배열(Array)
-
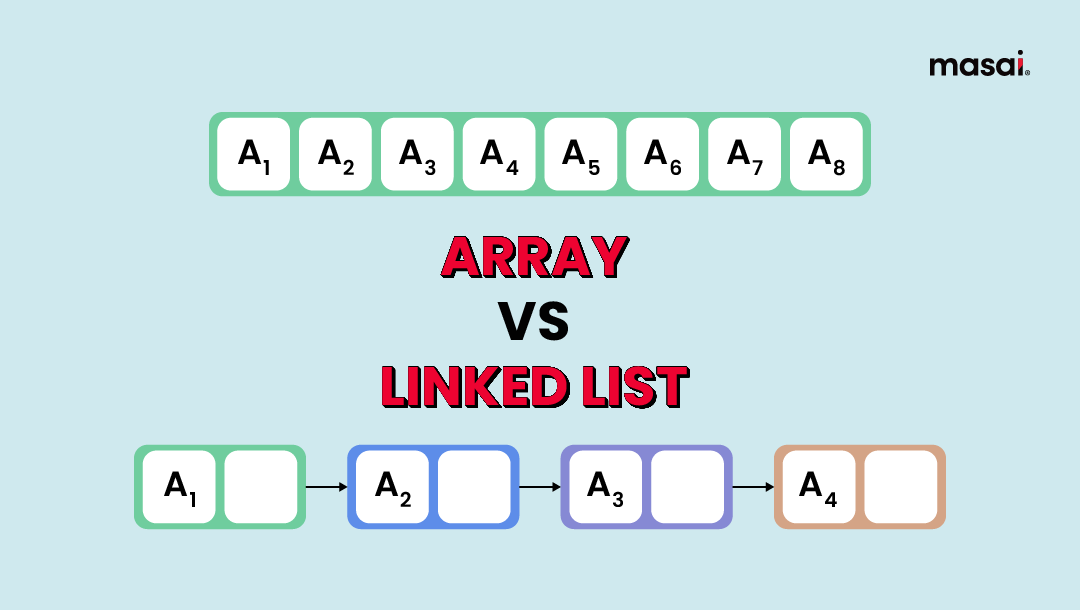
배열은 동일한 자료형의 집합으로 구성되고 지정된 크기 만큼의 연속된 메모리 공간을 할당 받는 자료구조이다.
-
배열의 각 요소는 인덱스 또는 키로 접근할 수 있다. 즉 랜덤 접근이 가능하다.
-
배열의 모든 요소의 자료형은 모두 같고, 배열 자체는 연속된 메모리 공간을 차지하기 때문에 간단한 주소 연산 만으로 배열을 구성하는 요소의 위치를 알 수 있다.
-
CPU에서 메모리에 적재된 데이터를 불러올 때는 요청하는 데이터를 하나씩 가져오는 게 아니라 메모리의 대역폭에 맞춰서 주변 데이터를 블럭 단위로 한꺼번에 가져와서 캐시에 적재한다.
-
그리고나서 데이터가 캐시에 있으면 바로 불러오고 없으면 다시 다른 데이터 블럭을 가져온다. 이러한 캐시 효과 덕분에 배열 같은 순차적 자료구조는 순서대로 데이터를 조회하는 것을 매우 빠르게 할 수 있다.
-
따라서 배열의 요소를 인덱스로 조회(접근)하는 시간 복잡도는 이 된다.
-
배열의 요소를 순차적으로 탐색하는 시간 복잡도는 이다.
-
최악의 경우엔 배열에 요소를 삽입하거나 삭제할 때 배열의 모든 요소를 재배치해야 하므로 배열의 크기 만큼의 연산이 필요하다. 따라서 삽입과 삭제에 대한 시간 복잡도는 이 된다.
-
배열은 인덱스로 원소에 빠르게 접근해야 하거나 간단하게 데이터를 다룰 때 사용하면 좋다. 데이터의 삽입과 삭제가 빈번하다면 배열보단 연결 리스트가 더 유리하다.
-
배열의 공간 복잡도는 이다.
-
미리 크기를 지정하고, 크기가 고정된 배열을 정적 배열이라 한다. 미리 크기를 지정하지 않고 자동으로 조정하거나 크기를 바꿀 수 있는 배열은 동적 배열이라 한다.
-
동적 배열의 크기 조정은 대개 더블링(doubling) 방식으로 이루어진다. 더블링이란 배열이 꽉 찰 때마다 기존 배열보다 2배 더 큰 새로운 배열을 만들어 데이터를 복사하는 방식을 말한다.
-
더블링이라고 반드시 2배로 늘리는 것은 아니며 비율은 언어 구현마다 다르다.
