Supervised Learning vs Unsupervised Learning
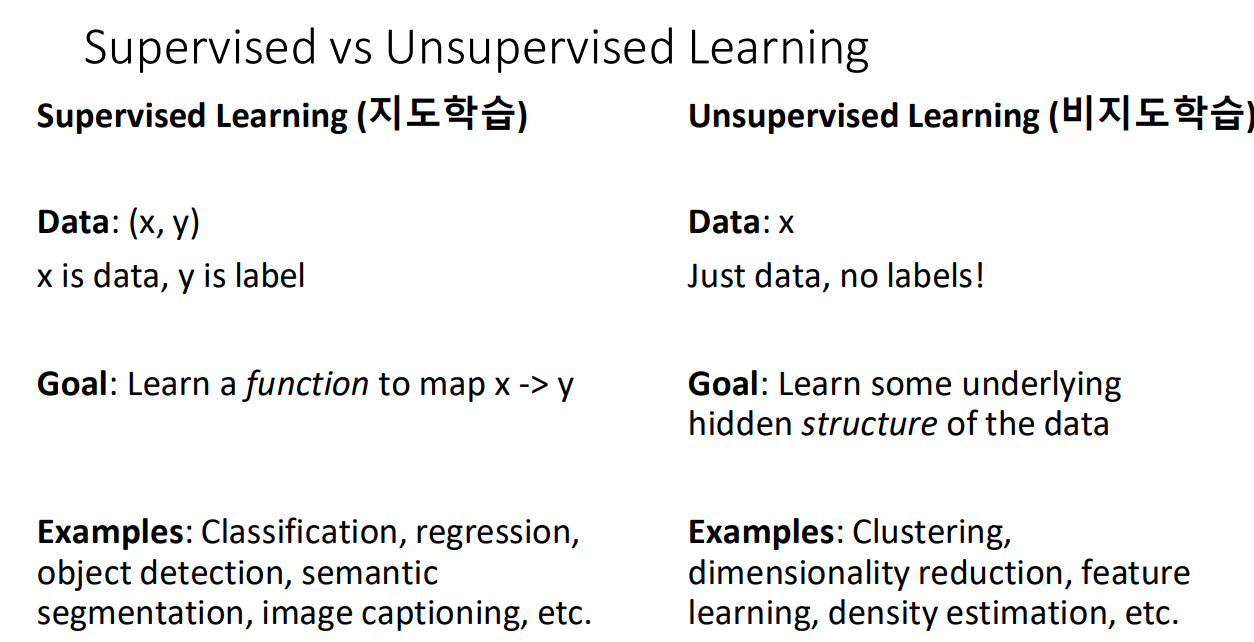
지도학습과 비지도학습의 차이는 학습 데이터의 라벨 유무이다.
data를 labeling하는 비용이 너무 비싸기 때문에 label없이 효율적인 학습을 할 수 있는 구조를 고안하고자
Self-supervised learnging을 시도했다.
Self-supervised Learning
자기지도학습은 크게 2가지로 나뉜다.
Pretext + Transfer
먼저 label이 없는 data를 통해 encoder-decoder 구조를 학습한다.
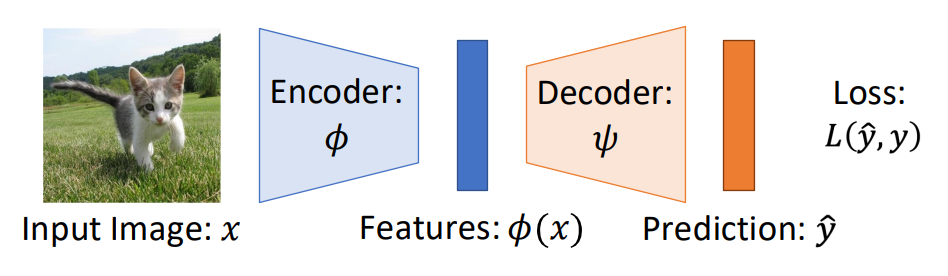
Encoder로 추출한 특징을 가지고 다시 decoder에 넣었을 때 정보의 손실을 최소화 하도록 학습시킨다.

