경일게임아카데미 멀티 디바이스 메타버스 플랫폼 개발자 양성과정 20220607 2022/04/04~2022/12/13
수업 일기 - 경일게임아카데미 멀티디바이스 메타버스 플랫폼 개발자 양성과정
경일 메타버스 20220607 10주차 1일 수업내용. C++프로그래밍 추가, 템플릿, 자료 구조, STL
- 발표 자료 공유 사이트 Slideshare.net
정리
C++ 프로그래밍
- 템플릿 : 일반화 프로그래밍을 지원하는 기능.
- 일반화 프로그래밍 : 타입에 관계없이 알고리즘을 기술하는 것
- 템플릿 특수화는 컴파일 타임에 일어난다.
- 템플릿은 헤더파일에 모든 내용을 적는다.
자료구조 및 알고리즘
- STL : 표준 템플릿 라이브러리.
- 컨테이너 : 자료구조 구현체
- 반복자 : 컨테이너의 요소에 접근할 수 있는 포인터
- 알고리즘 : 반복자를 기반으로 수행되는 절차
- 리스트 : 순서가 있는 자료구조
- 선형 리스트 / 단일 연결 리스트, 이중 연결 리스트, 원형 연결 리스트
- 선형 리스트
- 임의 접근이 가능하다.
- 읽기 : O(1) / 삽입, 삭제 : 맨 끝이면 O(1), 처음이나 중간이면 O(N) / 검색 : O(N), 정렬되어 있을 시 이진 검색을 사용해서 O(logN)
C++프로그래밍
기본 인자 전달
-
함수를 선언할 때 기본 인자(Default Argument)를 전달할 수 있다.
-
기본 인자는 가장 오른쪽 인자부터 전달할 수 있다.
-
기본 인자 : https://en.cppreference.com/w/cpp/language/default_arguments
void Foo(int a, int b = 10);
Foo(10, 20); // a에는 10, b에는 20이 전달된다.
Foo(10); // a에는 10, b에는 기본 인자인 10이 전달된다.
void Foo(int a = 10, float b); // 컴파일 오류!일반화 프로그래밍(Generic Programming)
-
일반화 프로그래밍은 타입에 관계없이 알고리즘을 기술하는 프로그래밍 패러다임이다.
-
여러 타입의 데이터를 하나의 함수 / 클래스로 다룰 수 있다는 것이다.
-
C++에서는 이를 템플릿(Template)이라는 기능으로 지원하고 있다. 다른 언어에서는 제네릭(Generic)으로 지원한다.
-
일반화 프로그래밍 : https://en.wikipedia.org/wiki/Generic_programming
템플릿(Template)
-
템플릿은 기본적으로 클래스 템플릿(Class Template)과 함수 템플릿(Function Template)으로 구분된다.
-
C++14(모던 C++)부터는 별칭 템플릿(Alias Template), 변수 템플릿(Variable Template), 컨셉(Concept) 등을 만들 수 있다.
-
클래스 템플릿 : https://en.cppreference.com/w/cpp/language/class_template
-
함수 템플릿 : https://en.cppreference.com/w/cpp/language/function_template
-
별칭 템플릿 : https://en.cppreference.com/w/cpp/language/type_alias
-
변수 템플릿 : https://en.cppreference.com/w/cpp/language/variable_template
// 문법은 아래와 같이 구성된다.
// template <parameter-list> declaration
// 클래스 템플릿을 정의했다.
template <typename T>
struct A { T Data; };
// 함수 템플릿을 정의했다.
template <typename T>
void Swap(T& lhs, T& rhs)
{
T temp = lhs;
lhs = rhs;
rhs = lhs;
}
// 템플릿을 사용하려면 매개변수 목록에 인자를 전달하면 된다.
// 이를 특정 타입(Specific Type)으로 대체한다고 하여
// 특수화(Specialization)라고 한다.
A<int> a; // a는 int 타입의 Data를 가진다.
