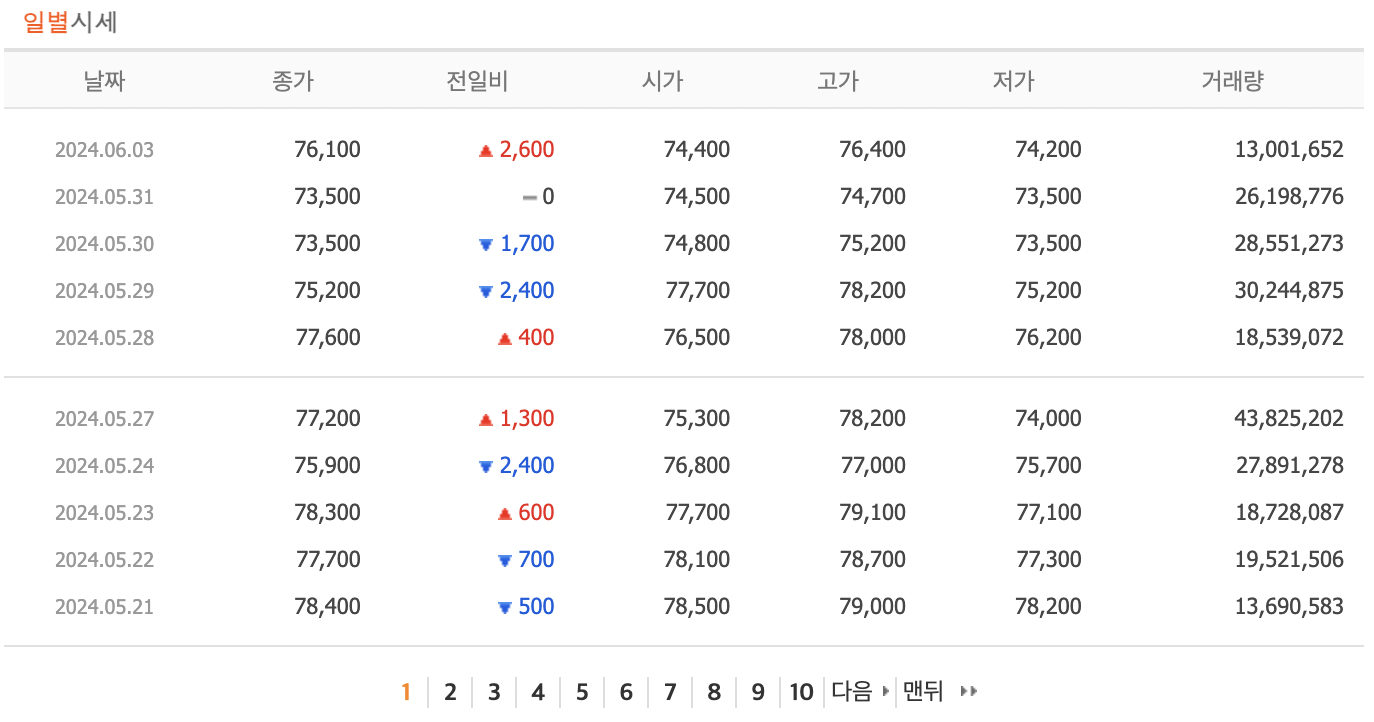
[맨뒤]를 클릭하면 가장 오래된 날짜의 종가가 표시된다. 현재 [맨뒤]를 클릭하면 701페이지로 이동한다. 페이지 번호는 상장일이 오래될수록 크다.
다음 그림을 보면 삼성전자의 주가가 66500원으로 시작하여 67500으로 마감했다. 개발자 도구를 사용하여 [맨뒤] 버튼의 링크를 확인하면 다음 주소를 얻을 수 있다.
https://finance.naver.com/item/sise_day.naver?code=005930&page=701
URL 주소 뒤에 종목코드와 페이지 숫자를 파라미터로 넘겨주면, 해당 종목 일별 시세에서 지정한 페이지로 접속한다.
