✔ 요구사항
Download Subtitle를 누르면 통합 문장을video_id_xxxxxxxx.txt로 저장하기 ✔View Downloaded버튼을 두개로 확장해서 ✔
시간별로 보기,통합으로 보기버튼으로 구별해준다. ✔- 커스텀 GPTs 가이드를 톺아보고 적용하기
- 1단계: 내가 배우고 싶은 유튜버를 찾아서 gpt로 만들면, 언제든 궁금한걸 텍스트로 물어보고 답변받고 ✔
- 2단계: 여러 영상을 올려두면, 답변해줄때 영상링크까지 알려주는 기능
✔ View Downloaded 메뉴 2개
시간별로 보기 는 View with Time 버튼을 누르면 볼 수 있다.
통합으로 보기 는 View All 버튼을 누르면 볼 수 있다.
flask 코드이다.
# 타임스탬프, 자막텍스트 보기
@app.route('/view-time-transcription/<channel_id>/<video_id>')
def view_time_transcription(channel_id, video_id):
transcription = videos_db_query.find_mongodb_trans(channel_id, video_id)
if transcription is None:
return "Transcription not found", 404
# 각 segment 의 시간을 분:초 형식으로 변환한다.
for segment in transcription['segments']:
segment['formatted_start'] = youtube_data.format_seconds_to_min_sec(segment['start'])
return render_template('transcription.html', transcription=transcription, video_id=video_id)
# 자막텍스트 통합 보기
@app.route('/view-entire-transcription/<channel_id>/<video_id>')
def view_entire_transcription(channel_id, video_id):
transcription = videos_db_query.find_mongodb_trans(channel_id, video_id)
if transcription is None:
return "Transcription not found", 404
# 전체 스크립트를 하나의 문자열로 결합
entire_transcription = " ".join(segment['text'] for segment in transcription['segments'])
transcription_data = {
'video_id': video_id,
'script': entire_transcription
}
return render_template('entire_transcription.html', transcription=transcription_data)entire_transcription.html 을 만들어주었다.
<!DOCTYPE html>
<html>
<head>
<title>Full Transcription</title>
</head>
<body>
<p>video_id: {{ transcription.video_id }}</p>
<p>script: {{ transcription.script }}</p>
</body>
</html>
video_id_xxxxxxxx.txt 로 저장하기
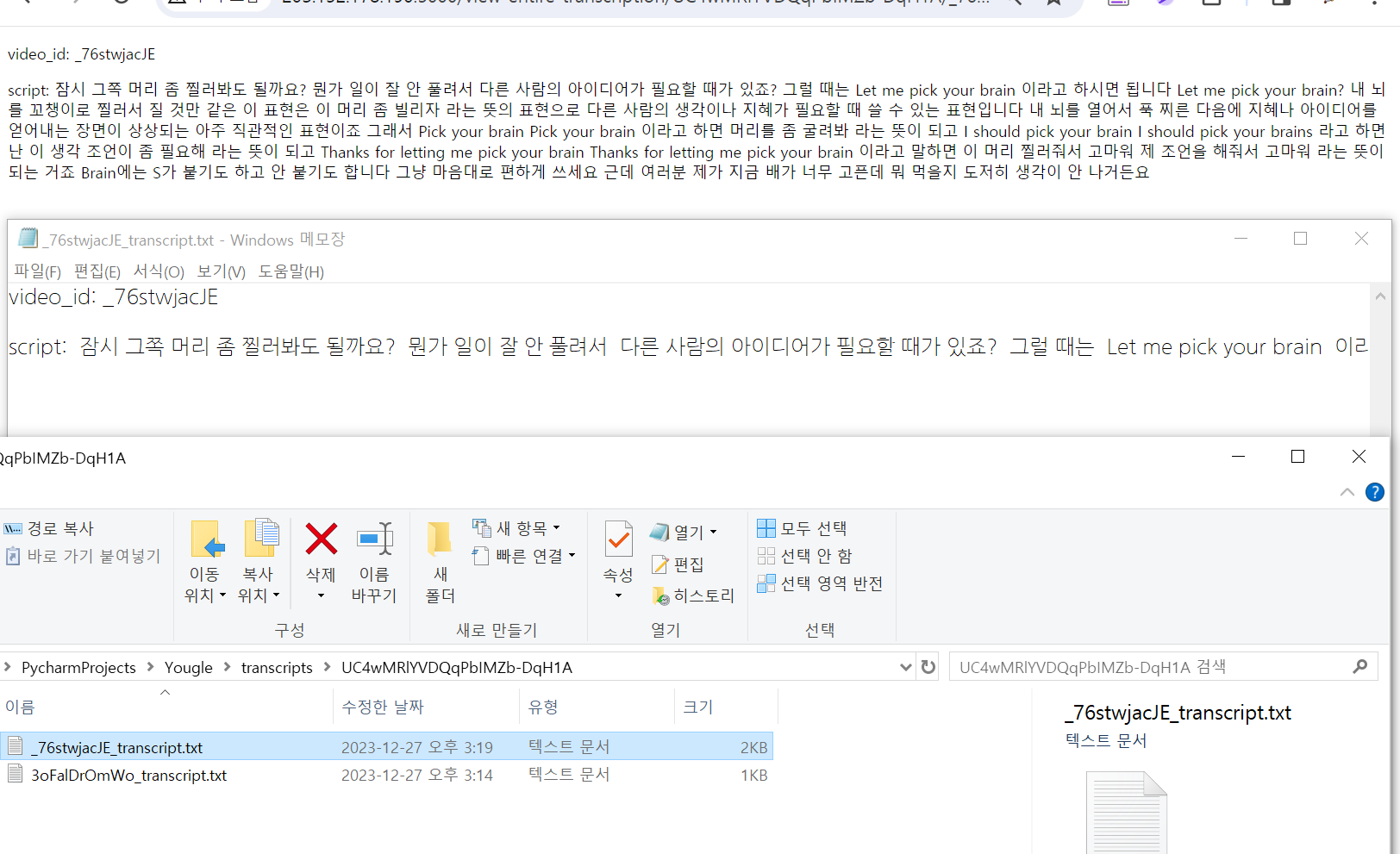
원래 있던 코드에 # 여기서부터 텍스트 파일 저장 로직 추가 부분을 추가했다.
@app.route('/download/<channel_id>/<video_id>')
def download_video(channel_id, video_id):
print("0000")