-
더블링 방식은 배열의 크기를 늘릴 때마다 데이터를 복사해야 하기 때문에 더블링 작업에 대한 시간 복잡도는 이 된다. 그러나 이는 자주 있는 일이 아니기 때문에 분할 상환(amortized) 관점으로 보면 이라 할 수 있다.
리스트(List) ADT와 연결 리스트(Linked List)
-
리스트란 목록 형식으로 구성된 자료구조이다. 연락처 목록, 장보기 목록, 체크 리스트 같은 것들이 바로 리스트이며 순열(sequence)이라 부르기도 한다.
-
리스트 ADT를 구현한 자료구조의 대표적인 예로 연결 리스트가 있다.
-
리스트를 배열로 구현할 수도 있지만, 리스트의 특성 상 요소들의 삭제와 삽입이 빈번하기 때문에 일반적으로 배열 보다는 연결된 노드 기반의 연결 리스트 구현이 더 효율적이다.
-
연결 리스트는 데이터 요소의 선형 집합으로, 노드들을 연결해서 만든 자료구조이다.
-
배열과는 다르게 연결 리스트는 원소들의 논리적인 순서와 물리적인 순서가 일치하지 않기 때문에 원소들 간의 순서를 표현할 수 있는 수단(포인터 등)이 필요하다.
-
연결 리스트를 구성하는 개별 요소를 노드(node, 마디)라고 부른다. 노드는 보통 데이터와 포인터로 구성된다.
-
연결 리스트의 첫 번째 노드는 헤드(head)이며 마지막 노드는 테일(tail)이다.
-
연결 리스트의 시작 부분을 알아야 하기 때문에 헤드 노드를 가리키는 포인터 변수가 필요하다. 이 변수는 C언어에서 배열명으로 배열의 시작부분에 접근하는 것과 비슷한 역할을 한다.
-
연결 리스트의 길이는 헤드부터 테일까지의 모든 노드의 개수와 같다.
-
연결 리스트는 동적으로 크기를 쉽게 변경할 수 있다.
-
연결 리스트의 요소의 삽입과 삭제는 배열처럼 모든 요소를 재배치할 필요가 없고 노드의 포인터를 초기화하거나 서로 연결해주면 되므로 시간 복잡도는 이 된다.
-
연결 리스트는 배열과는 달리 인덱스로 특정 요소에 직접 접근할 수 없고 모든 요소를 순차적으로 접근해야 하기 때문에 접근과 탐색의 시간 복잡도는 이 된다.
-
연결 리스트의 공간 복잡도는 이다.
-
연결 리스트는 크게 단순 연결 리스트, 이중 연결 리스트, 원형(환형) 연결 리스트로 구분한다.
단순 연결 리스트(Singly Linked List)
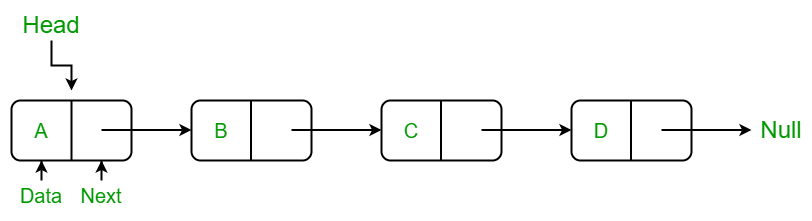
- 단순 연결 리스트는 노드에 데이터와 다음 노드를 가리키는 포인터(next)만 존재하며 노드가 한 방향으로만 연결되는 연결 리스트 이다.
- 그냥 연결 리스트라고 하면 대개 단순 연결 리스트를 말한다.
이중 연결 리스트(Doubly Linked List)
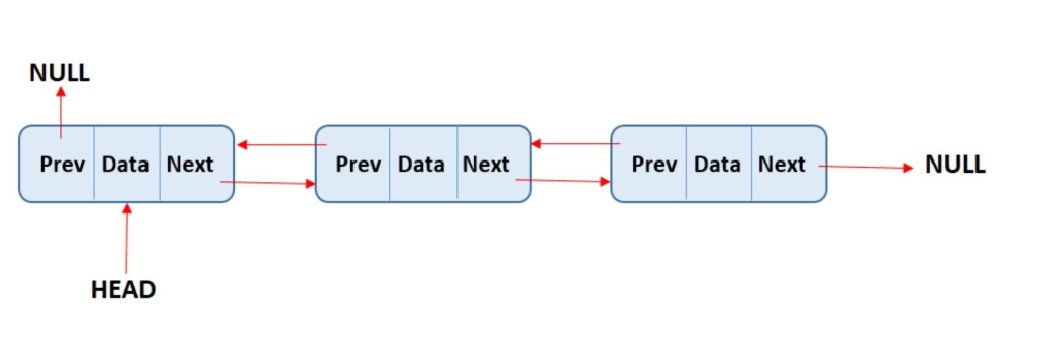
- 이중 연결 리스트는 단순 연결 리스트의 탐색 기능을 개선한 자료구조이다.
