
이번 요구사항은 다음과 같다.
- OpenAI Whisper 설치하기
✔ Whisper 💬
출처: https://github.com/openai/whisper
Whisper는 OpenAI가 개발한 자동 음성 인식(ASR) 다목적 음성 인식 모델 입니다. 이 모델은 대규모와 다양한 오디오 데이터셋을 기반으로 훈련되었으며, 다양한 언어와 방언을 인식할 수 있습니다. Whisper는 다국어 음성 인식, 음성 번역, 언어 식별 등의 다양한 작업을 수행할 수 있는 멀티태스킹 모델입니다.
Whisper의 접근 방식
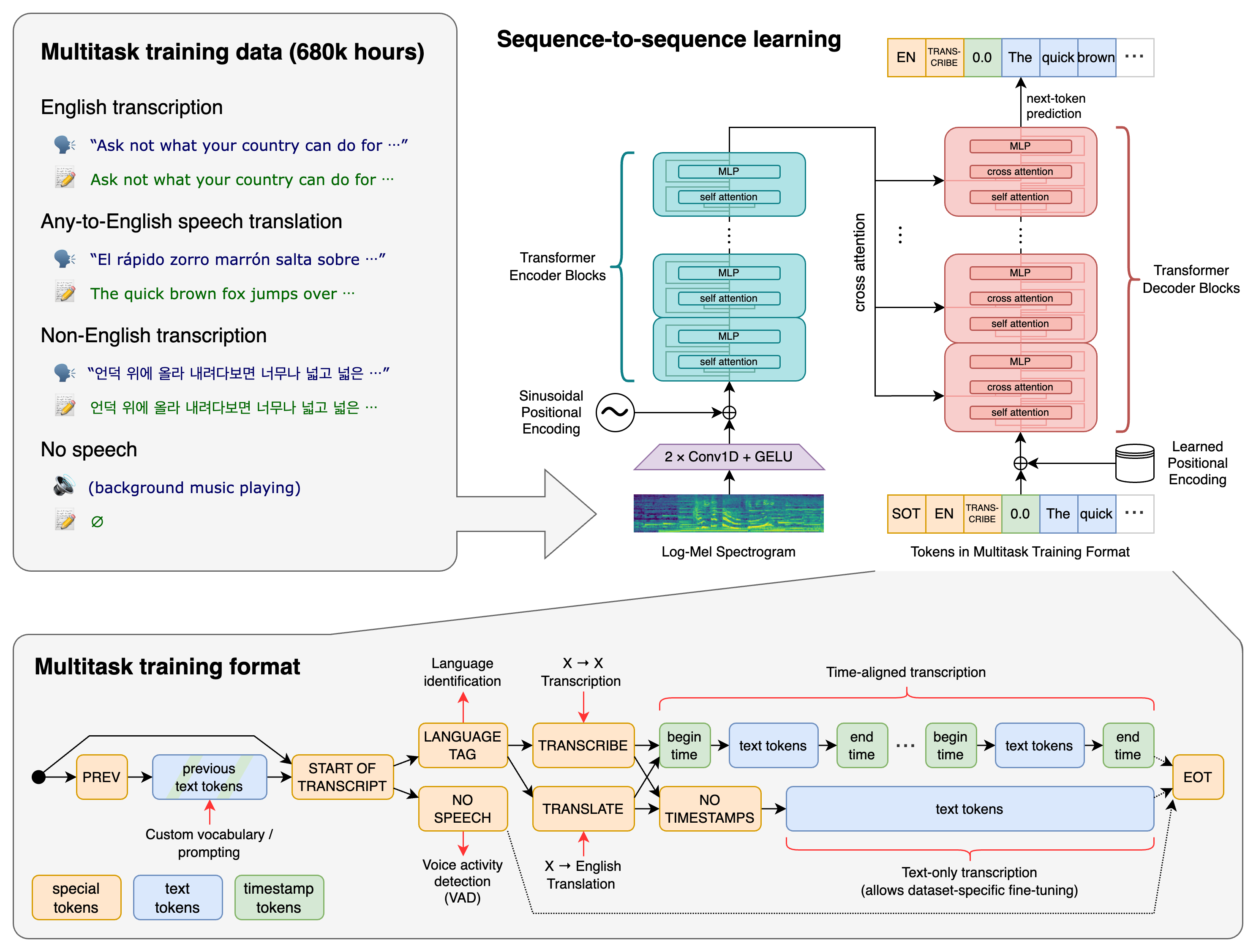
트랜스포머 기반의 sequence-to-sequence 모델을 사용합니다. 다국어 음성 인식, 음성 번역, 구어 언어 식별, 음성 활동 감지 등 여러 음성 처리 작업에 대해 훈련됩니다. 이러한 작업들은 디코더가 예측할 토큰 시퀀스로 공동으로 표현되어, 전통적인 음성 처리 파이프라인의 여러 단계를 하나의 모델로 대체할 수 있습니다.