youtube = YouTube(f'https://www.youtube.com/watch?v={video_id}')
video = youtube.streams.filter(res='360p', progressive=True, file_extension='mp4').order_by('resolution').desc().first()
if not video:
return "Video not found", 404
project_root = 'C:\\Users\\redna\\PycharmProjects\\Yougle'
videos_path = os.path.join(project_root, 'videos', channel_id)
if not os.path.exists(videos_path):
os.makedirs(videos_path)
filename = f"whisper-{channel_id}-{video_id}.mp4"
mp4_path = os.path.join(videos_path, filename)
mp3_path = os.path.join(videos_path, f"whisper-{channel_id}-{video_id}.mp3")
video.download(output_path=videos_path, filename=filename)
youtube_data.convert_mp4_to_mp3(mp4_path, mp3_path)
# whisper, transcription
not_exist_json_in_mongo = videos_db_query.check_transcription_none(channel_id, video_id)
if not_exist_json_in_mongo: # 없으면 저장
transcription = whisper_trans.transcribe_audio(mp3_path)
print("transcription", transcription)
videos_db_query.upsert_mongodb_trans(channel_id, video_id, transcription)
print("app.py : upserted transcription in mongodb", channel_id, video_id, transcription)
# 여기서부터 텍스트 파일 저장 로직 추가
transcripts_path = os.path.join('C:\\Users\\redna\\PycharmProjects\\Yougle', 'transcripts', channel_id)
if not os.path.exists(transcripts_path):
os.makedirs(transcripts_path)
transcript_file_path = os.path.join(transcripts_path, f"{video_id}_transcript.txt")
with open(transcript_file_path, 'w', encoding='utf-8') as file:
file.write(f"video_id: {video_id}\n\nscript: ")
file.write(" ".join(segment['text'] for segment in transcription['segments']) + '\n')
if not not_exist_json_in_mongo: # 있으면 꺼내오기
# transcription = videos_db_query.find_mongodb_trans(channel_id, video_id)
print("app.py : transcription already exists in mongo")
return send_file(mp3_path, as_attachment=True)✔ custom-gpts 적용
1단계
내가 배우고 싶은 유튜버를 찾아서 gpt로 만들면, 언제든 궁금한걸 텍스트로 물어보고 답변받기
이제 영상 별 스크립트를 저장하는 기능까지 구현했다!
