
Thumbnail image from DALL-E
✔ 요구사항
- 테이블 설계 및 create한다.
- json 에 저장한 걸 db에도 저장하기 (둘이 같다고 보면 된다)
- 유튜브 채널을 입력할 때 검색을 하게는데,
- 먼저 db에 검색해서 db에 있으면 db에 있는거 보여주고 json도 보여주고,
- db에 없으면 조회해서 db에도 저장하고 json도 저장하고 보낸다.
SQLite
SQLite는 MySQL과 같은 오픈소스 데이터베이스 관리 시스템이지만, 서버가 아니라 응용 프로그램에 넣어 사용하는 비교적 가벼운 데이터베이스이다. 일반적인 RDBMS에 비해 대규모 작업에는 적합하지 않지만 중소 규모라면 속도에 손색이 없다.
엣지 컴퓨팅, 분산 데이터베이스, 로컬 캐싱 개념도 필요할 때 사용 가능하다. 20년전에는 구글 메일 같은 시스템에서 BDB(버클리DB)를 가지고 개인 메일함을 관리 했던 적이 있었는데, 대용량의 DB로 모든 데이터를 담는 것이 아니라 개인화된 파일DB 를 기반으로 서비스를 분산하여 만드는 것에 적합한 것으로 이해하는 것이 좋은 사례가 될 것이다.
또 API는 단순히 라이브러리를 호출하는 것만 있으며 데이터를 저장하는 데 하나의 파일만을 사용하는 것이 특징이다. 주로 C언어를 쓰는 경우가 많아 C언어의 경우만 설명하지만 Python Swift 등의 언어로도 사용가능하다.
또한 많은 언어에는 SQLite를 위한 고수준 바인딩이 라이브러리로 존재한다. 그리고 이 라이브러리를 해당 언어를 위한 다른 데이터베이스 액세스 계층과 함께 사용할 수 있다. 예를 들어 파이썬은 파이썬 인터프리터 기본 버전과 함께 SQLite 라이브러리를 표준 번들 요소로 제공한다. 또한 SQLite를 사용하는 다양한 서드파티 ORM 및 데이터 계층이 있으므로 원시 SQL 문자열(불편할 뿐만 아니라 위험하기도 함)을 통해서만 SQLite에 액세스할 필요도 없다.
SQLite는 관계형 데이터베이스 관리 시스템을 제공하는 소프트웨어 라이브러리입니다. SQLite에는 다음과 같은 기능이 있습니다.
serverless, 독립실행형, Zero-configuration, transaction
serverless
일반적으로 MySQL, PostgreSQL 등의 RDBMS는 별도의 서버 프로세스가 필요합니다. 데이터베이스 서버에 액세스하려는 응용 프로그램은 TCP/IP 프로토콜을 사용하여 요청을 보내고 받습니다. 이것을 클라이언트/서버 아키텍처라고 합니다.
다음 다이어그램은 RDBMS 클라이언트/서버 아키텍처를 보여줍니다. 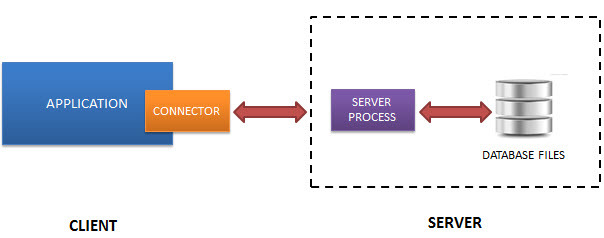
SQLite는 서버 프로세스를 실행할 필요가 없습니다. SQLite 데이터베이스는 데이터베이스에 액세스하는 애플리케이션과 통합됩니다. 응용 프로그램은 SQLite 데이터베이스와 상호 작용하여 디스크에 저장된 데이터베이스 파일에서 직접 읽고 씁니다. 다음 다이어그램은 SQLite 서버리스 아키텍처를 보여줍니다.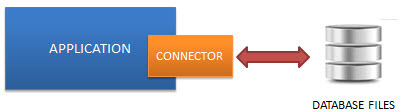
독립실행형
SQLite는 독립 실행형으로 운영 체제나 외부 라이브러리의 지원이 최소한으로 필요합니다. 따라서 iPhone, Android 전화, 게임 콘솔, 휴대용 미디어 플레이어 등과 같은 임베디드 장치의 모든 환경에서 SQLite를 사용할 수 있습니다.
