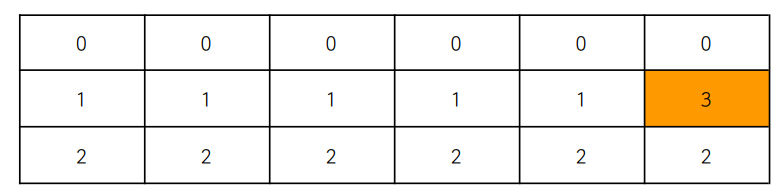
메모리 계층
메모리 계층은 레지스터, 캐시, 주기억장치, 보조기억장치로 구성되어 있다. 레지스터와 캐시는 CPU가 관리하고 주기억장치와 보조기억장치는 OS가 관리한다.
- 레지스터 : CPU 내의 작은 메모리, 휘발성, 속도 가장 빠름, 기억 용량이 가장 적음.
- 캐시 : CPU 내의 L1, L2 캐시, 휘발성, 속도 빠름, 기억 용량이 적음.
- 주기억장치 : RAM을 지칭, 휘발성, 속도 보통, 기억 용량이 보통.
- 보조기억장치 : HDD, SSD를 지칭, 비휘발성, 속도 낮음, 기억 용량이 큼.
Block : 하드 디스크와 메모리 사이의 데이터 전송 단위(1~4KB)
Word : 메모리와 레지스터 사이의 데이터 전송 단위(16~64bits) -> 32bits, 64bits 컴퓨터
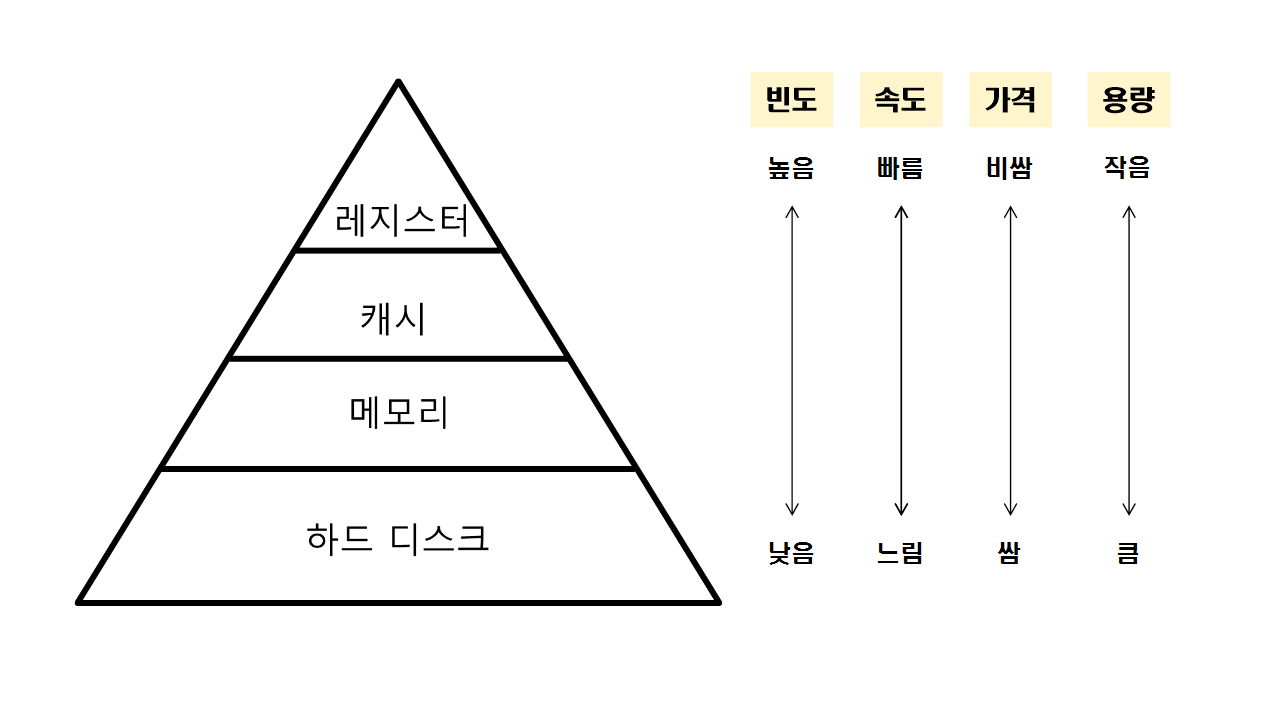
메모리 관리 장치(MMU)
보호
- Base register와 Limit register를 통해 잘못된 메모리 접근 요청이 오면 trap을 발생시켜 메모리 보호.
