파이토치(PyTorch)
파이토치(PyTorch)는 메타 AI에서 개발한 파이썬 기반의 오픈 소스 딥러닝 프레임워크이다. 현재는 메타로부터 독립하여 파이토치 재단에서 프로젝트를 관리하고 있다. 파이토치는 연구자와 개발자들 사이에서 현재 가장 인기있는 딥러닝 프레임워크이며 대표적인 특징은 다음과 같다.
- 동적 계산 그래프(dynamic computational graph): 파이토치는 계산 그래프를 동적으로 생성한다. 이는 코드 실행 중에 그래프가 생성된다는 의미이며 정적 계산 그래프보다 디버깅과 실험이 용이하다는 장점이 있다.
- 쉽고 직관적인 인터페이스: 파이토치는 파이썬과 유사한 문법을 제공하여 파이써닉한 코딩을 하기 쉽다.
- 강력한 커뮤니티 및 생태계: 파이토치를 지원하는 다양한 오픈 소스 프로젝트와 도구들이 있다.
- 하드웨어 가속 지원: 엔비디아의 CUDA를 지원하며 GPU나 TPU 같은 하드웨어를 활용하여 연산 속도를 대폭 향상시킬 수 있다.
파이토치(PyTorch) vs 텐서플로우(Tensorflow)
대표적인 파이썬 기반 딥러닝 프레임워크로는 파이토치와 텐서플로우(Tensorflow)가 있다. 텐서플로우(TensorFlow)는 구글 브레인 팀에서 개발한 오픈 소스 딥러닝 프레임워크로, 연구 및 프로덕션 환경 모두에서 널리 사용된다. 텐서플로우와 파이토치는 각각의 장단점이 있으며, 용도와 사용자의 선호에 따라 선택할 수 있지만 최근엔 대체로 파이토치의 점유율이 더 높다. 두 프레임워크의 주요 차이점은 다음과 같다.
계산 그래프
- 계산 그래프(computation graph)는 그래프(자료구조)의 일종으로 수학적 표현을 노드와 간선으로 나타낸 그래프이다. 머신러닝 및 딥러닝 모델의 연산 과정을 시각적으로 이해하고 효율적으로 계산하기 위해 계산 그래프가 사용된다.
- 파이토치는 동적 계산 그래프를 사용하여 코드 실행 중에 그래프가 생성되고 변경될 수 있다. 이는 디버깅과 실험을 용이하게 한다.
- 텐서플로우는 기본적으로 컴파일 타임에 한 번 정의하고 이후 실행하는 정적 계산 그래프(static computational graph)를 사용하지만 최근 버전에서는 동적 계산 그래프도 지원하고 있다. 정적 그래프는 모델 최적화와 배포에 유리하다.
사용자 인터페이스
- 파이토치는 파이썬에 익숙한 사용자에게 직관적이고 사용하기 쉽다. 파이써닉한 문법을 제공하여 코딩과 디버깅이 간편하다.
- 텐서플로우는 과거 버전 1.x에선 다소 복잡하고 직관적이지 않은 인터페이스로 인해 사용자들이 어려움을 겪었지만, 버전 2.x부터는 비교적 쉬운 케라스(Keras) 인터페이스를 기본으로 채택하여 사용자 친화적으로 개선되었으며 파이토치와 매우 비슷한 방식으로 코딩할 수 있게 되었다.
성능 및 최적화
- 파이토치는 동적 그래프 덕분에 디버깅이 쉽고, 실험적인 모델링에 적합하지만, 일부 상황에서는 정적 그래프보다 최적화가 불리할 수 있다.
- 텐서플로우는 정적 그래프 방식으로 컴파일 타임 최적화를 통해 더 높은 성능을 제공할 수 있으며, 배포를 위한 TensorFlow Lite, TensorFlow Serving과 같은 도구를 제공하다.
파이토치의 대략적인 작업흐름(workflow)
파이토치로 모델을 만들고 학습하고 추론하며 최종적으로 모델을 파일로 저장하는 전체적인 작업의 흐름은 다음과 같다.
