7.1 함수를 활용한 근사
그리드 월드의 경우 state가 16개밖에 되지 않았지만,
대부분의 경우 고유한 state가 연속적인 값들을 가질 수 있으므로
물리적으로 테이블을 만들어 업데이트를 하기는 쉽지 않아진다.
때문에 정확한 실제 가치 함수를 구하는 것이 아니라
데이터들을 잘 설명할 수 있는 근사함수를 구하게 된다.
일반적으로 최소제곱법(least squares)을 통해 데이터들의
평균제곱오차(MSE,Mean Squared Error)를 최소화하는
ax+b의 직선을 구하게 되는데,
단순한 직선으로는 설명이 어려울 수 있으니
a_0 + a_1x + a_2x^2+...=a_nx^n의 다항 함수를 만들어서
여러 데이터를 n개의 파라미터들을 이용해 잘 설명하는 함수를 그릴 수 있다.
오버피팅과 언더피팅
이 과정에서 과하게 고차원이 되어 현재데이터들을 잘 설명할 수 있으나
새로운 데이터를 설명하기 어렵다면 오버피팅, 차원이 낮아서 현재 데이터를 설명하기에도 적절하지 않은 경우에 언더피팅이 된다고 한다.
함수의 장점 - 일반화
MDP에 존재하는 모든 상태들을 다 저장하려면 엄청나게 많은 용량이 들지만,
함수는 여러 파라미터만 있으면, 데이터들을 잘 일반화하여
처음보는 데이터가 들어와도 작은 에러를 리턴하도록 할 수 있다.
결국 어떤 함수를 사용하고, 파라미터는 어떻게 조정할 것인가 중요한 문제가 되는데
이를 위해 인공 신경망을 사용한다.
7.2 인공 신경망의 도입
딥러닝 = 딥 뉴럴네트워크
신경망
인공 신경망의 본질은 아주 유연한 함수로, 유연성이 뛰어나 어떤 복잡한 관계도
피팅이 가능하다고 할 수 있다. 1차함수는 ax+b의 2개의 파라미터를 가지지만
신경망은 최소 100만개의 파라미터를 가지고 있다.
신경망은 input레이어와 여러 개의 히든 레이어, output 레이어로 구성되며
히든 레이어는 여러 개의 노드의 선형 결합 연결 및 비선형 함수로 이루어진다.
여러 노드들이 선형 결합하면 몇 개의 파라미터로 이루어진 새로운 feature를
만들게되며, 레이어가 깊어질 수록 단순한 피쳐에서 복잡하고 추상적인 피쳐를
설명 할 수 있게 된다.
신경망의 학습 - 그라디언트 디센트
신경망에는 굉장히 많은 파라미터들이 있고, 기본적으로 입력 x에 대해
출력 = wx+b 로 이루어져 있다.
처음에 이 값들을 초기화하면 당연히 실제 데이터를 설명하기는 어려울 것이고
실제값과 예측값의 차이를 손실 함수(loss function)로 정의하면, 손실함수의 값이 줄어들도록 파라미터 w를 감소시켜야 할 것이다.
w와 w에 관한 손실함수 L(w)가 있다면, w가 L(w)에 미치는 영향력을
알아야 하는데 이 과정이 미분에 해당한다. 앞서 말했듯 w는 엄청 많고
각 w_1에서 w_n까지 손실함수에 미치는 영향을 계산하기 위해서는
w들의 편미분 값을 알아야 하는데, 이에 대한 벡터를 그라디언트라고 하며
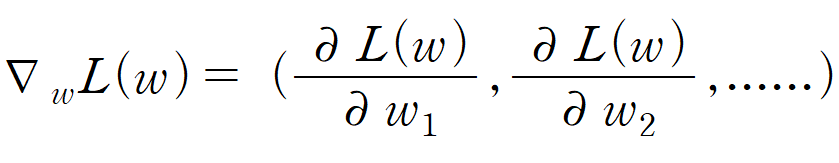
위와 같은 수식으로 나타낸다.
그라디언트는 방향을 나타내는 벡터로, 이 방향으로 α만큼 이동하게 되면 L(w)을
조금씩 줄어들게 할 수 있는데 이 때 α는 learning rate로, 이 과정을 반복해
적절한 함수를 만들어 데이터를 예측할 수 있게 한다.
파이토치를 이용한 신경망의 학습 구현
뉴럴넷은 파라미터가 100만개 이상이므로, 매우 복잡한 함수를 구성한다.
이 과정을 전부 계산하는 것은 굉장히 어렵기 때문에, 텐서플로우나 파이토치
같은 자동 미분 라이브러리를 사용한다.
이들은 역전파 알고리즘을 통해 복잡한 함수의 그라디언트를 효율적이고
빠르게 구할 수 있다.