주소 변환
- Relocation register를 통해 논리 주소를 물리 주소로 변환.
- CPU는 실제 메모리 주소에 영향을 받지 않음.
메모리 관리
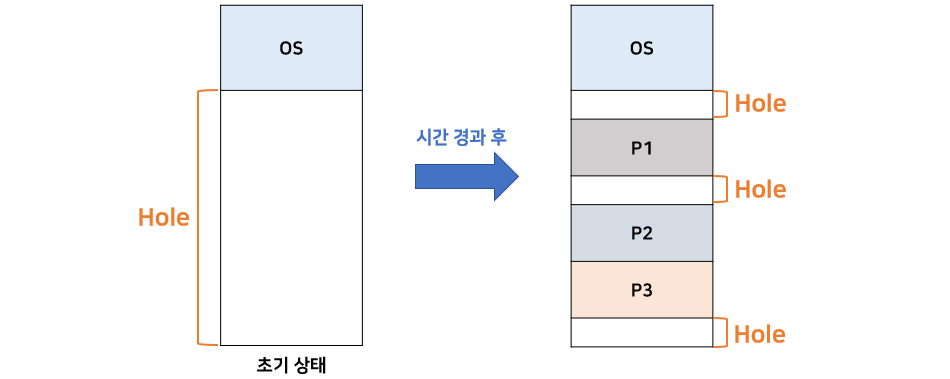
1. 연속 메모리 할당
- 프로세스를 메모리에 연속적으로 할당하는 기법.
- 할당과 제거를 반복하다 보면 Scattered Holes가 생겨나고 이로 인한 외부 단편화가 발생.
외부 단편화를 줄이기 위한 할당 방식
-
최초 적합(First fit) : 할당할 프로세스 크기보다 크거나 같은 hole을 탐색하되 가장 먼저 찾은 hole에 프로세스를 할당하는 방식
-
최적 적합(Best fit) : 할당할 프로세스 크기와 hole 크기의 차이가 가장 작은 hole에 프로세스를 할당하는 방식
-
최악 적합(Worst fit) : 최적 적합과 반대로, 할당할 프로세스 크기와 hole 크기의 차이가 가장 큰 hole에 프로세스를 할당하는 방식
속도와 효율성 측면에서 first fit과 best fit이 좋지만, 외부 단편화로 인해 전체 메모리의 1/3이 낭비된다고 한다.
2. 페이징
- 프로세스를 일정한 고정 크기의 page로 나누고 메모리는 일정한 고정 크기의 frame으로 나눈다.
- 메모리에 프로세스가 연속적으로 할당되지 않고 남는 프레임에 배치되기 때문에 외부 단편화가 발생하지 않는다.
- 실제 메모리는 불연속적인데 CPU는 연속적이라고 간주하고 작업을 한다.
- 앞서 MMU의 Relocation register가 논리주소를 물리 주소로 변환하는 역할을 한다고 했는데 Relocation register 여러 개를 묶어 페이지 테이블(Page table)이라 한다.
- 내부 단편화가 발생한다.