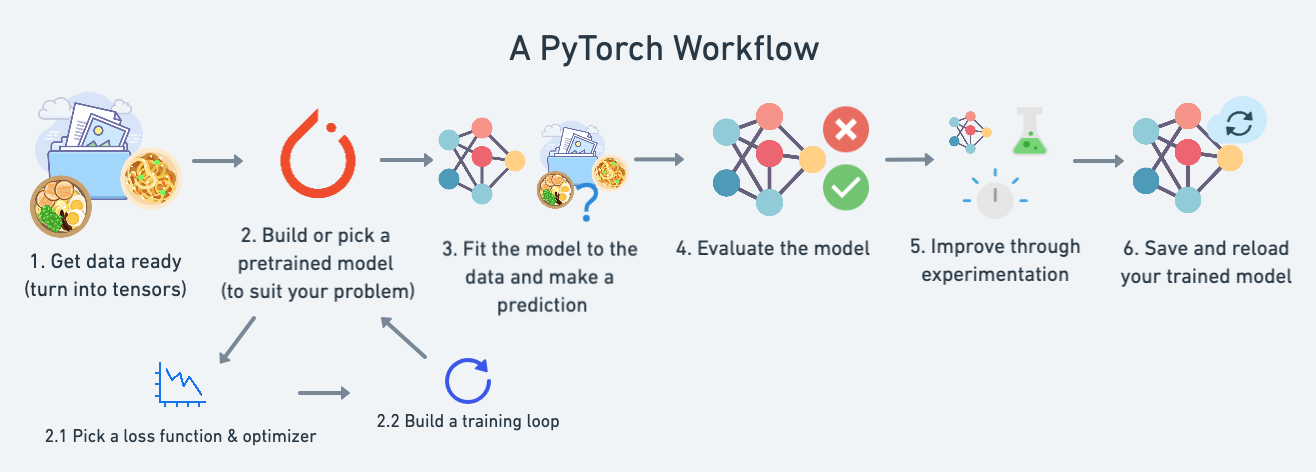
같은 간단한 선형회귀 문제를 학습하는 예시로 파이토치의 작업흐름을 살펴보자.
1. 데이터 준비: 데이터를 모으고, 텐서(tensor)로 변환하기
모델을 만들고 학습시키는 것도 중요하지만 그전에 먼저 학습 데이터를 준비하고 텐서로 변환해야 한다. 보통 머신러닝에서는 학습할 데이터를 텐서 형태로 변환하여 사용하기 때문이다. 텐서란 스칼라, 벡터, 행렬 등을 일반화한 개념으로, 0차 텐서는 스칼라, 1차 텐서는 벡터, 2차 텐서는 행렬, 3차 이상은 다차원 배열과 같다고 볼 수 있다. 머신러닝에선 음성, 이미지, 텍스트 같은 데이터도 결국 텐서로 변환되어 학습된다. 일반적으로 텐서는 배열과 비슷하게 동일한 자료형의 데이터를 저장하며 물리적으로 연속적인 기억공간을 할당받아 연산의 효율성이 좋고 GPU 같은 효율적인 디바이스에 할당될 수 있다.
파이토치와 텐서플로우의 기본 자료형 역시 텐서이며 텐서의 연산 방식과 코딩은 넘파이 배열과 매우 비슷하다. 또한 넘파이 배열을 텐서로 변환하거나 텐서를 넘파이 배열로 변환하여 사용할 수 있다. 파이토치에서 텐서는 입력 데이터, 모델 파라미터, 계산 수행, 중간 결과 저장 등 다용도로 활용된다.
모델 학습과 추론 연산의 대부분 텐서 간의 연산이며 텐서들의 크기(shape)가 일치하지 않으면 오류를 일으키기 때문에 항상 텐서의 크기를 고려하여 모델의 레이어를 설계해야 한다. 또한 텐서 연산을 담당하는 디바이스가 서로 다르면 연산이 되지 않고 오류를 일으키므로 항상 현재에 사용 가능한 디바이스에 텐서가 할당되어 디바이스를 일치시켜주는 것이 좋다.
파이토치에서 지원하는 디바이스 종류로는 cpu를 이용하는 'cpu'와 엔비디아의 병렬 컴퓨팅 플랫폼 CUDA를 이용하는 'cuda'가 있으며, CUDA GPU가 여러 개 있는 경우 'cuda:3'같은 방식으로 특정 디바이스를 지정할 수도 있다. 이외에도 애플의 'mps'와 구글의 'xla'등을 지원한다.
파이토치 객체의 to(device) 메서드를 통해 디바이스를 할당할 수 있으며, 디바이스를 지정하지 않으면 기본적으로 CPU로 지정된다. 텐서의 경우 .cpu()나 .cuda() 같은 메서드로 할당된 디바이스를 변경할 수 있다.
파이토치와는 다르게 matplotlib나 numpy 같은 라이브러리는 CPU에 할당된 텐서만 불러올 수 있으므로 이러한 라이브러리를 사용할 때는 디바이스를 적절하게 지정해줘야 한다.