뷰티풀 수프로 일별 시세 읽어오기
접근 권한이 있는 저작권 자료를 크롤링하여 분석 목적으로 사용하는 것은 괜찮지만, 원저작자의 허가를 받지 않고 자신의 웹에 게시하거나 다른 사람이 다운로드 하도록 공유하면 안 된다. 또한 잦은 크롤링으로 상대방 시스템 성능에 지장을 주는 경우도 문제가 될 수 있으니 합법적인 범위가 어디까지인지 반드시 확인해야 한다.
pip install beautifulsoup4로 설치해준다.
뷰티풀 수프는 HTML 페이지를 분석할 때 네 가지 인기 파서 라이브러리를 골라서 쓸 수 있다. 파서별로 장단점이 있으므로 페이지 특성을 고려하여 지정하면 된다.
| 파서 | 문자열 | 장점 | 단점 |
|---|---|---|---|
| Python's html.parser | 'html.parser' | 기본 옵션으로 설치되어 있다. 속도가 적절하고, 유연한 파싱이 가능하다. | lxml 파서보다 느리고, html5lib 파서만큼 유연하지 못하다. |
| lxml's HTML parser | 'lxml' | 속도가 매우 빠르고, 유연한 파싱이 가능하다. | |
| lxml's XML parser | 'lxml-xml', 'xml' | 속도가 매우 빠르고, 유연한 파싱이 가능하다. | XML 파일에서만 사용할 수 있다. |
| html5lib | 'html5lib' | 웹 브라우저와 동일한 방식으로 파싱한다. 극도로 유연하여 복잡한 구조의 HTML 문서를 파싱하는 데 사용한다. | 느리다. |
find_all() 함수와 find() 함수 비교
뷰티풀 수프에서 가장 중요한 함수는 원하는 태그를 찾아주는 find_all() 함수와 find() 함수일 것이다.
find_all(['검색할 태그'][, class_='클래스 속성값'][, id='아이디 속성값'][, limit=찾을 개수])
find(['검색할 태그'][, class_='클래스 속성값'][, id='아이디 속성값'][, limit=찾을 개수])
find_all() 함수는 문서 전체를 대상으로 조건에 맞는 모든 태그를 찾는다. 문서 내에서 하나뿐인 태그를 찾을 때 사용하면 시간을 낭비할 수 있다. 물론 limit=1 인수를 줘서 태그 하나만 찾게 할 수도 있지만, find() 함수를 사용하면 더 간편하다. 아무것도 못 찾으면 find_all()은 빈 리스트를, find()는 None를 반환한다.
맨 뒤 페이지 숫자 구하기
from bs4 import BeautifulSoup
import requests
url = 'https://finance.naver.com/item/sise_day.naver?code=005930&page=1'
# 헤더를 꼭 지정해준다.
req = requests.get(url, headers={'User-agent' : 'Mozilla/5.0'})
html = BeautifulSoup(req.text, 'html.parser')
pgrr = html.find('td', class_='pgRR')
print(pgrr.a['href'])
s = str(pgrr.a['href']).split('=')
last_page = s[-1]
# /item/sise_day.naver?code=005930&page=701- 뷰티풀 수프 생성자의 첫 번째 인수로 HTML/XML 페이지의 파일 경로나 URL을 넘겨주고, 두 번째 인수로 파싱할 방식을 넘겨준다
- find 함수를 통해 class 속성이 'prGG'인 td 태그를 찾으면, 결과값은 'bs4.element.Tag' 타입으로 변수에 할당된다. 클래스를 class_로 표시한 이유는 파이썬에 이미 class라는 지시어가 있기 때문에, 인터프리터가 구분할 수 있도록 하기 위함이다.