설치 및 설정
-
Python 3.8-3.11과 최신 버전의 PyTorch와 호환됩니다. -
설치 명령어는
pip install -U openai-whisper입니다. Python 패키지 관리자인 pip를 사용하여 Whisper 모델을 설치합니다. -
시스템에
ffmpeg명령줄 도구가 설치되어 있어야 합니다. -
rust가 필요할 수도 있으며,setuptools-rust를 설치해야 할 수도 있습니다. -
최신 버전으로 강제 업데이트
pip install --upgrade --no-deps --force-reinstall git+https://github.com/openai/whisper.git
사용 가능한 모델 및 언어
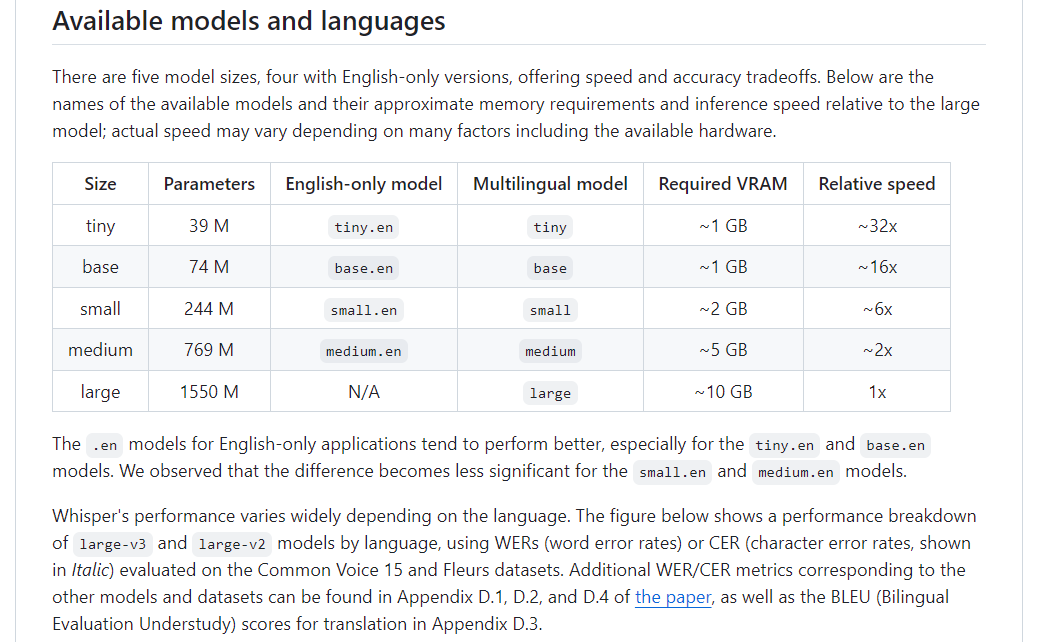
- 5가지 모델 크기(
tiny,base,small,medium,large)가 있으며, 각각 속도와 정확도 측면에서 차이가 있습니다. - 영어 전용 모델과 다국어 모델이 제공됩니다. 모델의 성능은 언어에 따라 다양하게 나타납니다.