- 노드는 데이터와 이전 노드를 가리키는 포인터(prev), 다음 노드를 가리키는 포인터(next)로 구성된다.
- 즉, 단순 연결 리스트와 달리 노드가 앞뒤 양방향으로 연결된다.
원형 연결 리스트(Circular Linked List)
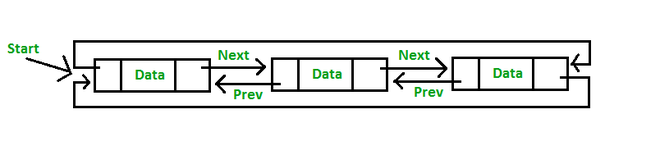
- 원형(환형) 연결 리스트는 테일 노드와 헤드 노드가 서로 연결된 연결 리스트이다.
- 원형 연결 리스트는 보통 이중 연결 리스트로 구성되지만 단순 연결 리스트로 만들 수도 있다.
- 단순 연결 리스트로 구성된 경우 테일 노드의 next 포인터는 헤드 노드를 가리킨다.
- 이중 연결 리스트로 구성된 경우 헤드 노드의 prev 포인터는 테일 노드를 가리키고, 테일 노드의 next 포인터는 헤드 노드를 가리킨다.
- 따라서 이중 원형 연결 리스트는 원소들을 헤드 노드 부터가 아닌 테일 노드부터 역순으로 탐색하거나 특정 노드의 선행 노드를 찾는 연산을 단순 원형 연결 리스트보다 더 효율적으로 할 수 있다.
배열과 연결 리스트의 비교
- 자료구조는 크게 메모리 공간 기반의 연속(contiguous) 방식과 포인터 기반의 연결(link) 방식으로 나뉜다.
- 연속 방식의 가장 기본적인 자료구조는 배열이며, 연결 방식의 가장 기본적인 자료구조는 연결 리스트 이다.
- 추상 자료형(ADT)의 실제 구현은 대부분 배열 또는 연결 리스트를 기반으로 한다. 예를 들면 스택은 연결 리스트로 구현하고, 큐는 배열로 구현하는 식이다.
- 배열과 리스트 모두 중복된 요소를 허용한다.
- 배열은 연속된 메모리 공간에 데이터를 저장하고 연결 리스트는 연속되지 않은 메모리 공간에 데이터를 저장한다.
- 배열의 한 요소를 참조하려면 인덱스로 직접 접근할 수 있지만 연결 리스트의 한 요소를 참조하려면 헤드 노드부터 테일 노드 까지 모든 요소에 순차적으로 접근해야 한다.
- 배열은 요소의 삽입과 삭제에 이 걸리고 조회에 이 걸린다.
- 연결 리스트는 요소의 삽입과 삭제에 이 걸리고 조회에 이 걸린다.
- 배열과 연결 리스트 모두 요소 탐색(순차 탐색)에는 이 걸린다.
- 따라서 요소를 추가하거나 삭제하는 연산이 많으면 연결 리스트가 좋고 요소를 조회하는 연산이 많으면 배열이 좋다.
언어 별 배열과 연결 리스트 사용
파이썬: 리스트(list), 데크(deque), array.array
- 파이썬의 내장 자료형 중에서는 배열같이 모든 요소가 동일한 자료형을 가지며 연속된 메모리 공간을 차지하는 자료형이 없다.
NumPy의ndarray는 연속된 메모리 공간을 차지하며 파이썬의 리스트보다 연산이 빠르지만 기본 모듈이 아니기 때문에 원칙적으론 코딩 문제 풀이 시엔 사용할 수 없다. 하지만 일부 사용 가능한 곳도 있다.- 기본 모듈인
array.array를 임포트해서 사용하면 파이썬에서도 C언어 배열과 비슷한 배열을 만들 수 있지만 한정적인 숫자 자료형만 사용 가능하다. array.array는 리스트보다 메모리 사용량이 적고 숫자 연산을 더 효율적으로 수행하기 때문에 필요한 경우 활용하면 좋다.- 파이썬에서 배열 또는 연결 리스트가 필요한 경우 대개 내장 자료형 리스트(list)를 사용한다.
- 파이썬의 리스트는 배열과 연결 리스트의 장점을 절충하여 편리하고 효율적인 데이터 연산이 가능한 자료형이다.
- 리스트는 배열이 아니지만 크기를 동적으로 변경할 수 있으므로 정적 배열보단 동적 배열에 가깝다.