또한 파이토치는 데이터를 처리하는 작업을 위한 Dataset과 DataLoader라는 기능을 제공한다. 이들은 데이터 불러오기, 변환, 배치 처리 등과 같은 작업을 쉽게 수행할 수 있도록 도와준다.
간단한 선형 데이터를 만드는 코드는 다음과 같다.
import torch
from torch import nn
device = 'cuda' if torch.cuda.is_available() else 'cpu' # CUDA가 사용 가능하면 'cuda', 아니면 'cpu'
weight = 0.7
bias = 0.3
start = 0
end = 1
step = 0.02
X = torch.arange(start, end, step).unsqueeze(dim=1)
y = weight * X + bias # y=0.7x+0.3
# 훈련 데이터와 테스트 데이터 분리
train_split = int(0.8 * len(X)) # 전체 데이터 중 80%는 학습, 나머지 20%는 테스트용 데이터
X_train, y_train = X[:train_split], y[:train_split]
X_test, y_test = X[train_split:], y[train_split:]2. 모델을 정의하거나 사전 학습된 모델 선택
학습 데이터가 준비됐다면 모델을 정의하거나 사전에 학습된(pre-trained) 모델을 선택한다. 여기서 다루는 문제는 간단한 선형 회귀 문제이므로 간단한 모델을 정의한다. 파이토치에서 모델을 정의할 때는 대개 torch.nn.Module을 상속받은 클래스를 사용하지만, 간단한 모델은 torch.nn.Sequential만 사용할수도 있다.
파이토치에서 제공하는 사전 학습된 모델들은 해당 도메인 패키지들(torchvision, torchaudio, torchrec 등)에서 제공하고 있으며 모델의 크기나 정확도, 파라미터의 개수 등의 정보가 공개되어 있으므로 문제에 적합한 것을 선택하여 이용하면 된다.
파이토치의 nn.Module 클래스를 상속받아 모델을 정의하면 모델을 유연하게 구성할 수 있으며 코드 가독성도 좋아 복잡한 모델을 정의할 때 좋다. 단 nn.Module 클래스를 상속받은 모델은 forward()라는 메서드를 반드시 오버라이딩해야 하며 생성자 안에서 super().__init__()으로 부모 객체를 초기화해야 한다.
일반적으로 생성자 __init__()에선 모델의 전체적인 구조를 정의하고, forward()는 입력 데이터를 받아서 원하는 출력으로 변환하는 과정을 수행한다. nn.Module을 이용하여 모델을 구성하는 예시 코드는 다음과 같다.
class LinearRegressionModel(nn.Module):
def __init__(self):
super().__init__()
self.weights = nn.Parameter(torch.randn(1, requires_grad=True, dtype=torch.float))
self.bias = nn.Parameter(torch.randn(1, requires_grad=True, dtype=torch.float))
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.weights * x + self.bias위의 코드는 기본 파라미터 모듈nn.Parameter을 사용하여 구성한 것이며 하나의 입력 텐서을 받아 가중치를 곱하고 편향을 더해서 하나의 텐서로 출력하는 모델이다. 선형변환 모듈 nn.Linear을 사용하면 다음과 같이 더 간단하게 만들 수 있다.
class LinearRegressionModel(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(1, 1)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.linear(x)nn.Sequential은 인수로 받은 모듈들을 순서대로 실행하고 결과를 반환한다. 활성 함수 등 다양한 신경망 유닛이 중첩되어 신경망이 깊어지고 복잡해질수록 이 모듈을 사용하는 것이 편리하다.
# torch.nn.Sequential만 사용하여 만든 간단한 모델
simple_model = nn.Sequential(
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 16),
nn.ReLU(),
nn.Linear(16, 3)
)
# 클래스 내부에서 nn.Sequential() 사용
class LinearReLUModel(nn.Module):
def __init__(self):
super().__init__()
self.layer_1 = nn.Sequential(
nn.Linear(100, 50),
nn.ReLU(),
nn.Linear(50, 30),
nn.ReLU(),
...
)
self.layer_2 = nn.Sequential(
...