A<double> b; // b는 double 타입의 Data를 가진다.
int a = 10, b = 20;
Swap<int, int>(a, b);
Swap(a, b); // 함수 템플릿은 <>를 생략할 수 있다.-
템플릿은 하나 이상의 템플릿 파라미터(Template Parameter)와 함께 매개변수화 된다.
-
템플릿 파라미터에는
-
비 타입 템플릿 파라미터(Non-type Template Parameter)
-
구체적인 타입을 지정하는 것이다.
-
정수형, 포인터, 레퍼런스 등이 지정될 수 있다.
-
변수와 같이 넣을 수 있다.
-
기본 인자 전달도 가능하다.
-
-
-
타입 템플릿 파라미터(Type Template Parameter)
-
타입을 받을 수 있다.
-
typename 대신 class를 사용할 수 있다.
-
마찬가지로 기본 인자 전달이 가능하다.
-
-
-
템플릿 템플릿 파라미터(Template Template Parameter)
- 템플릿을 전달한다.가 있다.
-
정리하자면 타입도 마치 인자처럼 전달할 수 있다는 것이다.
-
-
템플릿 파라미터 : https://en.cppreference.com/w/cpp/language/template_parameters
-
비 타입 템플릿 파라미터 : https://en.cppreference.com/w/cpp/language/template_parameters#Non-type_template_parameter
-
타입 템플릿 파라미터 : https://en.cppreference.com/w/cpp/language/template_parameters#Type_template_parameter
-
템플릿 템플릿 파라미터 : https://en.cppreference.com/w/cpp/language/template_parameters#Template_template_parameter
// 타입 파라미터는 타입을 받을 수 있다.
template <typename T> class A { };
template <class T> class B { }; // typename 대신 class를 사용할 수 있다.
template <typename T = int> class C { }; // 기본 인자 전달도 가능하다.
// C<> c; c는 C<int> 타입이다.
// 비 타입 파라미터는 구체적인 타입을 지정하는 것이다.
// 비 타입 파라미터에 넣을 수 있는 타입으로는
// 정수형, 포인터, 레퍼런스 등이 있다.
// 마찬가지로 기본 인자 전달이 가능하다.
template <size_t N = 10> struct Array { int Container[N]; };
// 템플릿 파라미터는 템플릿을 전달하는 것이다.
// 자주 사용하지는 않으나, 굳이 사용하는 이유는
// 제약을 걸기 위함이라 볼 수 있다.
template <typename T> class Container { };
template <template<typename> typename Container = Container<int>> class Temp { };특수화(Specialization)
- 특수화는 컴파일 타임에 일어나며, 컴파일러가 템플릿을 기반으로 특정 타입을 생성한다.
template <typename T, size_t N>
struct IdiotArray { T Container[N]; };
IdiotArray<int, 10> arr;
// 컴파일러는 컴파일 타임에 아래와 같은 코드를 생성한다.
// template <>
// struct IdiotArray { int Container[10]; };-
따라서 일반적으로 템플릿은 헤더 파일에 모든 내용을 적으며, 정의를 소스 파일에 나눠서 적으면 링크 오류가 발생한다.
-
주의 : 컴파일러는 헤더가 수정되면 헤더를 포함하는 모든 파일(헤더 파일, 소스 파일)을 재컴파일한다.
→ 빌드 시간이 길어진다. -
그럼에도 불구하고, 템플릿은 링크 오류를 피하기 위해 헤더 파일에 모든 내용을 적어야 한다.
// Temp.h
template <typename T>
class A
{
public:
void SetData(const T& data);
T GetData() const;
private:
T _data;
};
// Temp.cpp
// 이 파일 아래에 있는 템플릿은 인스턴스가 만들어지지 않는다.
template <typename T>
void A<T>::SetData(const T& data)
{
_data = data;
}
template <typename T>
T A<T>::GetData() const
{
return _data;
}
// Main.cpp
int main()
{
A<int> a;
// 아래와 같이 인스턴스가 만들어진다.
// 정의가 없음을 볼 수 있다.
// template <>
// class A
// {
// public:
// void SetData(const T& data);
// int GetData() const;
// private:
// int _data;
// };
a.SetData(10); // 링크 오류! 정의가 없음.
