Read Replica란?
Read Replica란 Read/Write 모두 가능한 Master DB 인스턴스에 비해 SELECT 쿼리와 같은 Read 작업만 수행 가능한 DB 인스턴스다. Read Replica를 흔히 Slave라고 부른다. Read Replica를 통해 DB를 Master, slave로 이중화하면 아래와 같은 장점이 있다.
-
부하 분산
서비스에 사용자가 많아져 트래픽이 늘어날 경우, DB에 쿼리를 날리는 일이 빈번하게 일어난다. DB에서는 쿼리를 모두 처리하기 부담이 되고 이에 따라 부하를 줄이기 위해 DB를 이중화하여 Master에서는 insert, update, delete 연산을 처리하고 Slave에서는 read 연산만을 처리하여 트래픽을 분산할 수 있다. -
데이터 백업
Master의 데이터가 날아가더라도 Slave에 데이터가 저장되어 Slave를 Master로 승격시켜서 데이터를 복구할 수 있다. 다만 RDS의 Read Replica는 비동기 방식이기 때문에 100% 정합성을 보장할 수 없다.
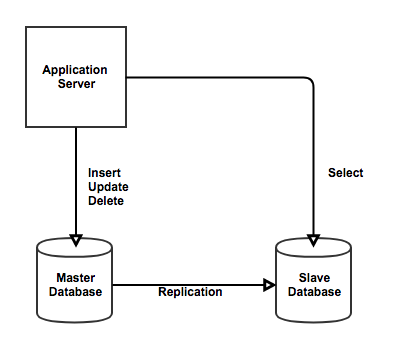
RDS Replica는 기본적으로 비동기 복제 방식을 이용한다. 따라서 Master로부터 Slave로 복제되는 시간 사이에 데이터 정합성 문제가 발생할 수 있다. 하지만 실시간성이 높은 데이터의 경우 Master DB에 요청보내면 충분히 해결 가능하다고 생각해서 프로젝트에 RDS Replica를 도입했다.
RDS 생성하기
위에서 살펴본 Read Replica와 Multi AZ를 함께 사용해보자. 둘을 함께 사용하면 Read Replica를 통해 부하 분산, Multi AZ를 통해 장애 복구의 이점을 얻을 수 있다.
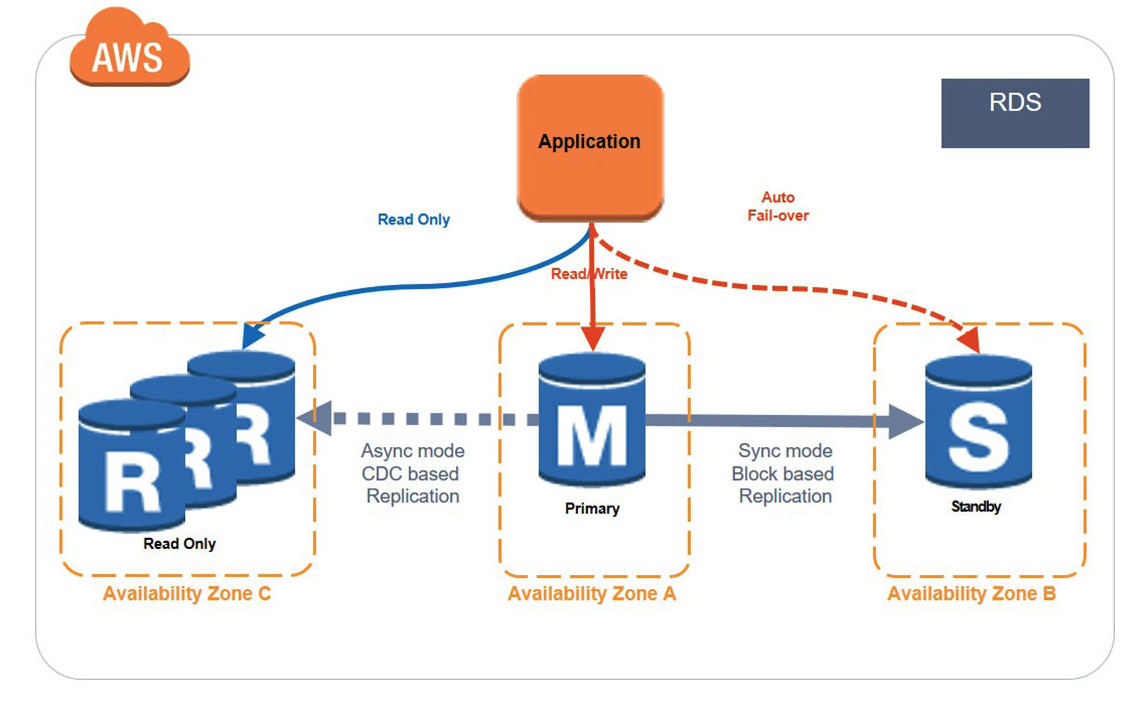
- Read Replica
복제하고자 하는 DB를 선택하고 "읽기 전용 복제본 생성"을 클릭한다.