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.layer_1(x)
x = self.layer_2(x)
...
return x2. 1. 손실 함수(loss function 또는 criterion)와 옵티마이저(optimizer) 정의
손실 함수는 모델이 예측한 값과 실제 값 사이의 차이를 측정하는 함수이며, 옵티마이저는 모델을 최적화하는 데 필요한 알고리즘을 의미한다. 손실함수와 옵티마이저는 모델의 매개변수 값들을 최적화하기 위해 사용된다. 딥러닝의 핵심 기법인 경사하강법(gradient descent)과 역전파(backpropagation)을 활용하려면 모델을 위한 손실 함수와 옵티마이저를 정의해야 한다.
손실 함수와 옵티마이저를 직접 만들 수도 있지만 학습에 주로 사용되는 종류들은 대부분 이미 파이토치에 구현돼있기 때문에 문제에 적합한 것을 찾아 사용할 수 있다. 파이토치에서 제공하는 손실 함수들은 torch.nn에 있고, 옵티마이저들은 torch.optim에 있다.
여기서는 간단한 회귀문제를 다루므로 손실 함수는 L1Loss와 기본적인 확률적 경사하강법(stochastic gradient descent, SGD) 옵티마이저를 사용한다.
분류 모델의 경우 일반적으로 모델이 예측한 값에 대한 오차를 계산하는 정확도 평가함수를 만들지만, 여기서는 회귀 문제 모델만 다루므로 필요없다.
loss_fn = nn.L1Loss() # L1 손실함수(평균 절대 오차, MAE)
optimizer = torch.optim.SGD(params=model_0.parameters(), lr=0.01) # 확률적 경사하강법 옵티마이저2. 2. 훈련과 테스트 루프 작성
파이토치에서 모델을 훈련시키는 코드는 일반적으로 에포크(epoch)를 정하고, 정한 에포크만큼 반복하는 방식으로 작성한다. 에포크란 전체 학습 데이터셋을 모델이 한 번 학습하는 것을 의미한다. 모델을 훈련시키기 전에 모델의 train() 메서드로 모델을 훈련 모드로 바꿔줘야 하고, 모델을 평가할 때는 모델의 eval()과 with torch.inference_mode():으로 모델의 그래디언트 추적을 해제하여 평가 모드로 전환해줘야 한다. 또한 역전파를 위해서 손실함수와 옵티마이저에서 특정 메서드를 실행해야 한다. 이를 정리한 코드는 다음과 같다.
torch.manual_seed(42)
model_0 = LinearRegressionModel() # 모델 인스턴스 생성
epochs = 200 # 훈련의 반복 횟수, 에포크는 또한 모델의 하이퍼파라미터임
epoch_count = []
loss_values = []
test_loss_values = []
for epoch in range(1, epochs + 1):
model_0.train() # 모델의 train()으로 모델을 훈련 모드로 전환
# 모델 신경망의 전방향 진행(forward pass)
y_pred = model_0(X_train) # X_train에 대해 모델의 forward() 메서드가 실행되어 예측값들이 계산됨
loss = loss_fn(y_pred, y_train) # 예측값과 실제값을 비교하여 손실 함수값들이 계산됨
# print("Loss: ", loss)
optimizer.zero_grad() # 역전파를 수행하기 전에 반드시 그래디언트 값들을 0으로 초기화 해줘야 함
loss.backward() # 손실함수의 역전파 수행, requires_grad=True인 모든 파라미터에 대해 계산함
optimizer.step() # 위의 backward()로 계산된 그래디언트로 경사하강 수행(파라미터 값들을 업데이트)
# 모델의 eval()로 모델을 테스트 모드로 전환
model_0.eval()
with torch.inference_mode(): # inference_mode()은 모델의 그래디언트 추적을 해제하며 주로 모델을 테스트하거나 추론할 때 사용함
test_pred = model_0(X_test)
test_loss = loss_fn(test_pred, y_test)
if epoch % 10 == 0:
epoch_count.append(epoch)
loss_values.append(loss)
test_loss_values.append(test_loss)
print(f"Epoch: {epoch} | Loss: {loss} | Test loss: {test_loss}")
print(model_0.state_dict())3. 학습된 모델을 이용하여 추론
위에서 만든 학습 코드로 모델을 학습시키고 나면, 모델의 파라미터들이 학습된 값을 갖게 되고 이러한 파라미터들을 이용하여 새로운 데이터에 대해서도 추론할 수 있게 된다. 모델로 추론을 하기 위해선 위에서 테스트하는 부분의 코드와 마찬가지로 모델을 eval() 모드로 전환시키고 with torch.inference_mode():으로 추론 모드에 진입하는 컨텍스트 매니저를 사용한다.