명령줄 사용법
-
기본 음성 인식 명령어로, Whisper 모델을 사용하여 지정된 오디오 파일들을 텍스트로 변환합니다.
whisper audio.flac audio.mp3 audio.wav --model medium -
특정 언어 지정 명령어 예시
whisper japanese.wav --language Japanese -
음성 번역 명령어 예시로, 지정된 언어의 오디오를 영어로 번역합니다.
whisper japanese.wav --language Japanese --task translate -
도움말
whisper --help -
오디오 파일을 텍스트로 변환하는 명령어 예시:
whisper audio.flac --model medium -
특정 언어를 지정하여 사용하는 방법과 번역하는 방법도 제공됩니다.
Python에서의 사용
-
Python 내에서도 모델을 불러오고 오디오 파일을 텍스트로 변환할 수 있습니다.
-
예시 코드와 함께 whisper.detect_language() 및 whisper.decode() 함수를 사용하는 방법도 제공됩니다.
라이선스
- Whisper의 코드와 모델 가중치는 MIT 라이선스 하에 공개되어 있습니다. 이 정보들은 Whisper의 기능, 설치 및 사용 방법, 그리고 지원하는 모델 및 언어에 대한 중요한 세부 사항을 포함합니다.
✔ 코드 예시
아래 코드 예시는 Whisper 모델을 사용하여 특정 언어를 감지하고, 오디오를 텍스트로 변환하는 데 사용됩니다. 이는 오디오 파일의 언어를 사전에 알지 못하는 경우 유용할 수 있습니다.
transcribe() 메소드
- 오디오 파일을 30초 길이의 작은 부분(윈도우)으로 나누어 처리합니다. 이는 마치 긴 테이프를 30초짜리 구간으로 나누어 듣는 것과 비슷합니다. 각 30초짜리 윈도우에서, 모델은 오디오 데이터를 텍스트로 변환하기 위해 '자동 회귀 시퀀스-투-시퀀스 예측'을 수행합니다.
- 이는 오디오의 각 부분을 순차적으로 분석하여 해당하는 텍스트를 생성하는 과정입니다. 각 윈도우가 처리될 때, 모델은 이전 윈도우에서 얻은 정보를 바탕으로 다음 윈도우의 음성을 텍스트로 변환하는 데 도움을 받습니다.
- 간단히 말해,
transcribe()메소드는 오디오 파일을 작은 부분으로 나누고, 각 부분을 차례로 분석하여 전체 오디오 파일의 음성을 텍스트로 변환하는 역할을 합니다.
오디오의 log_mel_spectrogram?
- 로그 멜 스펙트로그램 생성: 이 단계는 오디오 파일을 시각적으로 분석 가능한 형태로 변환하는 과정입니다.
- 멜 스펙트로그램: 오디오 신호를 주파수 구성 요소로 분해하고, 이를 멜 척도(인간의 귀가 인지하는 척도)에 따라 시각화합니다. 멜 스펙트로그램은 오디오의 특성(예: 음성의 피치, 강도 등)을 시각적으로 표현합니다.
- 로그 변환: 멜 스펙트로그램에 로그 변환을 적용함으로써, 오디오 데이터의 다이나믹 레인지를 줄이고, 인간의 청각에 더 가깝게 데이터를 나타냅니다. 이는 모델이 데이터를 더 잘 처리하도록 도와줍니다.
- 모델이 있는 같은 디바이스로 이동: 이는 멜 스펙트로그램 데이터를 모델이 작동 중인 컴퓨터의 '디바이스'(예: CPU 또는 GPU)로 전송하는 과정을 의미합니다.
만약 모델이 GPU에서 실행되고 있다면, 멜 스펙트로그램 데이터도 GPU로 이동시켜, 모델이 데이터를 효율적으로 처리할 수 있도록 합니다. 반대로 모델이 CPU에서 실행되고 있다면, 데이터는 CPU로 이동합니다.