이후 잘 학습된 Encoder를 Downstream task에 이용하도록 전이학습을 한다.
Pretext tasks
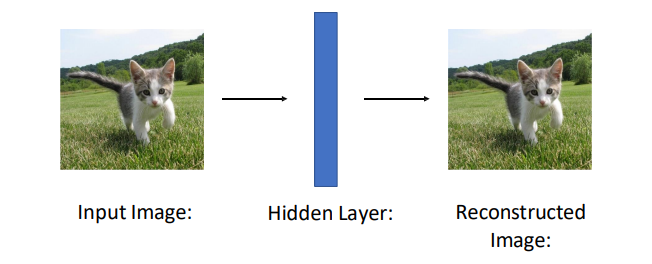
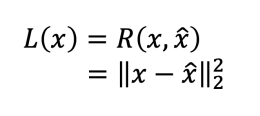
Autoencoder 모델은 Input image를 인코딩 하고 그 정보로 원래 이미지를 복원하는 방법이다.
원래 이미지를 복원할 수 있다면 인코딩을 잘 했다는 의미에서 시작된다.
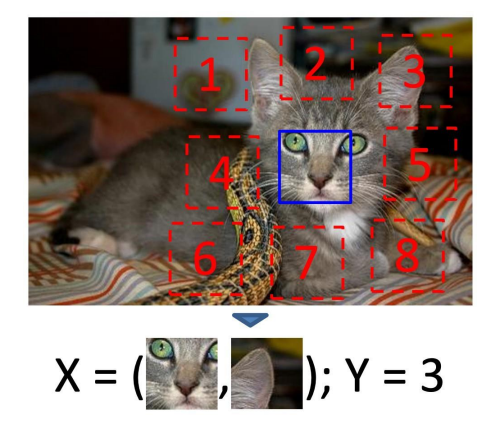
Context Prediction은 가운데 패치와 주변 패치를 입력으로 어디에 들어갈 지를 예측하는 모델이다.
패치의 위치정보에 대한 이해도를 높이기 위한 방법이다.
그 외에도 Inpainting, Jigsaw Puzzle, Colorization 등 다양한 task들로 Encoder를 만드는 자기지도 학습 방법이 존재한다.
Invariance to Data Augmentation

또한 데이터 증강에 대한 불변성을 가지기 위해 사용하는 학습 방법이 있는데

어떤 patch에서 생겨난 patch 인지 예측하는 모델이다.
다만 이러한 N-way 분류 문제는 N 갯수에 따라 네트워크를 계속 만들어야하는 단점이 있다.
여기에서 등장한 학습 방법이 대조학습이다.
Contrastive Learning

대조학습은 같은 class의 이미지는 similar, 다르면 dissimilar로 구분하여
similar이미지는 가깝게, dissimilar 이미지는 멀게 학습한다.
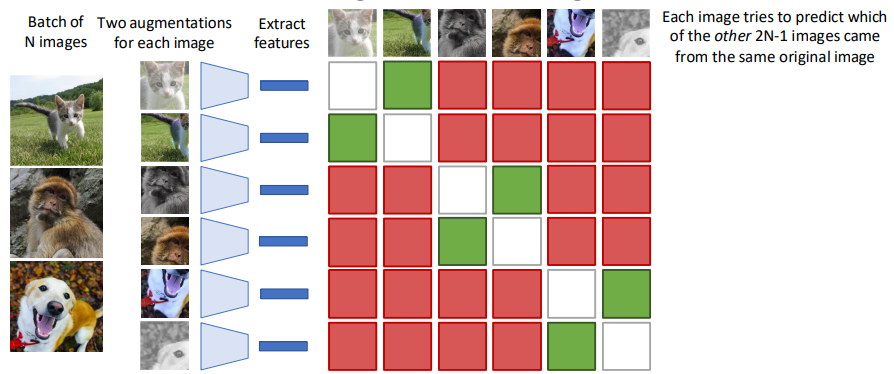
어떤 데이터 셋이던 N개의 이미지를 가진 배치 단위로 수행하여 입력의 수에는 문제가 없다.
각 이미지별로 두 개의 증강 이미지를 만들고, 증강 이미지별로 자기 자신을 제외한 2N-1개에서
similar 이미지를 찾아내는 학습 방법이다.
이러한 방식은 자기지도학습의 성능을 크게 끌어 올렸다.
CLIP
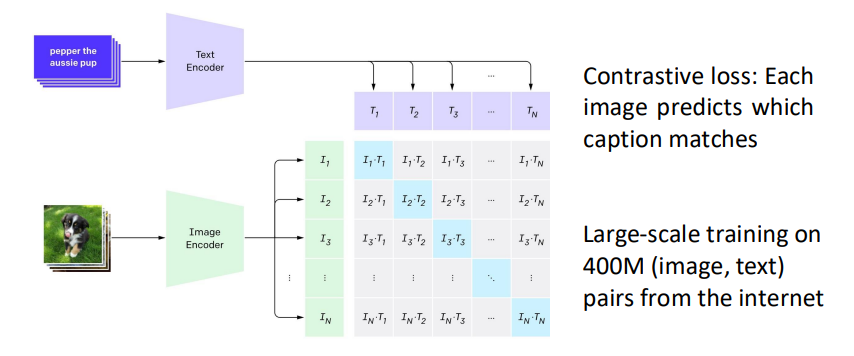
대조학습의 개념을 통해 멀티모달에서 자주 쓰이는 CLIP 모델도 존재한다.
웹 상에서 이미지와 근처 글씨를 크롤링하여 similar pair로 만들어서 학습한다.
물론 이미지에 대한 설명이 아닐 수 있지만 방대한 양의 자료를 통해
outlier의 영향력을 줄였다.