- pgrr 하부에 있는 a 태그의 href 속성을 추출한다.
pgrr 전체 텍스트를 확인하려면 getText 속성을 사용한다. prettify() 함수를 호출하면 getText 속성값을 계층적으로 보기 좋게 출력할 수 있다.
만일 태그를 제외한 텍스트 부분만 구할 때는 text 속성을 이용하면 된다.
prgg.prettify()
prgg.text전체 페이지 읽어오기
삼성전자의 일별 시세를 처음부터 마지막 페이지까지 반복하여 데이터프레임에 저장한다.
import pandas as pd
import matplotlib.pyplot as plt
import requests, re
from datetime import datetime
from matplotlib import dates as mdates
from bs4 import BeautifulSoup as bs
def extract_numbers(text):
return re.sub(r'\D', '', text)
sise_url = 'https://finance.naver.com/item/sise_day.naver?code=005930'
headers={'User-agent' : 'Mozilla/5.0'}
df = pd.DataFrame()
for page in range(1, int(last_page) + 1):
page_url = f'{sise_url}&page={page}'
res = requests.get(page_url, headers=headers)
html = bs(req.text, 'html.parser')
html_table = html.select("table")
data = pd.read_html(str(html_table))[0]
data = data.dropna()
data['전일비'] = data['전일비'].apply(extract_numbers).astype(float)
df = pd.concat([df, data], ignore_index=True)
print(df)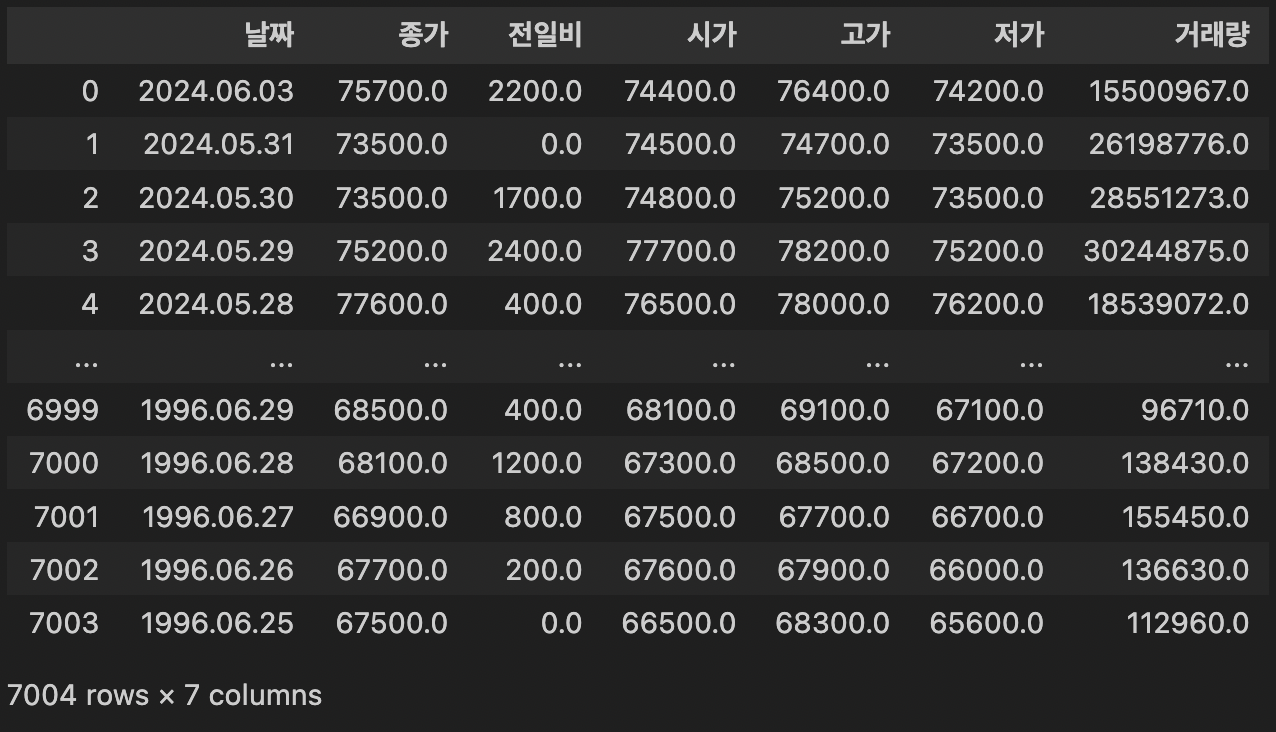
캔들 차트 그리기
OHLC는 Open-Hign-Low-Close를 나타내며 시가-고가-저가-종가를 의미한다. 캔들 차트는 OHLC에 해당하는 네 가지 가격을 이용하여 일정 기간의 가격 변동을 표시한다.