간단히 말해, 이 문장은 오디오 파일을 모델이 처리하기 좋은 형태로 변환하고, 그 데이터를 모델이 있는 곳(예: GPU나 CPU)으로 옮겨서 모델이 효율적으로 작업을 수행할 수 있도록 하는 과정을 설명합니다.
# Whisper 라이브러리를 불러옵니다
import whisper
# "audio.mp3" 오디오 파일을 로드. "base" 크기의 Whisper 모델을 메모리에 로드합니다.
model = whisper.load_model("base")
# 모델의 transcribe() 메소드를 사용하여 "audio.mp3" 파일을 음성 인식하여 텍스트로 변환합니다.
# 이 메소드는 전체 파일을 읽고 30초 길이의 윈도우를 이동시키며 오디오를 처리합니다.
# 각 윈도우에서 자동 회귀 시퀀스-투-시퀀스 예측을 수행합니다.
result = model.transcribe("audio.mp3")
print(result["text"])
# 오디오를 30초 길이에 맞게 패딩하거나 자릅니다
audio = whisper.load_audio("audio.mp3")
audio = whisper.pad_or_trim(audio)
# 오디오의 로그 멜 스펙트로그램을 생성하고 모델이 있는 같은 디바이스로 이동합니다
mel = whisper.log_mel_spectrogram(audio).to(model.device)
# detect_language() 메소드를 사용하여 말해진 언어를 감지합니다
_, probs = model.detect_language(mel)
# 감지된 언어를 출력합니다
print(f"Detected language: {max(probs, key=probs.get)}")
# 디코딩 옵션을 설정합니다
options = whisper.DecodingOptions()
# decode() 메소드를 사용하여 오디오를 텍스트로 디코딩합니다
result = whisper.decode(model, mel, options)
# print the recognized text
print(result.text)✔ 설치 과정
이를 위해 MacOS에서 개발하고 있다가, Windows로 옮겨왔다. 그리고 Pyhthon3.9 가상환경을 준비해야 했다. 다시 처음부터 MongoDB 등 개발 환경을 설치하고 설치 오류를 해결했는데 생각보다 시간이 적게 걸렸다. 이전에 해봐서 그런가보다 싶었다. 환경 정리가 끝났다면 이제 Whisper 를 설치할 준비를 해줄 때가 왔다는 것!
다음은 PyTorch를 설치할 차례다. Start Locally 에 들어간다. 셋팅을 해주는데, 여기서는 Stable, Windows, Python, CUDA 11.7로 셋팅 후 pip3 명령어를 실행해서 설치한다. (CUDA는 Nvidia 그래픽 카드를 사용하는 경우)

pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118이 명령어를 실행해준다. 2기가가 넘는 용량이라 조금 시간이 걸린다. 설치 후에 pip list로 확인해보면 torch, torchaudio 등의 패키지가 설치된 것을 볼 수 있다.
다음은 동영상 처리 라이브러리인 FFmpeg을 설치해야 한다. FFmpeg는 비디오, 오디오 등의 멀티미디어 파일을 처리할 수 있는 프로그램이다. 이 프로그램으로 할 수 있는게 너무 많아서 공식 웹사이트의 설명에는 '오디오와 비디오를 기록하고(record), 변환하고(convert), 스트리밍(stream)하는 완전한 크로스 플랫폼 솔루션이다' 라고 한다.