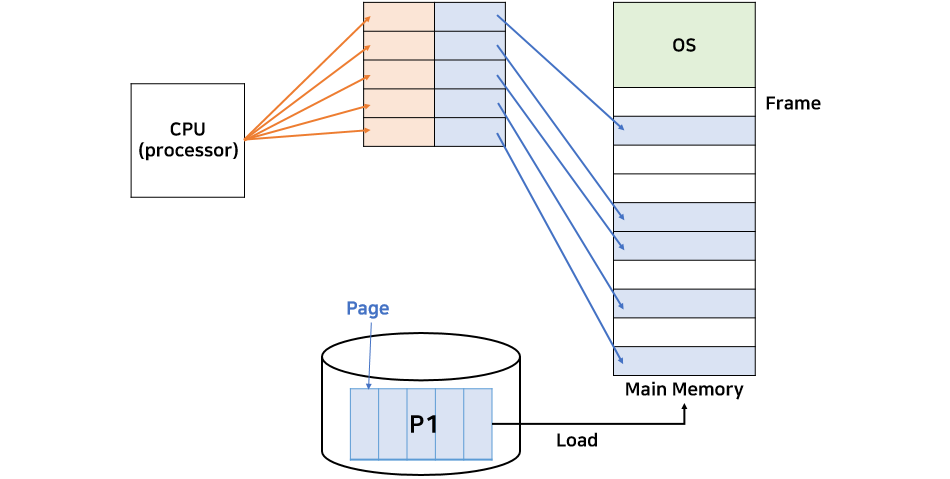
2.1 주소 변환
페이징 기법을 사용하기 위해서 여러 개로 흩어진 페이지에 CPU가 접근하기 위해서 페이지 테이블을 통해 논리주소를 물리 주소로 변환해야 한다.
- Page size = 16bytes
- Page Table: 5, 3, 2, 8, 1, 4
🤔 논리 주소는 2진수로 표현되고 m 비트로 이루어져 있다고 가정한다. 논리 주소 50번지는 물리 주소로 몇 번지일까?
-> 50은 이진수로 110010(2)이다. page size가 16 = 2^4 bytes이므로 d는 4칸으로 0010(2)이 된다. p는 d를 제외한 나머지 상위 2칸인 11(2)이 된다. p는 11(2) 즉, 십진수로 3이되고 page table에 따라 f = 8, 이진수로 1000(2)이 된다. d는 그대로다. 따라서 물리 주소는 이진수로 1000,0010(2), 10진수로 130번지가 된다.
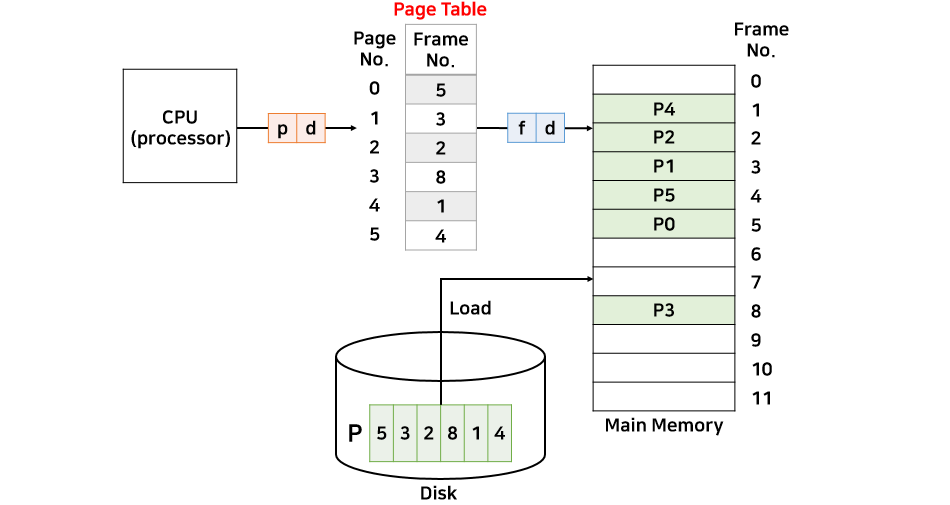
2.2 내부 단편화
페이징 기법을 사용하면 내부 단편화가 발생한다. 예를 들어 페이지 크기가 500byte이고 프로세스 A가 1300byte의 메모리를 요구한다면 2개의 frame(500 * 2 = 1000) 하고도 300byte가 모자라기 때문에 총 3개의 frame이 필요하다. 하지만 3번째 프레임에는 200(500-300)의 여유 공간이 발생하는데 이를 내부 단편화라 부른다. 내부 단편화는 해결할 방법이 없지만 외부 단편화에 비해서 낭비되는 메모리 공간이 매우 적다.
2.3 페이지 테이블
-
레지스터로 페이지 테이블을 만들 경우
- 장점 : 주소 변환 속도가 빠르다.
- 단점 : 레지스터 크기가 한정적이라 테이블 크기가 매우 제한된다.
