MDP를 모르는 상태에서, 상태의 집합 S와 액션의 집합 A가 너무나도 커서
밸류들을 테이블에 담지 못하는 상황에서는 뉴럴넷을 사용할 수 있다.
강화학습과 뉴럴넷을 접목하는 방식은 크게 두 가지로
상태 가치함수 vπ(s)나 액션 가치함수 qπ(s,a)를 뉴럴넷으로 표현하거나
정책함수 π(a|s)를 뉴럴넷으로 표현하는 방식이 있다.
가치기반 에이전트는 가치 함수에 근거하여 액션을 선택한다.
일반적으로 모델 프리한 상황에서는 액션 가치함수 q(s, a)를 필요로 하고
정책함수가 따로 없어도, 정책 함수 역할을 겸할 수 있다.
정책기반 에이전트는 정책 함수 π(a|s)를 통해 액션을 선택한다.
π만 있으면, 에이전트는 MDP안에서 경험을 쌓으면서 π를 점점 강화할 수 있다.
액터-크리틱은 가치함수와 정책함수를 모두 사용한다.
액터는 행동을 하는 정책 π를 뜻하고,
크리틱은 비평하는 가치함수 v(s) 또는 q(s,a)를 뜻한다.
8.1 밸류 네트워크의 학습
정책 π가 고정되어 있을 때 뉴럴넷을 사용해 가치함수 vθ(s)를 정의하는 경우
가치함수 vθ(s)는 밸류 네트워크라고 하며, θ는 파라미터에 해당한다.
초기에 θ는 0으로 초기화되어 있지만, 학습을 통해서 모든 상태 S에 대하여
올바른 밸류를 출력하도록 해야한다.
이를 위해서는 당연히 손실 함수가 필요하다.
만약 상태(s)에 따른 정확한 밸류의 값을 v_ture(s)라고 가정한다면
손실 함수는 다음 수식으로 나타 낼 수 있다.
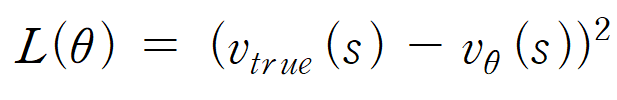
가정에 의하면 모든 S를 탐색하기는 어려우므로,
정책 π에 의해 방문한 모든 상태에 대한 기댓값을 계산한다면
많은 데이터를 통해서 학습이 가능해진다.
파라미터를 업데이트 하기 위해서는 손실함수의 θ에 대한 그라디언트가 필요하고,

계산을 통해 위 수식을 얻을 수 있지만,
실제로 v_true(s)가 주어지는 경우는 없기 때문에
MC와 TD를 통해 대신할 값을 찾을 수 있게 된다.
첫번째 대안:몬테카를로 리턴
우리가 결과적으로 구하려고 하는 상태가치함수 v_ture(s)는
뉴럴 네트워크에서도 결국 리턴의 기댓값에 해당한다.
때문에 정답자리에 v_ture(s) 대신 관측된 G_t를 사용한다면
뉴럴넷의 아웃풋이 실제 밸류에 수렴할 것을 예상할 수 있다.
따라서 특정 파라미터 θ는 다음 식을 통해 업데이트가 가능하다.

이 경우 몬테카를로 방법이기 때문에, MC의 장단점을 그대로 가지고 있다.
pseudo-code
1. θ(Q네트워크의 파라미터)를 초기화해준다.
2. s의 상태를 s_0로 초기화해준다
3. while ε-greedy를 통해 a를 선택해 r과 s'을 확인 후
maxQ_θ(s', a')를 통해 θ를 업데이트해준다.
4. for 에피소드가 끝나면 2번으로 돌아가 반복
5. θ가 수렴하거나, task가 잘 학습될때까지 반복두번째 대안 : TD타깃
이번에는 TD의 스텝 진행 후 추측값을 통해 업데이트를 하는 방식을 사용한다.
마찬가지로 vtrue(s)를 알 수 없기 때문에 TD타겟에 해당하는
r_t+1 + γvθ(s_t+1)을 정답으로 사용한다.
이로부터 파라미터 업데이트 식은

위와 같이 유도할 수 있고, 정답에 해당하는 값은 상수취급해 변화하지 않도록 해준다.
-> 텐서에 .detach를 사용하면 상수 취급해줌
8.2 딥 Q러닝
가치 기반 에이전트는 π가 없고 대신 q(s,a)를 통해 모든 상태에서 가치가 높은 액션을 선택하는 정책을 따른다. 딥 Q러닝은 뉴럴넷을 이용해 q(s,a)를 표현하므로
상태가 많은 거대한 MDP에서도 잘 동작할 수 있다.
Q러닝은 벨만 최적방정식을 통해 Q*(s,a)를 학습했으니
딥 Q러닝도 마찬가지로 정답을 [r+γmax_a' Q(s',a')]이라 보고
손실 함수와 파라미터 업데이트를 위한 그라디언트를 찾아 줄 수 있다.
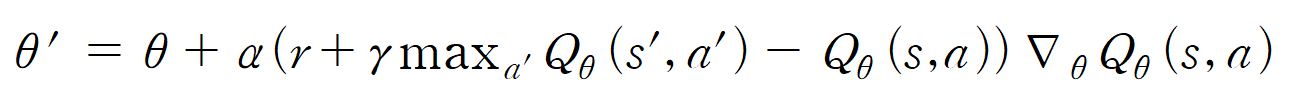
마찬가지로 정답으로 가정한 부분은 상수라고 생각한뒤 계속 업데이트 한다면
결과적으로 최적액션함수 Q*(s,a)를 찾을 수 있을 것이다.
pseudo-code
1. θ(Q네트워크의 파라미터)를 초기화해준다.
2. s의 상태를 s_0로 초기화해준다
3. while ε-greedy를 통해 a를 선택해 r과 s'을 확인 후
maxQ_θ(s', a')를 통해 뉴럴 넷을 통해 θ를 업데이트해준다.
4. for 에피소드가 끝나면 2번으로 돌아가 반복
5. θ가 수렴하거나, task가 잘 학습될때까지 반복익스피리언스 리플레이와 타겟 네트워크
딥마인드에 사용된 딥 Q러닝이 바로 DQN으로 뉴럴넷을 통해 Q함수를 강화하는 것이다.
이 과정에서 사용된 방법이 익스피리언스 리플레이와 타겟 네트워크이다.
익스피리언스 리플레이는 에피소드마다 경험한 transition을 데이터화하여
버퍼에 저장해둔뒤 이들 중 몇 개를 랜덤하게 뽑아서 학습하는 방식이다.
이 과정을 통해 데이터들간 상관성이 높아 발생하는 문제를 해결할 수 있고
off-policy 알고리즘의 장점을 가질 수 있따.
타겟 네트워크는 별도의 타겟 네트워크를 두는 방법으로
손실함수가 정답과 예측사이의 차이인데, 정답이 θ에 의존하므로 변수에 해당하므로
그냥 학습시키게 되면 정답지의 변화로 학습의 안정성이 떨어지게 된다.
때문에 똑같이 생긴 정답 네트워크를 따로 준비한뒤, 일정 주기마다만
정답 네트워크를 최신 파라미터로 교체해 주는 방식으로 학습을 안정화시킨다.