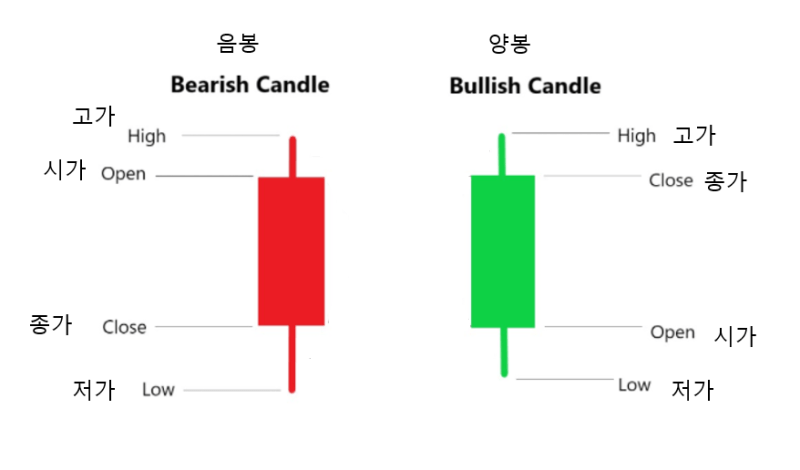
캔들 차트는 하루 동안의 가격을 표시하는데 시가보다 종가가 높으면 붉은 양봉을 표시하고, 고가와 저가를 실선으로 연결한다. 반대로 시가보다 종가가 낮으면 푸른 음봉으료 표시한다. 미국에서는 양봉을 녹색으로 표시하기도 한다.
삼성전자 종가 차트
전체 데이터는 너무 많으니 삼성전자의 최근 30개 종가 데이터를 이용하여 차트로 표시한다.
df_30 = df.iloc[0:30]
df_30 = df_30.sort_values(by='날짜')
import matplotlib as mpl
mpl.rcParams['figure.figsize'] = [10, 5]
plt.title('Samsung Electronics')
plt.xticks(rotation=45)
plt.plot(df_30['날짜'], df_30['종가'], 'co-')
plt.grid(color='grey', linestyle='--')
plt.show()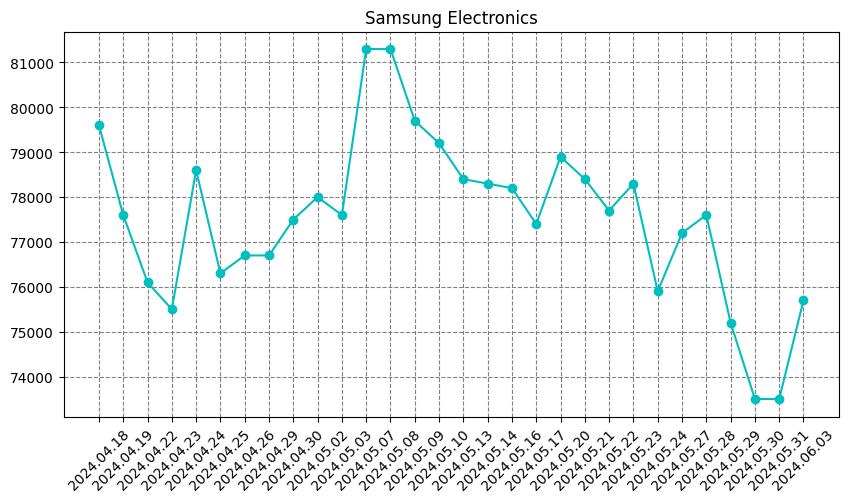
삼성전자 캔들 차트
기존 캔들 차트 기능은 matplotlib.finance 모듈에 포함되어 있었으나 맷플로립에서 제거되면서 mpl_finance 패키지로 이동
하지만 엠피엘 파이낸스 패키지는 폐기되었고 mplfinance 패키지로 새롭게 바뀌었다.