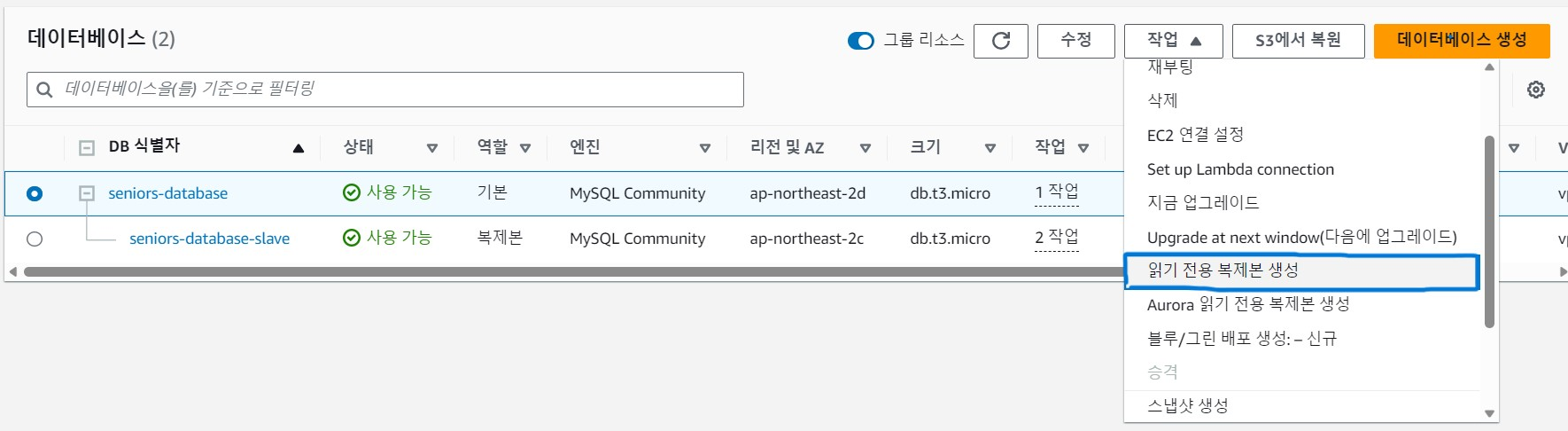
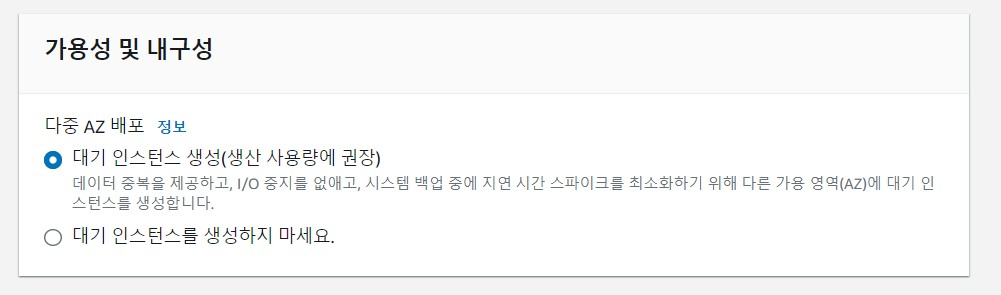
- Multi AZ
DB 설정 탭에서 "대기 인스턴스 생성"을 선택하면 된다.
Read Replica 구축하기
Version 1 : DB 커넥션 지연 조회
Read Replica는 애플리케이션 내부에서 어떤 DB로 요청을 보낼지 설정해줘야 해서 따로 설정이 필요하다.
application.yml
Master, Slave DB 정보를 입력한다.
spring:
datasource:
master:
hikari:
username: <master의 user 이름>
password: <master의 비밀번호>
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://<master의 IP주소:포트>/db?serverTimezone=Asia/Seoul
slave:
hikari:
username: <slave의 user 이름>
password: <slave의 비밀번호>
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://<slave의 IP주소:포트>/db?serverTimezone=Asia/SeoulDataSourceConfig
Master, Slave datasource를 yml 파일로부터 정보를 받아 빈으로 등록한다. 아래 코드에서 주목해야 할 부분은 LazyConnectionDataSourceProxy이다. 기본적으로 JPA는 @Transactional을 만나면 아래 순서로 처리를 한다.