}-
사용자가 특정 템플릿 인자에 대해 코드를 커스터마이징 할 수도 있다.
-
명시적 특수화(Explicit Specialization) : 모든 템플릿 파라미터에 대해 특수화
-
부분 특수화(Partial Specialization) : 일부 템플릿 파라미터에 대해 특수화
-
컴파일러가 만들어낸 특수화는 암시적 특수화(Implicit Specialization)라고 한다.
-
명시적 특수화 : https://en.cppreference.com/w/cpp/language/template_specialization
-
부분 특수화 : https://en.cppreference.com/w/cpp/language/partial_specialization
template <typename T1, typename T2>
void Print(const T1& a, const T2& b)
{
std::cout << a << '\n';
std::cout << b << '\n';
}
// 명시적 특수화
template <>
void Print(const int& a, const double& b)
{
std::cout << "이것은 명시적으로 특수화 되었습니다.\n";
}
// 부분 특수화
template <typename T>
void Print(const T& a, const int& b)
{
std::cout << "이것은 부분적으로 특수화 되었습니다.\n";
}
double d = 1.0;
Print(d, d); // Print<double, double>; 암시적 특수화 버전 호출
int i = 1;
Print(i, d); // Print<int, double>; 명시적 특수화 버전 호출
Print(d, i); // Print<double, int>; 부분 특수화 버전 호출자료 구조(data structure)
-
자료
https://docs.google.com/document/d/1lAZizYg8AjfkM-UqPlmkseWIs8Fagvqpo307hQA3xl4/edit?usp=sharing -
데이터를 조직하는 방법
-
데이터 조작에 적합한 알고리즘(algorithm)을 선택
-
C++제공 - STL 컨테이너
재귀(recursion)
-
함수가 자기 자신을 호출하는 것
-
재귀의 구조
-
재귀를 중단시키는 기저 조건(base case)
-
기저 조건으로 수렴하게 되는 재귀 조건(recursive case)
-
재귀호출을 사용하는 이유
- 분할 정복법(divide & conquer) : 문제에 따라 전체를 한 번에 해결하기보다 같은 유형의 하위 작업으로 분할하여 작은 문제부터 해결하는 방법이 효율적일 수 있기 때문
재귀의 단점
-
함수 호출에 따른 오버헤드(overhead)가 있다.
- 오버헤드(overhead) : 어떤 처리를 하기 위해 들어가는 간접적인 처리 시간 · 메모리 등을 말한다.
-
재귀가 너무 깊어지면 그만큼 호출 스택의 공간을 더 많이 사용하게 되고, 끝내는 스택 오버플로(stack overflow)가 발생할 수 있다.
- 스택 오버플로(stack overflow) : 스택이 가용할 수 있는 공간을 벗어나는 것을 말한다.
자료구조(data structure)의 구현
-
선형 구조(Linear Structure) : 리스트, 스택, 큐 등.
-
비선형 구조(Non-linear Structure) : 그래프와 트리 등.
-
대부분의 자료구조는 네 가지 기본 방법을 사용하며 이를 연산이라고 한다.
-
읽기 : 자료구조 내 특정 위치를 찾아보는 것이다.
-
검색 : 자료구조 내 특정 값을 찾는 것이다.
-
삽입 : 자료구조에 새로운 값을 추가하는 것이다.
-
삭제 : 자료구조 내 특정 값을 삭제하는 것이다.
