여기서는 처리율 제한 장치에 대한 이론보다는 Bucket4J 라이브러리를 활용한 실제 구현에 초점을 둘 것이다. 처리율 제한 장치에 대한 이론이나 알고리즘은 이전에 작성한 글을 참고하자.
고려 사항
토큰 버킷 알고리즘의 플로우를 요약하자면, "버킷은 초당 정해진 개수의 토큰을 만들어 내는데, 가져갈 토큰이 남아 있는 경우에만 유저는 요청에 대한 처리를 받을 수 있고, 토큰이 없는 경우 유저의 요청 처리는 반려된다."
이러한 토큰 버킷 알고리즘 기반 처리율 장치는 Java Bucket4J 라이브러리를 활용하면 손쉽게 구현할 수 있다. Bucket4J는 버킷 생성, 토큰 사용, 토큰 재충전 등의 기능을 제공하므로 개발자는 시스템 요구사항에 맞게 값을 튜닝만하면 된다. 또한 내부적으로 원자적 연산, 비동기로 동작하기 때문에 동시성 문제나 성능 문제로부터 자유롭다.
그렇다면 개발자가 기술적으로 고려해야 할 사항들은 무엇일까? 아래는 내가 구현시 고려한 사항들이다.
1. 위치
먼저 버킷을 어디에서 관리할지, 처리율 장치를 어디에서 동작시킬지를 결정해야 한다. 버킷은 애플리케이션 인메모리, Redis, RDB 등 다양한 위치에서 관리할 수 있다. 또한 처리율 장치가 동작하는 위치를 결정해야 하는데 크게 Filter, Interceptor, AOP를 활용할 수 있다.
📌 나는 분산환경에서 동기화 이슈를 생각해서 Redis를 선택했다. 또한 동작 위치로는 Filter를 선택했는데 그 이유는 해당 기능은 스프링과는 무관한 공통 관심사 영역에 속한다고 생각했기 때문이다. 물론 인터셉터나 AOP를 활용할 수도 있을것이다.
2. 버킷 생성 개수
시스템의 트래픽 제한 요구 사항에 따라 버킷의 개수를 커스터마이징해야 한다. 예를 들어, 각 API에 대해 1분에 10,000번의 트래픽 제한이 필요하다면, API마다 버킷이 필요하다. 반면, IP 주소별로 트래픽을 제한한다면 IP 주소마다 버킷이 필요하고, 시스템 전체 트래픽을 초당 10,000개로 제한하려면 1개의 버킷만 필요하다.
📌 나는 공격자가 악의적으로 트래픽 요청을 보내는 DOS 공격을 방지하고자 IP 주소마다 버킷을 관리했다.
3. Bandwidth
Bandwidth(대역폭)란 버킷의 제한 사항을 나타낸다. Bandwidth은 Capacity, Refill 전략으로 구성된다.
int CAPACITY = 10;
Bandwidth intervalBandwidth = Bandwidth.classic(CAPACITY, intervalTokenRefill);
Bandwidth greedyBandwidth = Bandwidth.classic(CAPACITY, greedyTokenRefill);1. capacity
버킷에 담을 수 있는 토큰의 최대 수를 의미한다.
2. Refill
버킷에서 토큰을 사용한 후, 토큰을 채우는 전략을 의미한다. 전략으로 Intervally와 Greedy가 존재한다.
- Intervally : 전체 기한이 경과될 때까지 기다렸다가 전체 토큰을 일괄적으로 다시 생성한다.
- ex) 1분마다 10개의 토큰이 한번에 생성된다.
Refill intervalTokenRefill = Refill.intervally(10, Duration.ofSeconds(60));
- ex) 1분마다 10개의 토큰이 한번에 생성된다.
- Greedy : 일정 간격마다 동일한 속도로 토큰을 생성한다.
- ex) 6초에 1개씩 토큰이 생성된다.
Refill greedyTokenRefill = Refill.greedy(10, Duration.ofMinutes(60));
- ex) 6초에 1개씩 토큰이 생성된다.
📌 예상되는 트래픽 패턴, 시스템 요구 사항 등을 고려해서 설정해야한다. 나는 capacity를 60, Greedy 전략을 사용했다.