이 스크립트 txt 를 gpt에게 가르쳐서, 나만의 gpt에 물어보면, 스크립트를 기반으로 답변해 주는 것을 한 번 해보자!
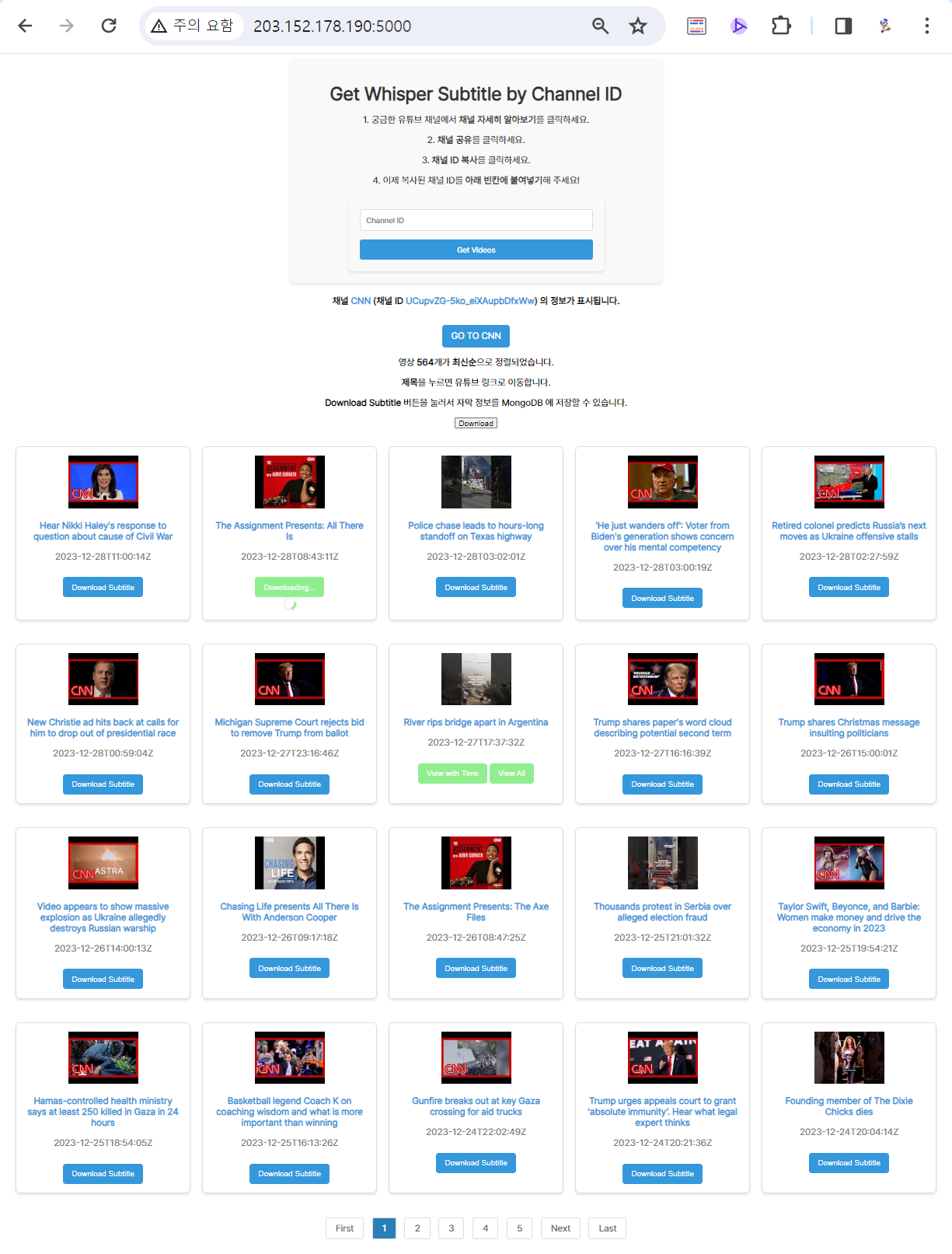
먼저... 어떤 영상을 골라야 Q&A 테스트를 하기 좋을지 고민했다. 어떤 유튜버가 테스트로 좋을까? 발음이 좋고, 대사가 적지 않으면 좋겠다. 그리고 어떤 주제가 좋을까? 단순히 구글링으로 쉽게 알 수 있는 정보가 아닌, 저작권을 침해하지 않는! 사람의 정성이 들어간, 쉽게 얻기 어려운 정보, 인간미가 담긴 정보면 좋겠다는 생각이 들었다.