-
자료구조를 구현하는 방법
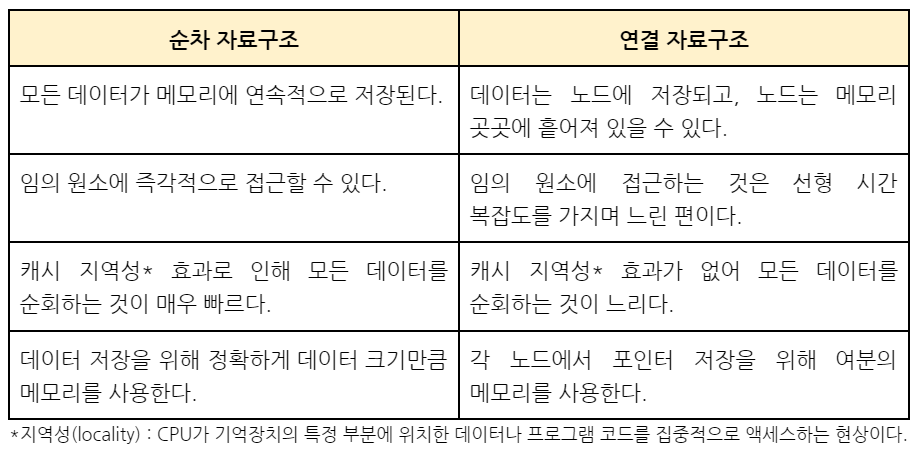
- 순차 자료구조(contiguous data structure) : 구현할 자료들을 논리적인 순서대로 메모리에 연속하여 저장하는 구현 방식, 배열을 이용
- 연결 자료구조(linked data structure) : 노드라는 여러 개의 메모리 청크에 데이터를 저장하며, 이를 연결하여 구현하는 방식, 포인터를 이용
알고리즘의 분석
-
알고리즘이란 문제를 해결하기 위한 절차를 말한다.
-
문제를 해결하는 방법에는 여러가지가 존재할 수 있으며, 우리는 이 중 최선을 선택해야 한다. 다시 말해 알고리즘을 분석하고 비교할 줄 알아야 한다.
-
알고리즘을 분석하는 것은 알고리즘의 자원(resource) (실행 시간, 메모리 사용량)의 사용량을 분석하는 것이라고 볼 수 있다.
-
자원을 적게 사용할 수록 효율적인 알고리즘이라고 할 수 있다.
시간 복잡도(time complexity)
-
알고리즘의 분석에 있어 가장 중요한 부분은 실행 시간
-
알고리즘의 실제 실행은 하드웨어 및 소프트웨어 환경에 따라 천차만별 → 단순 측정으로는 실행 시간을 분석할 수 없다.
-
하드웨어와 소프트웨어 환경을 배제한 객관적인 지표가 필요
-
시간 복잡도는 알고리즘을 수행하는 데 필요한 연산이 몇 번 실행되는지
를 숫자로 표기 -
연산의 개수 n의 값에 따라 시간 복잡도를 나타낸 것을 시간 복잡도 함수라고 하며 수식으로는 T(n)이라고 표기
-
Big-O 표기법
- **다항식의 시간 복잡도 함수에서 입력값이 커져감에 따라 각 항의 결과값에 관여하는 정도가 달라지게 된다.
- 상수 계수와 중요하지 않은 항목을 제거한 점근적 표기법**(asymptotic notation)을 사용
- Big-θ, Big-O, Big-Ω 등.
- Big-O 표기법은 점근적 상한선을 제공
- 오른쪽으로 갈 수록 상한선이 높아진다. 왼쪽에 위치한 시간 복잡도일수록 해당 알고리즘은 빠르다고 할 수 있다.
- O(1)<O(logn)<O(n)<O(nlogn)<O(n2)<O(n3)<O(2n)<O(n!)
- 주의 : 한 알고리즘이 다른 알고리즘보다 실제로 빠르다고 하더라도 같은 방식으로 표현이 될 수도 있다
공간 복잡도(space complexity)
-
알고리즘을 수행하는 데 필요한 자원 공간의 양
-
공간 복잡도 함수는 고정 공간 요구 + 가변 공간 요구로 나타낼 수 있으며 수식으로는 S(P)=c+Sp(n)으로 표기한다.
-
고정 공간 : 입력과 출력의 횟수나 크기와 관계 없는 공간
-
가변 공간 : 문제를 해결하기 위해 요구되는 추가 공간
시간 복잡도 vs 공간 복잡도
-
효율적인 알고리즘은 실행 시간이 적게 걸리며, 자원을 적게 소모하는 것이라고 할 수 있다.
