Yougle
1.[Python] 프로젝트 소개 & 유튜브 자막 다운 📌

프로젝트 소개 및 자막 데이터를 JSON 파일로 저장
2023년 12월 4일
2.[Python] 채널의 모든 링크 가져오기, YouTube Data API

유튜버의 채널 주소를 입력했을 때 모든 링크 주소를 JSON 파일로 다운로드해봅니다.
2023년 12월 5일
3.[Python] Flask 웹서버

저번 포스트에 이어서, 이번에는 웹페이지에 유튜브 채널 id를 넣으면 동영상 목록을 출력해보려 합니다.
2023년 12월 6일
4.[SQLite] Table Schema, Query

저번 포스팅까지 구현한 기능과 DB를 연동해봅니다.
2023년 12월 10일
5.[MongoDB] NoSQL Document DB

파일 시스템에 데이터를 저장하는 방식은 데이터의 무결성을 보장하기 어렵고 검색 또한 어렵습니다.
2023년 12월 13일
6.[Python] Windows 에서 OpenAI Whisper 설치하기

OpenAI가 개발한 자동 음성 인식(ASR) 다목적 음성 인식 모델 Whisper를 윈도우에서 설치해보고 간단히 테스트해봅니다.
2023년 12월 14일
7.[Python] Whisper JSON을 MongoDB에 저장

Whisper결과로 나온 JSON을 MongoDB에 저장해봅니다.
2023년 12월 15일
8.[HTML&CSS] UX Improvement (1)

사용자 경험을 개선합니다.
2023년 12월 20일
9.[HTML&CSS] UX Improvement (2)

사용자 경험을 개선합니다. 업로드 날짜 표시, 로딩 애니메이션 가운데 정렬, 마우스 금지 표시 해제, 페이지네이션, 이미 DB에 저장된 건 버튼 비활성화, 채널 이름 & 채널링크 바로가기
2023년 12월 21일
10.[JS] UX Improvement (3)

사용자 경험, 동적 인터페이스를 개선합니다.
2023년 12월 21일
11.[설계] 문장구분

이제 AI 코딩은 누구나 하는 시대가 왔다. 그러나 AI를 잘 하려면 데이터를 잘 만들어야 한다. 즉 유튜브 검색 서비스를 만들려면, 자막 정보가 문장 단위로 잘 분리되어 있어야 좋은 결과가 나온다. 물론 그냥 해도 되겠지만, 그렇다면 검색 품질이 떨어지겠지.그래서 A
2023년 12월 27일
12.[Python] 기능 구현

기능 구현을 이어서 하고, GPTs를 적용해봅니다.
2023년 12월 27일
13.프로젝트 시퀀스 1차
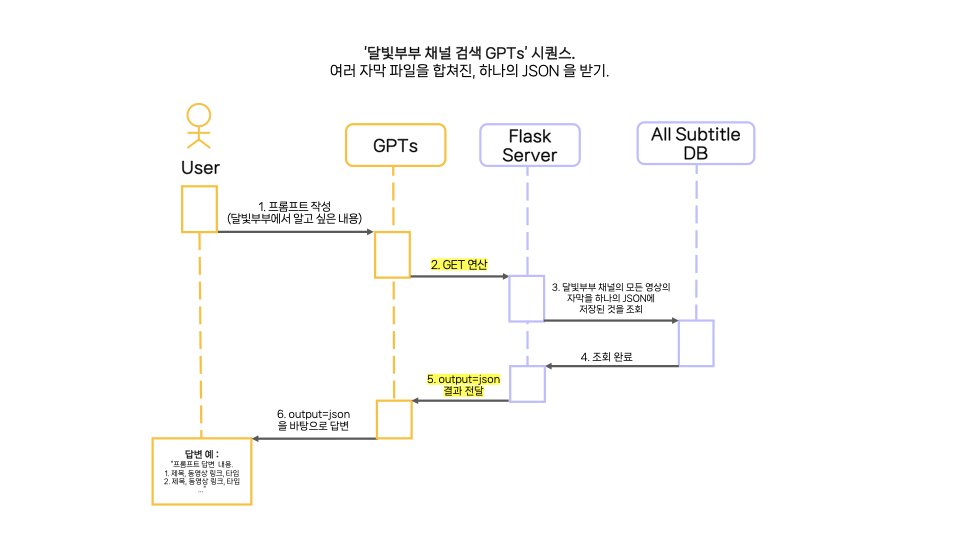
2024년 1월 6일
14.FTP, SSH, SFTP
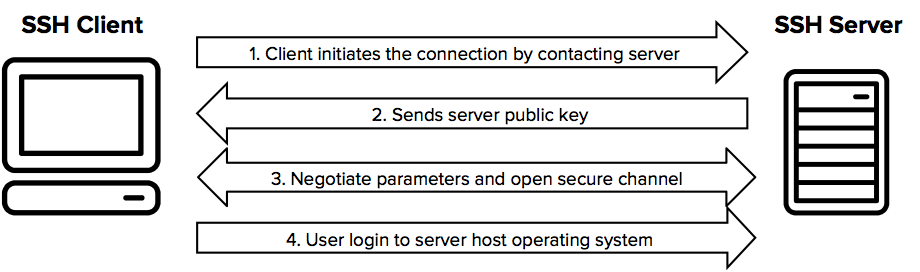
클라우드에 옮기기 전에
2024년 1월 10일
15.[Linux] 윈도우에서 Linux 가상서버 접속, FileZilla 업로드
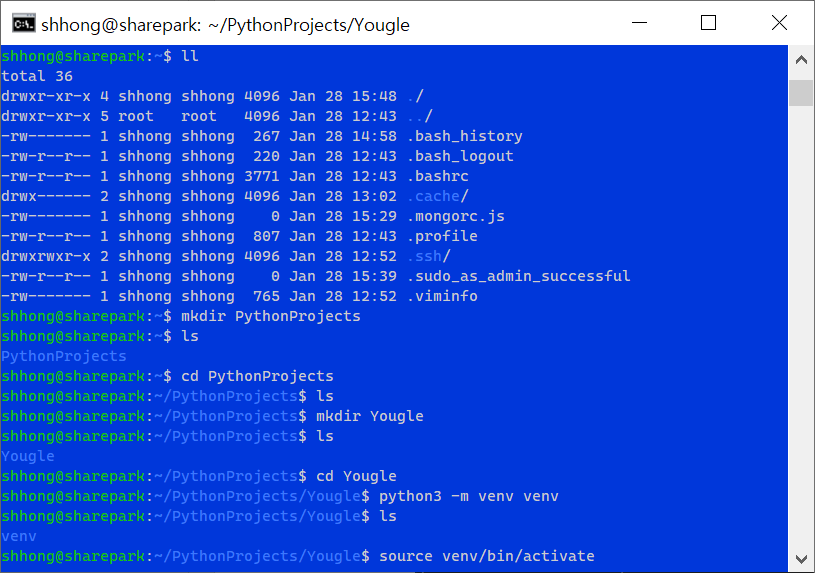
클라우드 기반의 리눅스 서버에 접근하여 작업하기 앞서, 리눅스 클라우드에 윈도우 파이썬 프로젝트 및 MongoDB 등 데이터베이스 옮기기
2024년 1월 13일