- transactionManager 선별
- Datasource에서 connection 획득
- transaction 동기화
하지만 지금 로직은 transaction 동기화가 먼저 되어야 RoutingDataSource에서 커넥션을 획득할 수 있다. 따라서 RoutingDataSource를 LazyConnectionDataSoruceProxy로 감싸줘야 한다. LazyConnectionDataSoruceProxy는 트랜잭션 시작시에 Connection Proxy 객체를 리턴하고 실제로 쿼리가 발생할 때 determineLookupKey()를 호출해 실제 커넥션을 얻는다. 따라서 다음과 같이 동작하게 된다.
- transactionManager 선별
- LazyConnectionDataSourceProxy에서 Connection Proxy 객체 획득
- Transaction 동기화
- 실제 쿼리 호출시에 RoutingDataSource의 determineLookupKey를 통해 실제 커넥션 호출
@Configuration
public class DataSourceConfig {
@Bean(MASTER_DATASOURCE)
@ConfigurationProperties(prefix = "spring.datasource.master.hikari")
public DataSource masterDataSource() {
return DataSourceBuilder.create()
.type(HikariDataSource.class)
.build();
}
@Bean(SLAVE_DATASOURCE)
@ConfigurationProperties(prefix = "spring.datasource.slave.hikari")
public DataSource slaveDataSource() {
return DataSourceBuilder.create()
.type(HikariDataSource.class)
.build();
}
@Bean
public DataSource routingDataSource(
// masterDataSource와 slaveDataSource라는 이름을 가진 Bean을 주입
@Qualifier(MASTER_DATASOURCE) DataSource masterDataSource,
@Qualifier(SLAVE_DATASOURCE) DataSource slaveDataSource) {
RoutingDataSource routingDataSource = new RoutingDataSource();
Map<Object, Object> datasourceMap = ImmutableMap.<Object, Object>builder()
.put("master", masterDataSource)
.put("slave", slaveDataSource)
.build();
routingDataSource.setTargetDataSources(datasourceMap);
routingDataSource.setDefaultTargetDataSource(masterDataSource);
return routingDataSource;
}
@Primary
@Bean
public DataSource dataSource(@Qualifier("routingDataSource") DataSource routingDataSource) {
// 지연 연결 기능을 제공하기 위해서 사용
return new LazyConnectionDataSourceProxy(routingDataSource);
}
}RoutingDataSource
현재 트랜잭션이 readOnly일 시 slave 데이터 소스 이름을, 아닐 시 master db의 DataSource의 이름을 리턴하도록 해준다. 로그를 통해 트랜잭션마다 어떤 datasource를 획득했는지 알 수 있다.
@Slf4j
public class RoutingDataSource extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
boolean isReadOnly = TransactionSynchronizationManager.isCurrentTransactionReadOnly();
if (isReadOnly) {
log.info("Slave DataSource 호출 => ");
} else {
log.info("Master DataSource 호출");
}
return isReadOnly ? "slave" : "master";
}
}JpaConfig
@Configuration
@EnableTransactionManagement
public class JpaConfig {
@Bean
public LocalContainerEntityManagerFactoryBean entityManagerFactory(
@Qualifier("dataSource") DataSource dataSource) {
LocalContainerEntityManagerFactoryBean entityManagerFactory
= new LocalContainerEntityManagerFactoryBean();
entityManagerFactory.setDataSource(dataSource);
entityManagerFactory.setPackagesToScan("com.seniors.domain");
entityManagerFactory.setJpaVendorAdapter(jpaVendorAdapter());
entityManagerFactory.setPersistenceUnitName("entityManager");
return entityManagerFactory;
}
private JpaVendorAdapter jpaVendorAdapter() {
HibernateJpaVendorAdapter hibernateJpaVendorAdapter = new HibernateJpaVendorAdapter();
// 여기서 create, update 등 ddl-auto 값 설정 가능
hibernateJpaVendorAdapter.setGenerateDdl(true);
hibernateJpaVendorAdapter.setShowSql(true);
hibernateJpaVendorAdapter.setDatabasePlatform("org.hibernate.dialect.MySQLDialect");
hibernateJpaVendorAdapter.setDatabase(Database.MYSQL);
return hibernateJpaVendorAdapter;
}
@Bean
public PlatformTransactionManager transactionManager (
@Qualifier("entityManagerFactory") LocalContainerEntityManagerFactoryBean entityManagerFactory) {
JpaTransactionManager jpaTransactionManager = new JpaTransactionManager();
jpaTransactionManager.setEntityManagerFactory(entityManagerFactory.getObject());
return jpaTransactionManager;
}
}Version 2 : 스프링 AOP 활용
앞서서 LazyConnectionDataSourceProxy를 활용해서 @Transactional(readOnly=true)는 slave DB, @Transactional은 Master DB로 분기 처리했다. 그리고 RDS Replica는 기본적으로 비동기 복제 방식을 이용하므로 Master로부터 Slave로 복제되는 시간 사이에 데이터 정합성 문제가 발생할 수 있다고 하였다.