-
시간과 공간은 반비례적인 경향이 있어 보통 알고리즘의 척도는 시간 복잡도를 위주로 판단한다.
STL(Standard Template Library)
-
C++에서는 자료구조와 알고리즘을 템플릿을 이용해 제공
-
표준 템플릿 라이브러리(Standard Template Library)라고 한다.
구성
-
임의 타입의 객체를 보관할 수 있는 컨테이너 라이브러리(Container Library)
-
컨테이너에 보관된 원소에 접근할 수 있는 반복자 라이브러리(Iterator Library)
-
반복자를 가지고 일련의 작업을 수행하는 알고리즘 라이브러리(Algorithm Library)
-
컨테이너(Container) : 자료구조의 구현체
-
반복자(Iterator) : 컨테이너의 요소에 접근할 수 있는 포인터. 나뉘게 된 이유는 구현 코드의 개수를 줄이기 위함
-
반복자 패턴(Iterator Pattern)
-
컨테이너의 개수를 N, 알고리즘의 개수를 M이라 한다면, 컨테이너 각각에 알고리즘을 구현할 때 필요한 구현 코드의 개수는 N * M이다.
-
이 사이에 반복자를 s추가함으로써 반복자를 통해 각 요소에 추상적으로 접근이 가능하게 돼 총 필요한 구현 코드의 개수를 N + M으로 줄일 수 있었다.
리스트(List)
-
순서를 갖고 있는 자료구조
-
순차 자료구조 : 선형 리스트
-
연결 자료구조 : 단일 연결 리스트, 원형 연결 리스트, 이중 연결 리스트
-
선형 리스트(linear list)
-
순서 리스트(ordered list).
-
STL 상에서는 std::array, std::vector로 구현되어 있다.
- std::array : https://en.cppreference.com/w/cpp/container/array
- std::vector : https://en.cppreference.com/w/cpp/container/vector
-
임의 접근이 가능하다.
-
읽기
- 선형 리스트는 임의 접근이 가능하기 때문에 O(1)의 시간이 걸린다.
- 선형 리스트는 임의 접근이 가능하기 때문에 O(1)의 시간이 걸린다.
-
검색
- 하나하나 원소를 비교해가야 하므로 O(n)의 시간이 걸린다. 정렬되어 있다면 이진 검색을 사용할 수 있으며 이 경우 O(logn)이다.
- 하나하나 원소를 비교해가야 하므로 O(n)의 시간이 걸린다. 정렬되어 있다면 이진 검색을 사용할 수 있으며 이 경우 O(logn)이다.
-
삽입
- 원소를 어디에 삽입하냐에 따라 시간이 달라진다. 맨 끝에 데이터를 추가할 경우 O(1)이지만, 처음이나 중간이라면 모든 데이터를 이동해야 하기에 O(n)이 걸린다.
- 원소를 어디에 삽입하냐에 따라 시간이 달라진다. 맨 끝에 데이터를 추가할 경우 O(1)이지만, 처음이나 중간이라면 모든 데이터를 이동해야 하기에 O(n)이 걸린다.
-
삭제
- 삽입과 마찬가지로 원소를 어디에서 삭제하냐에 따라 시간이 달라진다. 맨 끝의 데이터를 삭제할 경우 O(1)이지만, 처음이나 중간이라면 모든 데이터를 이동해야 하기에 O(n)이 걸린다.
-
실습
- 동적으로 저장 공간이 늘어나는 std::vector를 int형으로 구현
- 2022. 06. 07 동적으로 저장 공간이 늘어나는 std::vector를 int형으로 구현
기타
C++ 11에서 나온 새로운 for문
range-based for
collection에는 begin() / end() 명시
collection 전체를 순회할 때 사용
* C#의 for-each문
문법 :for (type identifier : collection) { }
for (size_t elem : vec2)
{
cout << elem << ' ';
}
// equal
for (auto iter = vec2.begin(); iter != vec2.end(); iter++)
{
cout << elem << ' ';
}