PowerShell 에서 윈도우 패키지 매니저 Scoop 을 사용해서 FFmpeg 를 설치해본다. 이것도 시간이 좀 걸린다! 설치가 완료되고
설치가 완료되고 ffmpeg -version 명령을 통해 아래처럼 정보를 확인할 수 있다.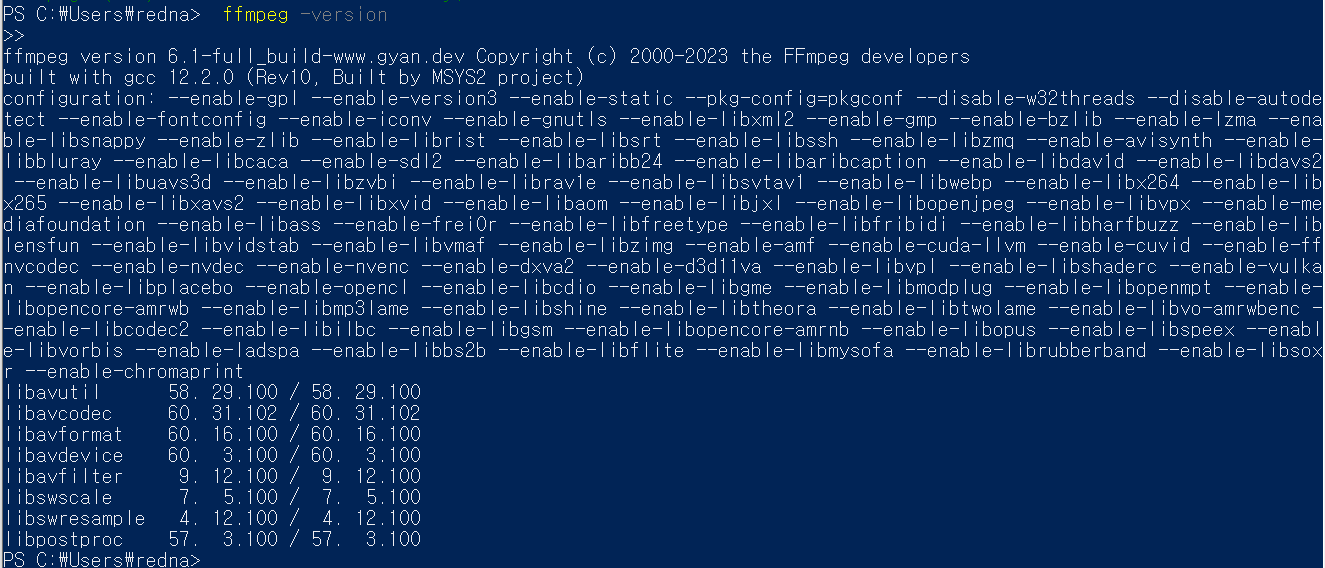
ffmpeg -encoders 명령으로 사용가능한 코덱을 출력합니다. -endcoders 가 엔코더이고 -decoders가 디코더입니다. 엔코딩은 파일을 코딩(암호화)시키는 기능이고 디코딩은 암호화된 파일을 푸는 기능입니다. 출력해보면 상당히 많은 종류의 엔코더와 디코더가 들어있습니다. 인터넷이 발전 과정에서 많이 사용되었던 웬만한 포맷들은 대략 다 들어 있는데요. 코덱은 특허가 있기 때문에 유료 코덱을 이용한 동영상의 변환 등을 할 때는 라이센스에 대해 체크하도록 주의합니다. 
그 다음으로 Whisper 를 설치해준다.