그렇다면 만약에 실시간성이 중요한 데이터를 조회하려 한다면 어떻게 하면 좋을까?
처음에 생각했던 방법은 readOnly=true를 포기하고 master DB로 데이터를 요청하면 되지 않을까라고 생각했다. 하지만 내가 생각하기에 readOnly=true의 이점은 아래와 같았고 포기하고 싶지 않았다.
- 명시적으로 개발자에게 이 메서드는 읽기만하는 메서드임을 알림.
- JPA를 사용하는 경우 변경 감지 작업을 수행하지 않아 성능상 이점.
따라서 @Transactional(readOnly=true)와 함께 master DB로부터 데이터를 조회할 수 있는 방안을 고민하였고 스프링 AOP를 활용하기로 했다. AOP를 추가한 전체적인 플로우는 아래와 같다.
- 컨트롤러에서 서비스에 접근할 때 AOP 프록시 호출
- 프록시에서
@Database(MASTER)유무 확인 @Database(MASTER)가 존재한다면 스레드 로컬에 master DB flag 저장@Database(MASTER)가 존재하지 않는다면 SKIP- repository단에서 LazyConnectionDataSourceProxy를 통한 DB 커넥션 지연 조회
- 만약 스레드 로컬에 master DB flag 존재한다면 master DB 커넥션 획득
- 만약 스레드 로컬에 master DB falg 존재하지 않는다면
@Transactional(readOnly = true)여부에 따른 DB 커넥션 획득
DataSourceHolder
스레드 로컬을 활용하여 AOP의 Advice로부터 얻은 dB 커넥션 정보를 보관한다.
@Component
public class DataSourceHolder {
private static final ThreadLocal<DatabaseType> DATABASE_TYPE_HOLDER = new ThreadLocal<>();
public static DatabaseType getDatabaseType() {
return DATABASE_TYPE_HOLDER.get();
}
public static void setDatabaseType(DatabaseType databaseType) {
DATABASE_TYPE_HOLDER.set(databaseType);
}
public static void clearDatabaseType() {
DATABASE_TYPE_HOLDER.remove();
}
public static boolean isNotEmpty() {
return DATABASE_TYPE_HOLDER.get() != null;
}
}RepositoryDataSourceAspect
AOP를 활용해 서비스 로직에 접근하기 전에 @Database(MASTER) 유무를 검사한다. 만약 해당 어노테이션이 존재한다면 스레드 로컬에 master DB flag를 보관한다.
@Component
@Aspect
public class RepositoryDataSourceAspect {
@Pointcut("execution(* *..*Service.*(..))")
private void serviceMethods() {
}
@Around("serviceMethods() && @annotation(database)")
public Object handler(ProceedingJoinPoint joinPoint, Database database) throws Throwable {
try {
DataSourceHolder.setDatabaseType(database.value());
Object returnType = joinPoint.proceed();
return returnType;
} finally {
DataSourceHolder.clearDatabaseType();
}
}
}RoutingDataSource
현재 스레드 로컬에 master DB flag가 있는지 확인하는 로직을 추가한다.
@Slf4j
@RequiredArgsConstructor
public class RoutingDataSource extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
if (DataSourceHolder.isNotEmpty()) {
DatabaseType databaseType = DataSourceHolder.getDatabaseType();
log.info("look up dataSoruce ={}", databaseType);
return databaseType;
}
boolean readOnly = TransactionSynchronizationManager.isCurrentTransactionReadOnly();
if (readOnly) {
log.info("readOnly = true, request to replica");
return DatabaseType.SLAVE;
}
log.info("readOnly = false, request to master");
return DatabaseType.MASTER;
}
}