-
메모리 내부에 페이지 테이블을 만들 경우
- 장점 : 페이지 테이블의 크기에 제한이 없다.
- 단점 : 주소 변환을 위한 메모리에 접근, 실제 주소에 접근하기 위한 메모리 접근, 즉 총 2번의 메모리 접근이 필요하기 때문에 느리다.
따라서 페이지 테이블을 캐시로 만들어 CPU와 메모리 사이에 위치시키는데 이러한 테이블을 TLB(Translation Look-aside Buffer) 라고 부른다. 이는 레지스터일 때보다 변환 속도는 느리고 메모리일 때보다 테이블 크기는 작지만, 레지스터일 때보다 테이블 크기가 크고 메모리일 때보다 변환 속도가 빠르다.
3. 세그멘테이션
- 프로세스를 논리적인 내용의 단위인 세그멘트로 분할(ex : code, data, stack)
- 페이징 기법의 페이지 테이블과 유사한 세그멘트 테이블 존재
- 페이징 기법과 비교하여 보호와 공유에 효과적 -> 페이징에서는 code + data + stack 영역이 있을 때 이를 일정한 크기로 나누므로 두 가지 영역이 섞일 수 있기 때문에
세그멘테이션에서는 프로세스를 논리적인 단위로 나누기 때문에 세그먼트의 크기가 다양하므로 외부 단편화 문제가 발생한다. 따라서 오늘날에는 세그멘테이션보다는 페이징 기법을 주로 사용한다. 세그멘트를 페이징 기법으로 나누는 두 가지를 합친 방식인 Paged segmentation도 있다. 하지만 세그먼트와 페이지가 동시에 존재하기 때문에 주소 변환도 두번 해야 한다. 즉 CPU에서 세그먼트 테이블에서 주소 변환을 하고, 그다음 페이지 테이블에서 또 주소 변환을 해야 한다.
가상 메모리
가상 메모리는 물리 메모리 크기의 한계를 극복하기 위해 나온 기술로 이를 활용하면 100MB 메모리 크기에 200MB 크기의 프로세스를 수행할 수 있다. 가상 메모리의 핵심은 필요한 부분만 메모리에 적재하는 것이다. 단위는 페이지 혹은 세그멘트 둘 다 가능하지만 오늘날에는 대부분 페이지 단위를 사용한다. 이처럼 현재 필요한 페이지만 메모리에 올리는 것을 Demanding Paging(요구 페이징)이라고 하며 가상 메모리로 통용해서 부른다.
1. Demanding Paging