X_new = torch.randn(1)
model_0.eval()
with torch.inference_mode():
y_preds_new = model_0(X_new)
print(y_preds_new)4. 모델 평가
모델의 훈련이 완료된 후에는 모델이 새로운 데이터에 얼마나 잘 일반화되는지를 평가할 수 있으며, 이 과정에서 모델의 현재 상태를 파악할 수 있다. 모델 평가를 위해서는 일반적으로 테스트 데이터셋을 사용한다. 테스트 데이터셋은 모델이 학습하지 않은 데이터로, 모델의 예측 성능을 측정하는 데 사용된다. 이러한 평가 과정을 통해 모델의 정확도(accuracy), 정밀도(precision), 재현율(recall), F1 점수(F1-score) 등 다양한 성능 지표를 확인하며 다양한 시각화 도구들을 이용하여 모델의 성능을 시각적으로 표현하고 분석할 수 있다.
파이토치 또한 자체적인 평가 기능들을 제공하지만 평가지표를 편리하게 생성해주는 외부 라이브러리를 이용할 수도 있다. 대표적인 평가 라이브러리로는 torchmetrics가 있으며 Tenserboard같은 시각화 툴도 사용할 수 있다.
평가를 수행할 때는 모델을 eval() 모드로 전환하여 드롭아웃(dropout)이나 배치 정규화(batch normalization) 같은 레이어가 학습 시와는 다르게 동작하도록 한다.
5. 실험을 통해 모델 개선
모델의 성능을 향상시키기 위해서는 다양한 실험을 통해 개선하는 과정이 필요하다. 이러한 실험은 하이퍼파라미터 튜닝, 데이터 증강, 모델 아키텍처 변경 등 여러 가지 방법이 있다.
- 하이퍼파라미터 튜닝
하이퍼파라미터는 모델 학습 과정에서 데이터와 관계없이 직접 설정해줘야하는 매개변수들이다. 딥러닝에선 학습률, 배치 크기, 에포크 수 등이 대표적인 하이퍼파라미터이다. 하이퍼파라미터 최적화는 실험을 통해 모델의 성능을 극대화하는 중요한 과정이다.
learning_rates = [0.1, 0.01, 0.001]
for lr in learning_rates:
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
...- 데이터 증강(data augmentation)
데이터 증강은 훈련 데이터에 작은 변형을 가하여 데이터셋의 다양성을 증가시키는 기법이다. 이를 통해 모델의 일반화 성능을 향상시킬 수 있다. 예를 들어 이미지 데이터를 다룬다면 이미지에 대해 회전, 자르기, 색상 변화 등을 적용할 수 있다.
import torchvision.transforms as transforms
transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(10),
transforms.ToTensor(),
])
train_dataset = torchvision.datasets.ImageFolder(root='path_to_data', transform=transform)- 모델 아키텍처 변경
모델의 구조를 변경하여 더 깊은 레이어를 추가하거나, 새로운 유형의 레이어를 도입함으로써 성능을 개선할 수 있다.
6. 모델을 파일로 저장하고 불러오기
모델 학습과 평가가 완료된 후에는, 모델을 파일로 저장하여 나중에 재사용하거나 배포할 수 있다. 파이토치에선 torch.save()와 torch.load() 함수를 통해 모델을 저장하고 불러오는 기능을 제공한다.
- 모델 저장하기
torch.save()는 모델의 전체 상태(모델의 구조, 파라미터 등)를 저장한다. 모델의state_dict()메서드로 모델의 파라미터 값들만 저장할 수도 있다. 모델 파일은 파이썬의 내장 모듈인pickle포맷으로 저장되며 파일의 확장자는 보통.pt또는.pth를 사용한다. 모델의 파라미터만 저장할 경우 모델 파일의 크기를 줄일 수 있지만 모델을 불러올 때 추가적인 코드가 필요하다.
# 전체 모델을 저장
torch.save(model, 'model.pth')
# 모델의 파라미터만 저장
torch.save(model.state_dict(), 'model_state_dict.pth')- 모델 불러오기
torch.load()는 파이썬pickle포맷으로 저장된 모델의 객체 파일을 역직렬화하여 불러온다. 모델의 파라미터만 저장한 파일을 불러오는 경우 먼저 불러올 모델과 동일한 모델의 인스턴스를 생성하고load_state_dict()메서드를 통해 파일을 불러와야 한다.
# 전체 모델 파일로 불러오기
model = torch.load('model.pth')
# 모델의 파라미터만 저장된 파일로 불러오기
model = LinearRegressionModel()
model.load_state_dict(torch.load('model_state_dict.pth'))