구현
-
build.gradle
//Bucket4j implementation 'com.bucket4j:bucket4j-core:8.9.0' implementation 'com.bucket4j:bucket4j-redis:8.9.0'
-
RedisConfig
ProxyManager는 Bucket4J에서 제공하는 클래스로 Redis를 이용해 각 클라이언트의(IP) 버킷을 저장하고 관리하는 역할을 한다. 각각의 버킷은 일정 기간 동안 사용되지 않으면 redis에서 삭제되도록 만료 전략을 명시해야한다. 나는basedOnTimeForRefillingBucketUpToMax메서드를 사용해서 token이 refill 된 이후, 1분간 사용되지 않으면 만료시켰다.@Configuration public class RedisConfig { @Value("${spring.data.redis.port}") private int port; @Value("${spring.data.redis.host}") private String host; private RedisClient redisClient() { return RedisClient.create(RedisURI.builder() .withHost(host) .withPort(port) .build()); } ... @Bean public ProxyManager<String> lettuceBasedProxyManager() { RedisClient redisClient = redisClient(); StatefulRedisConnection<String, byte[]> redisConnection = redisClient .connect(RedisCodec.of(StringCodec.UTF8, ByteArrayCodec.INSTANCE)); // Expiration 전략 설정 return LettuceBasedProxyManager.builderFor(redisConnection) .withExpirationStrategy( ExpirationAfterWriteStrategy.basedOnTimeForRefillingBucketUpToMax(Duration.ofMinutes(1L))) .build(); } }
-
RateLimitFilter
요청이 들어오면 RateLimitFilter가 처리율 장치로 동작한다. 요청이 들어온 IP 주소를 기반으로 버킷을 조회해(없으면 생성) 토큰을 소비한다. 성공하면 다음 필터 or Dispatcher Servlet로 넘어가고 실패하면 429 status를 반환한다.@Component @Slf4j public class RateLimitFilter implements Filter { private ProxyManager<String> proxyManager; private final int CAPACITY = 60; private final int GREEDY_TOKEN_REFILL_COUNT = 10; private final int GREEDY_TOKEN_REFILL_MINUTES = 1; @Autowired public RateLimitFilter(ProxyManager<String> proxyManager) { this.proxyManager = proxyManager; } @Override public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException { HttpServletRequest httpRequest = (HttpServletRequest) servletRequest; String key = httpRequest.getRemoteAddr(); // IP 기반, 필요시 커스텀 Supplier<BucketConfiguration> bucketConfigurationSupplier = getConfigSupplier(); Bucket bucket = proxyManager.builder().build(key, bucketConfigurationSupplier); // 기존 버킷이 존재하면 조회, 없으면 생성 ConsumptionProbe probe = bucket.tryConsumeAndReturnRemaining(1); if (probe.isConsumed()) { filterChain.doFilter(servletRequest, servletResponse); } else { HttpServletResponse httpServletResponse = makeRateLimitResponse(servletResponse, probe); } } public Supplier<BucketConfiguration> getConfigSupplier() { Refill greedyTokenRefill = Refill.greedy(GREEDY_TOKEN_REFILL_COUNT, Duration.ofMinutes(GREEDY_TOKEN_REFILL_MINUTES)); Bandwidth greedyBandwidth = Bandwidth.classic(CAPACITY, greedyTokenRefill); return () -> BucketConfiguration.builder() .addLimit(greedyBandwidth) .build(); } // 에러 핸들링 private HttpServletResponse makeRateLimitResponse(ServletResponse servletResponse, ConsumptionProbe probe) throws IOException { HttpServletResponse httpResponse = (HttpServletResponse) servletResponse; httpResponse.setContentType("text/plain"); httpResponse.setHeader("X-Rate-Limit-Retry-After-Seconds", "" + TimeUnit.NANOSECONDS.toSeconds(probe.getNanosToWaitForRefill())); httpResponse.setStatus(429); httpResponse.getWriter().append("Too many requests"); return httpResponse; } }
테스트
테스트의 용이성을 위해 intervally refill 전략을 선택했다.
테스트 환경
CAPACITY : 6
INTERVAL_TOKEN_REFILL_COUNT : 6
GREEDY_TOKEN_REFILL_MINUTES : 1
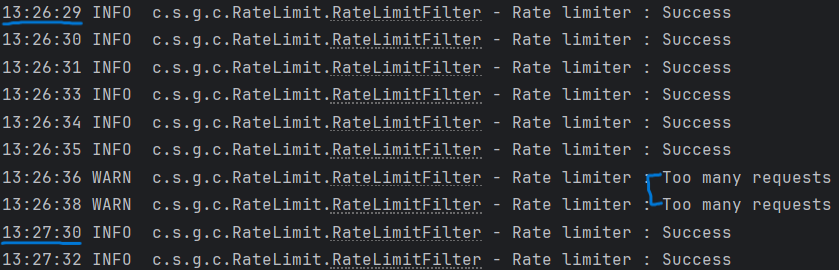
처음 6번의 요청은 정상 처리되었으며, 이후 요청은 "Too many requests" 메시지를 출력했다. 또한, 최초 요청 후 1분이 지나면 토큰이 6개로 다시 채워져, 다시 요청이 정상적으로 처리됨을 확인할 수 있었다.

결론
이상으로 Bucket4J 라이브러리를 활용하여 토큰 버킷 기반의 처리율 제한 장치를 구축해 보았다. 처리율 장치를 통해 DOS 공격과 서버 과부하를 방지함으로써 시스템 안정성을 높일 수 있었다. 참고로 처리율 장치는 Bucket4J 외에도 다양한 방법으로 구현할 수 있으며, 시스템의 미들웨어와 트래픽 관리 전략에 맞춰 유연하게 선택하는 것이 중요하다.
참고
처리율 제한 장치
Rate Limiting a Spring API Using Bucket4j
bucket4j 8.9.0 참조