Demanding Paging에서는 앞서 살펴본 페이징 기법의 page table에 valid bit가 추가되었다. 이는 현재 메모리에 페이지가 있는지 없는지를 나타내는 비트이다. 현재 페이지가 메모리에 있다면 1, 없다면 0값을 갖는다.
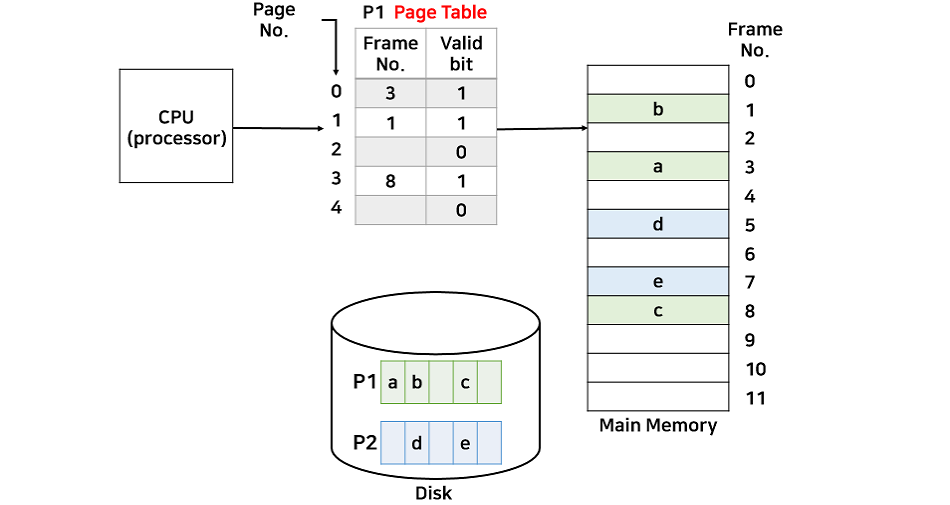
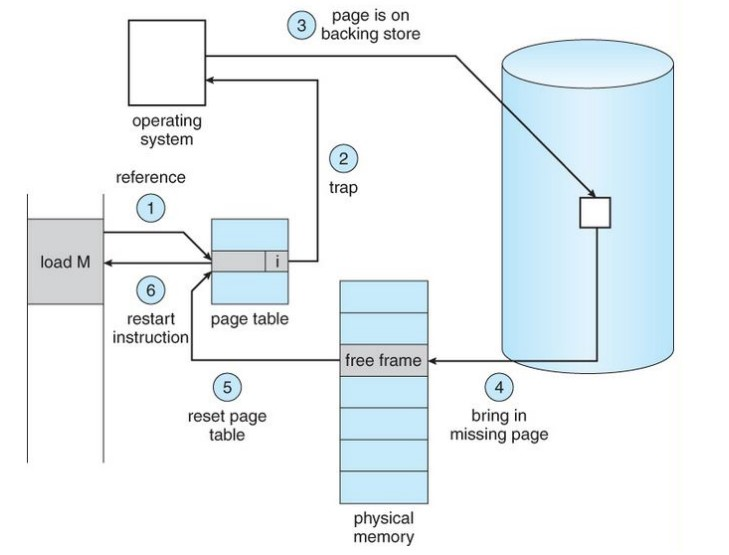
2. 페이지 부재(Page fault)
Page fault는 위에서 살펴본 CPU가 접근하려는 페이지가 메모리에 없는 경우이다. 즉, 페이지 테이블의 valid bit 값이 0인 경우이다. 아래는 page fault 과정을 나타낸다.
- 해당 페이지가 메모리에 있는지 valid bit를 확인한다.
- valid bit가 0이라면 CPU에 인터럽트 신호를 보내어 운영체제 내부 해당 ISR로 점프한다.
- 해당 ISR에서 backing store(디스크)를 탐색하여 해당 프로세스의 페이지를 찾는다.
- 해당 페이지를 비어있는 프레임에 할당한다.
- 페이지 테이블을 갱신한다.(프레임 번호 설정, valid bit 1로 변경)
- 다시 명령어로 돌아가서 실행한다.
Swapping vs Demanding Paging
공통점 : 둘 다 메모리와 backing store 사이의 상호작용
차이점 : Swapping은 프로세스 단위로 이동하고 Demanding Paging은 페이지 단위로 이동
3. 페이지 교체(with 알고리즘)
메모리가 꽉 차면 이미 메모리에 있는 페이지 중 하나를 다시 backing store에 보내고(page-out), 새로운 페이지를 메모리에 올려야한다(page-in). 이를 페이지 교체라고 한다.
3.1 Optimal
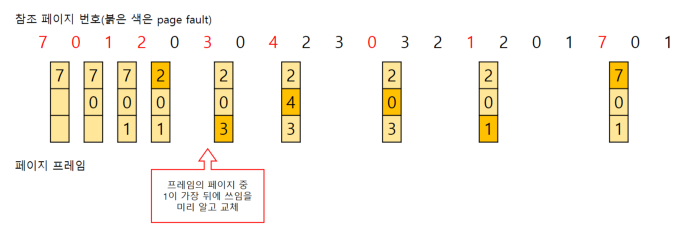
Optimal 알고리즘은 가장 좋은 알고리즘이라고 일컫는 알고리즘이며 이는 가장 먼 미래에
참조되는 페이지와 현재의 페이지를 바꾸는 알고리즘(LFD, Longest Forward Distance)이다. 예를 들어 0, 1, 2, 3, 4, 2 이렇게 들어온다고 가정하면 가장 미래에 참조되는 2와 스와핑하는 것을 말한다. 그러나 미래에 사용되는 프로세스를 우리는 알지 못한다. 따라서 사용할 수 없는 알고리즘이다.