패키지명 중간에 -(하이픈)이나 _(언더스코어)가 있으면 예쩐 패키지이고, 중간에 아무 문자도 없는 것이 새로운 패키지다.
pip install --upgrade mlpfinance 명령으로 설치
엠피엘파이낸스의 가장 큰 장점은 OHLC 데이터 칼럼과 날짜시간 인덱스를 포함한 데이터프레임만 있으면 기존에 사용자들이 수동으로 처리했던 데이터 변환 작업을 모두 자동화 해준다.
mpf.plot(OHLC 데이터프레임, [, title=차트제목][, type=차트형태] [, mav=평균이동선][, volume=거래량 표시여부] [, ylabel=y축 레이블])
해당 패키지를 사용하여 삼성전자의 캔들 차트를 그린다.
import mplfinance as mpf
df_30 = df.iloc[0:30]
df_30 = df_30.rename(columns={'날짜':'Date', '시가':'Open', '고가':'High', '저가':'Low',
'종가':'Close', '거래량':'Volume'})
df_30 = df_30.sort_values(by='Date')
df_30.index = pd.to_datetime(df_30.Date)
df_30 = df_30[['Open', 'High', 'Low', 'Close', 'Volume']]
kwargs = dict(title='Samsung Electronics', type='candle', mav=(2, 4, 6), volume=True, ylabel='ohlc candle')
mc = mpf.make_marketcolors(up='r', down='b', inherit=True)
s = mpf.make_mpf_style(marketcolors=mc)
mpf.plot(df_30, **kwargs, style=s)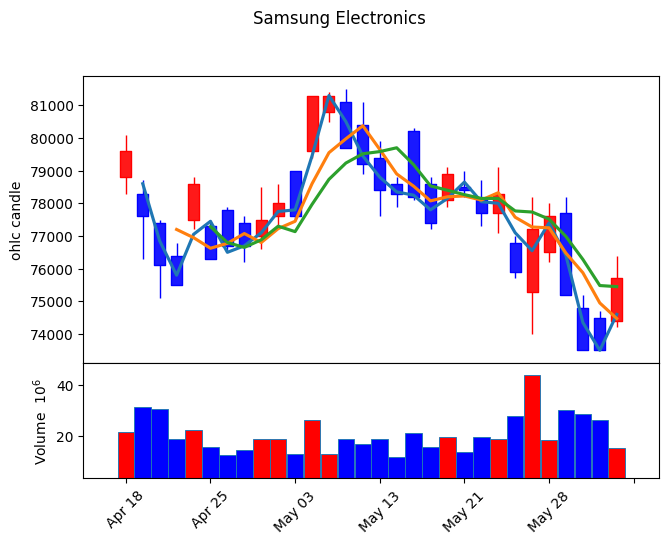
- kwargs에 mpf.plot() 함수를 호출할 때 사용할 인자를 담는다.
- 마켓 색상은 빨간색과 파란색, 관련 색상은 이를 따르도록 하여 스타일 객체를 생성한다.
- 인수와 스타일 객체를 받아 차트를 출력한다.