고민 끝에 이 채널을 선택했다!
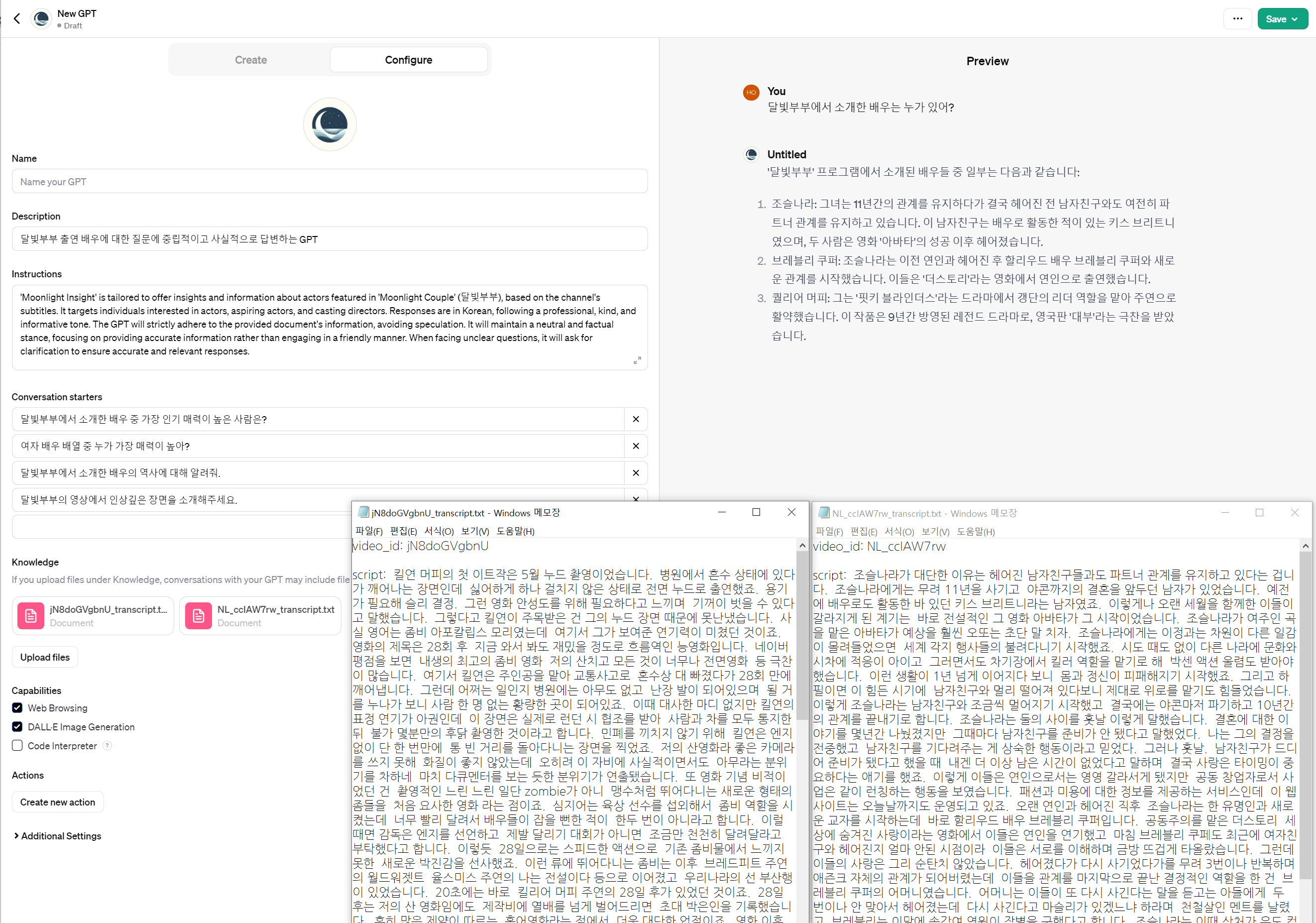
그리고 GPT의 설정을 아래와 같이 했다.
1단계 결과
업로드한 텍스트 파일은 2개이며, 오른쪽에 보이는 질문은 이 텍스트 파일을 토대로 대답한 것을 알 수 있다!!