3.2 FIFO
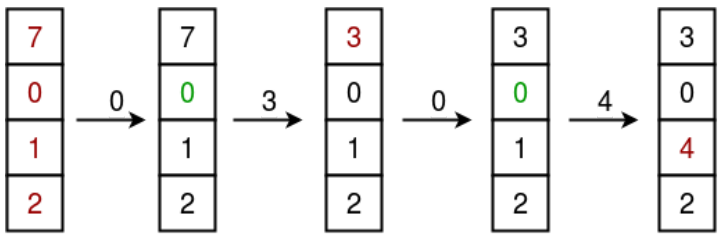
FIFO(First In First Out) 알고리즘은 가장 먼저 온 페이지부터 교체한다.
3.3 LRU
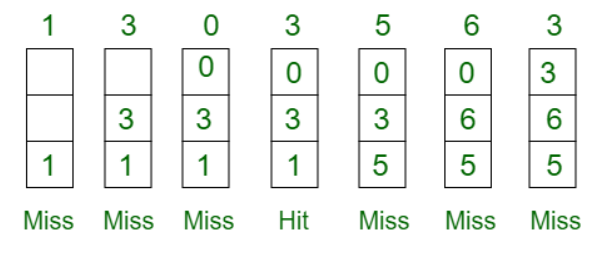
LRU(Least Recently Used) 알고리즘은 최근에 사용되지 않은 페이지 즉, 참조가 오래된 페이지를 바꾼다. 이를 위해서 각 페이지마다 최근 사용한 횟수를 나타내는 자료구조를 따로 만들어야 할 수도 있다. 예를 들어 7 0 1 2 0 3 0 4로 페이지 요청이 들어온다고 가정하고 4개의 페이지만 담는다고 가정하면 아래와 같이 된다.
3.4 NUR
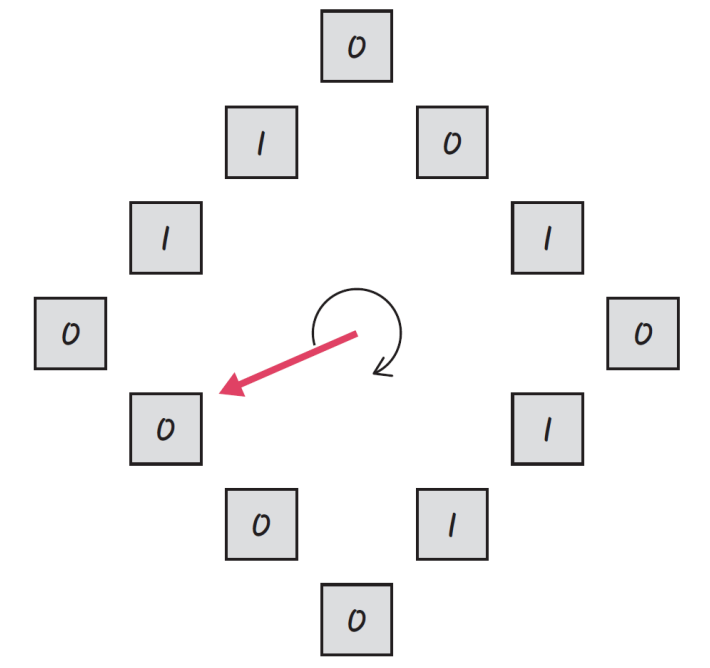
LRU에서 발전한 알고리즘이자 NUR(Not Used recently) 또는 NRU(Not Recently Used)
라고도 불리는 알고리즘이다. 일명 clock 알고리즘이라고 하며 먼저 0과 1을 가진 비트를 둔다. 1은 최근에 참조되었고 0은 참조되지 않음을 의미한다. 만약 한 바퀴 도는 동안 사용되지 않으면 0이 된다. 시계 방향으로 돌면서 0을 찾고 0을 찾은 순간 해당 페이지를 교체하고, 해당 부분을 1로 바꾸는 알고리즘이다.
3.5 LFU
LFU(Least Frequently Used) 알고리즘은 가장 참조 횟수가 적은 페이지를 교체하는
알고리즘이다. 예를 들어 0, 1, 2, 0, 0, 1, 2, 3 이렇게 들어오고 3개의 페이지밖에 없다고 하면 다음과 같이 교체된다.