pip3 install setuptools-rust
pip3 install git+https://github.com/openai/whisper.gitCUDA 드라이버가 없다면 설치하도록 합니다. nvidia-smi 명령어로 CUDA드라이버 버전을 체크할 수 있습니다.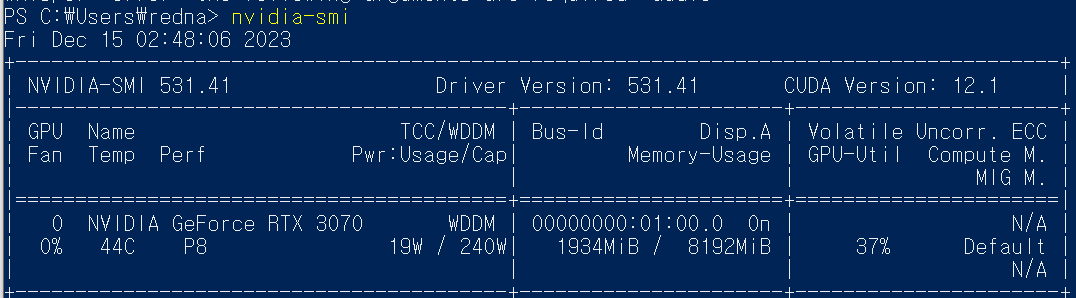
✔ 간단한 테스트
한글 m4a 테스트로 써본 영상은 내가 좋아하는 유튜버 율리님의 숏츠 영상 이다. 자막 데이터가 대략 97%는 정확한 걸 확인할 수 있다.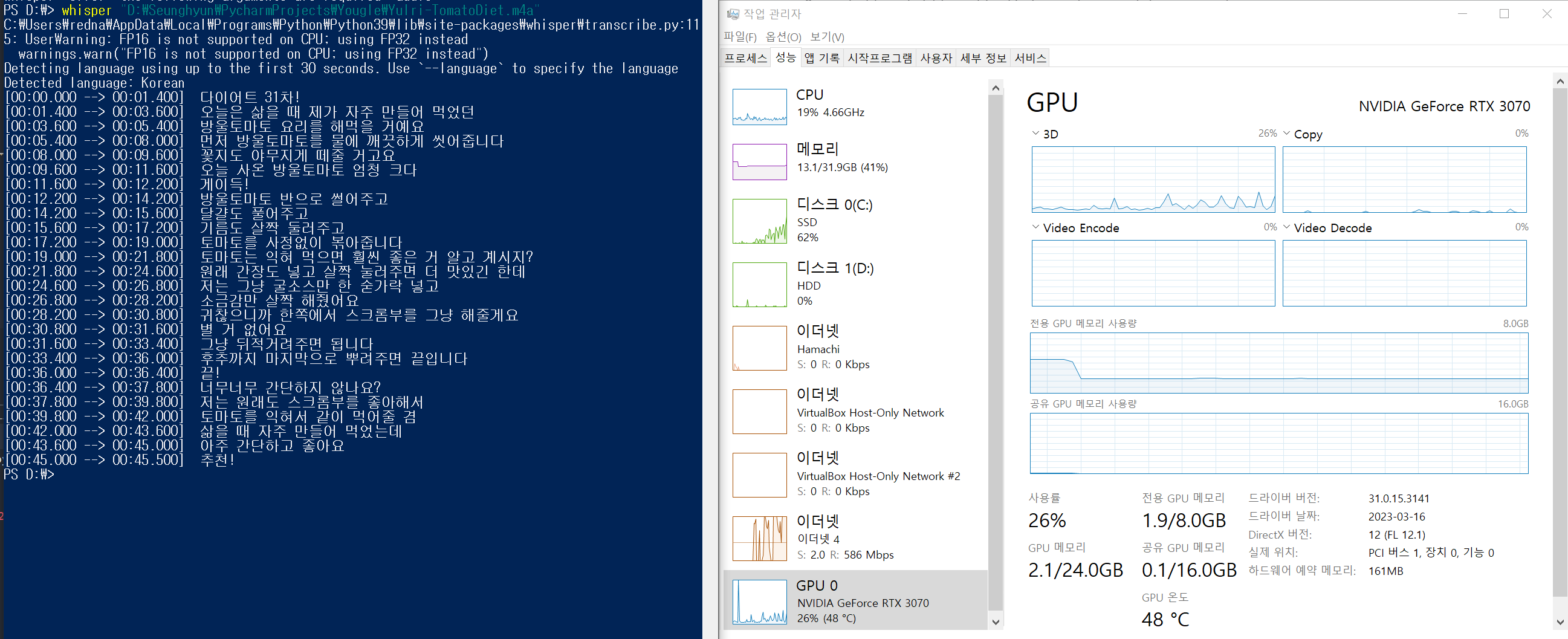
다음으로 영어 m4a 테스트로 써본 영상은 CNN 숏츠 영상이다. 영상에 삽입된 자막과 비교해보면, 100% 일치하는 것을 확인할 수 있었다. (진짜 멋지다 위스퍼..!) 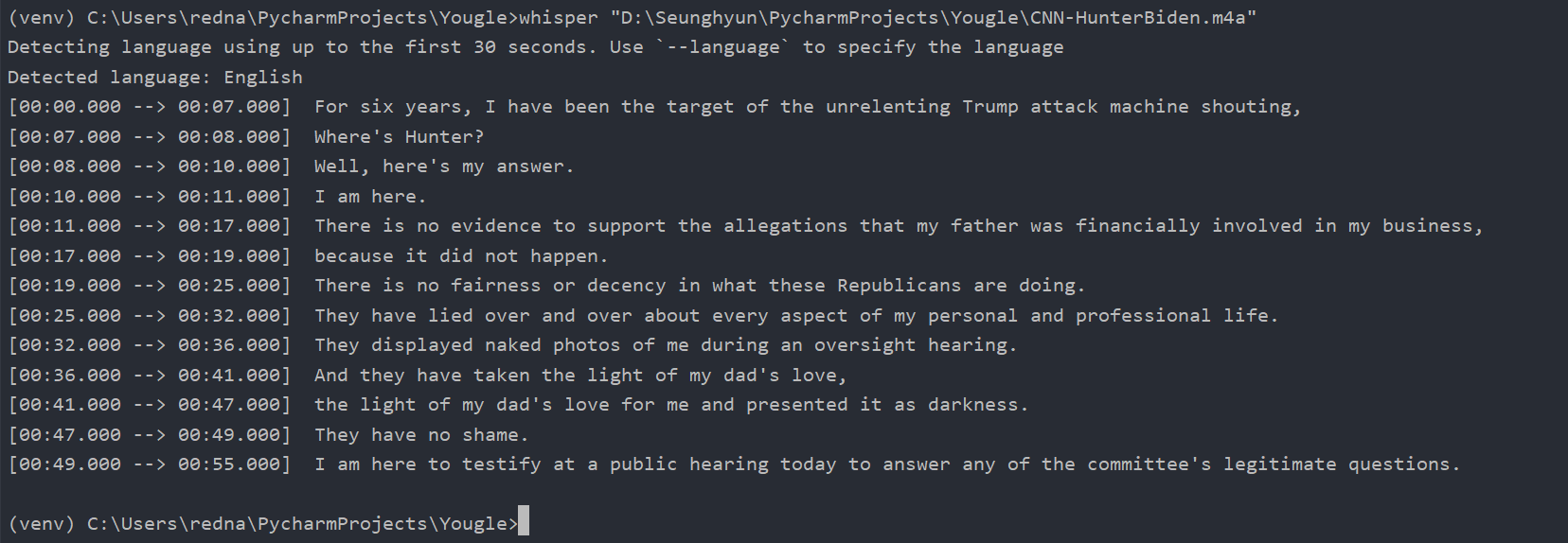
✔ 후기 🙌
Whisper 가 잘 설치되었으면 파이썬에서 사용하는 것은 어렵지 않다. 로컬에서 돌리니 API 키 같은 것은 당연히 필요없겠다. 모델만 선택해서 (tiny~large) 오디오 파일을 입력하면 된다. 코드를 사용하면 더 많은 일을 시킬 수 있다. Real Time Speech To Text, Real Time Translation 등 잘 찾아보면 깃허브에 소스코드가 있다. 벌써 Whisper 로 상용 프로그램을 제작하는 개발사도 있다. 그런 필요한 기능들을 돈을 주고 사는 것 보다 직접 만들 수 있으면 좋겠다. 예전에는 상상도 하지 못했는데 Whisper 가 오픈소스로 풀려서 이걸로 많은 일을 할 수 있게 되었다.