- 연결 리스트에 대해선
collections모듈의deque(데크)를 사용할 수도 있다. 파이썬 내장 모듈이기 때문에 코딩 문제 풀이 시에도 문제 없이 쓸 수 있다. - 데크는 리스트와 비슷하게 사용할 수 있으면서 리스트에는 없는 기능도 지원하며 리스트보다 유리한 연산도 있다.
- 데크(deque)는 double ended queue의 약자로 이중 연결 리스트 구조의 자료형이다. 따라서 맨 앞이나 맨 뒤의 요소를 삽입(appendleft, append)하거나 추출하는(popleft, pop) 작업을 에 할 수 있다.
- 리스트의 맨 뒤에서 추출하는 연산은 에 할 수 있지만 맨 앞에서 삽입하거나 추출하려면 모든 요소를 한 칸씩 이동시켜야 되므로 이 걸린다.
- 따라서 맨 앞에서 요소를 추출하거나 제거하는 상황에선 리스트보다 데크가 유리하다.
C++: 배열, 벡터(std::vector), 리스트(std::list)
C스타일 배열과 표준 라이브러리 배열(std::array)
- C++의 배열은 C언어의 정적 배열과 마찬가지로 컴파일 타임에 크기가 결정되는 배열이다.
- 선언할 때 크기를 정할 수 있고, 크기를 빈 칸으로 하면 컴파일러가 크기를 알아서 설정한다.
- C++에선 C스타일 배열과 C++ 표준 라이브러리의
std::array를 사용할 수 있다. - std::array는 C스타일 배열보다 안전하고 편리한 기능을 제공한다.
- 코딩 문제 풀이 시엔 보통 C스타일이 편리하지만 일반적인 프로그래밍 시 std::array도 많이 사용한다.
- std::array는 헤더를 포함해야 사용 할 수 있다.
#include <array> - std::array는 다음과 같이 선언한다.
std::array<자료형, 크기> 배열명; - std::array는 C스타일 배열처럼 인덱스 연산자(
[])를 지원한다. - std::array는 또한 대입 연산자를 지원하여 깊은 복사를 할 수 있고,
array::size()로 크기를 구할 수 있으며 이터레이터를 지원한다. - 다음과 같은 방법으로 배열을 초기화할 수 있다.
int arr1[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
int arr2[]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}; // C언어 에선 = 필요
int arr3[10]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
std::array<int, 10> arr4{1, 2, 3, 4, 5, 6, 7, 8, 9, 10};std::vector
- C++ 표준 라이브러리의
std::vector는 동적 배열을 위한 자료형이다. - 벡터를 사용하려면 헤더를 포함해야 한다.
#include <vector> - 벡터는 다음과 같이 선언한다.
std::vector<자료형> 변수명; - 벡터는 배열과 마찬가지로 연속된 메모리 공간에 위치한 동일 자료형 요소들의 집합이며
숫자 인덱스를 기반으로 랜덤 접근이 가능하며 중복을 허용한다. - 벡터는 배열과 비슷한 특징을 가지면서도 배열의 단점을 보완한 동적 배열이다.
- 벡터의 요소에 접근하거나 맨 뒤에 있는 요소를 삭제하거나 삽입하는 경우 이 걸린다.
- 벡터의 맨 뒤나 맨 앞이 아닌 요소를 삭제하고 삽입하는 경우 이 걸린다.
- 벡터는 배열보다 더 다양한 메서드를 지원한다.
- 벡터의 크기를 처음부터 정하여 생성하고 초기화를 할 수도 있다
다음은 크기가 5이고 모든 원소를 100으로 초기화한 벡터를 선언한 것이다.std::vector<int> sv(5, 100); - 벡터는 동적 배열이기 때문에 처음에 크기를 정해서 생성해도 요소 삽입에 따라 용량이 자동으로 확장된다.
std::list
- C++ 표준 라이브러리의
std::list는 이중 연결 리스트로 구현된 컨테이너이다. - std::list를 사용하려면 헤더를 포함해야 한다.
#include <list> - std::list는 다음과 같이 선언한다.
std::list<자료형> 변수명; - std::list는 원소들의 순서를 유지한다. 원소를 삽입할 때나 삭제할 때, 다른 원소들에 영향을 주지 않고 순서가 유지된다.
- std::list는 동적 크기를 가지며, 필요에 따라 원소를 삽입하거나 삭제할 수 있다.
- std::list는 이중 연결 리스트로 구현되어 있기 때문에, 원소의 삽입과 삭제가 매우 효율적이다. 포인터 조정 만으로 원소를 삽입하거나 삭제할 수 있다.
- std::list는 인덱스를 기반으로 한 랜덤 접근을 할 수 없고 특정 원소에 접근하려면 순차적으로 이동해야 한다.
std::forward_list
std::list와는 다르게 단순 연결 리스트로 구현된 컨테이너이다.std::forward_list를 사용하려면 헤더를 포함해야 한다.
#include <forward_list>