SQLite는 ANSI-C를 사용하여 개발되었습니다. 소스 코드는 sqlite3.c 및 헤더 파일 sqlite3.h로 사용할 수 있습니다. SQLite를 사용하는 애플리케이션을 개발하려면 이 파일을 프로젝트에 포함하고 컴파일하면 됩니다.
zero-configuration
서버리스 아키텍처로 인해 SQLite를 "설치"할 필요가 없습니다. 구성, 시작 및 중지해야 하는 서버 프로세스가 없습니다.
또한 SQLite는 구성 파일을 사용하지 않습니다.
transaction
SQLite의 모든 트랜잭션은 완전히 ACID를 준수합니다. 이는 모든 쿼리 및 변경 사항이 Atomic, Consistent, Isolated 및 Durable 임을 의미합니다.즉, 응용 프로그램 충돌, 정전 또는 운영 체제 충돌과 같은 예기치 않은 상황이 발생하더라도 트랜잭션 내의 모든 변경은 완전히 처리되거나 전혀 처리되지(commit or rollback) 않습니다.
SQLite는 트랜잭션과 원자성 동작을 지원하므로 프로그램 충돌이나 정전이 발생하더라도 데이터베이스가 손상되지 않는다.
sqlite3
-
개념: sqlite3는 SQLite 데이터베이스를 사용하기 위한 Python 모듈입니다. 이 모듈을 통해 Python 프로그램에서 SQLite 데이터베이스를 생성하고, 데이터를 조작할 수 있습니다.
-
특징: sqlite3 모듈은 Python 표준 라이브러리의 일부로, 대부분의 Python 배포판에 기본적으로 포함되어 있습니다.
-
용도: Python 개발자들은 sqlite3 모듈을 사용하여 SQLite 데이터베이스에 연결, SQL 쿼리 실행, 데이터베이스 관리 등의 작업을 수행합니다.
connect, cursor 객체란?
Python의 SQLite3 라이브러리에서 connect와 cursor 객체는 SQLite 데이터베이스와 상호작용하는 데 사용됩니다.
-
Connect 객체:
sqlite3.connect()를 호출하여 생성합니다. 이 객체는 데이터베이스 연결을 나타냅니다.connect객체를 통해 SQL 명령을 실행하고, 변경 사항을 COMMIT 하며, 데이터베이스 연결을 닫을 수 있습니다. 예를 들어,conn = sqlite3.connect('database.db')는 지정된 데이터베이스에 연결을 엽니다. -
Cursor 객체: Connect 객체의
cursor()메서드를 사용하여 생성됩니다. Cursor 객체는 SQL 쿼리를 실행하고 결과를 가져오는 데 사용됩니다. 쿼리 결과의 행을 가리키는 포인터 역할을 하여, 데이터를 행별로 읽는 작업과 같은 연산을 수행할 수 있습니다. 예를 들어,cursor = conn.cursor()는 연결로부터 SQL 명령을 실행하기 위한 커서를 생성합니다.
이 객체들은 Python에서 SQLite3 라이브러리를 사용하여 데이터베이스 작업을 수행하는 데 필수적입니다.
connection = sqlite3.connect('videos.db')
print('sqlite3 v: ' + sqlite3.version) # sqlite3 v: 2.6.0
cursor = connection.cursor()
cursor.execute("create table if not exists videos(video_id text, title text, link text)") # table: videos
videos_list = [
("77a6uAOf5-4", "UEFN Test 02 : Load Weapons And Connect Multiplayer Session", "https://www.youtube.com/watch?v=77a6uAOf5-4"),
("NyfQ080LzxU", "UE 5.2 Substrate Practice", "https://www.youtube.com/watch?v=NyfQ080LzxU"),
("eKgb-PRaJug", "[UE] Get Ammo Automatically", "https://www.youtube.com/watch?v=eKgb-PRaJug")
]
cursor.executemany("insert into videos values (?,?,?)", videos_list)
#print database rows
for row in cursor.execute("select * from videos"):
print(row)
cursor.execute("create table if not exists channel(channel_id text)") # table: channel
connection.close()✔ 구현
DB Browser for SQLite 를 활용했다!
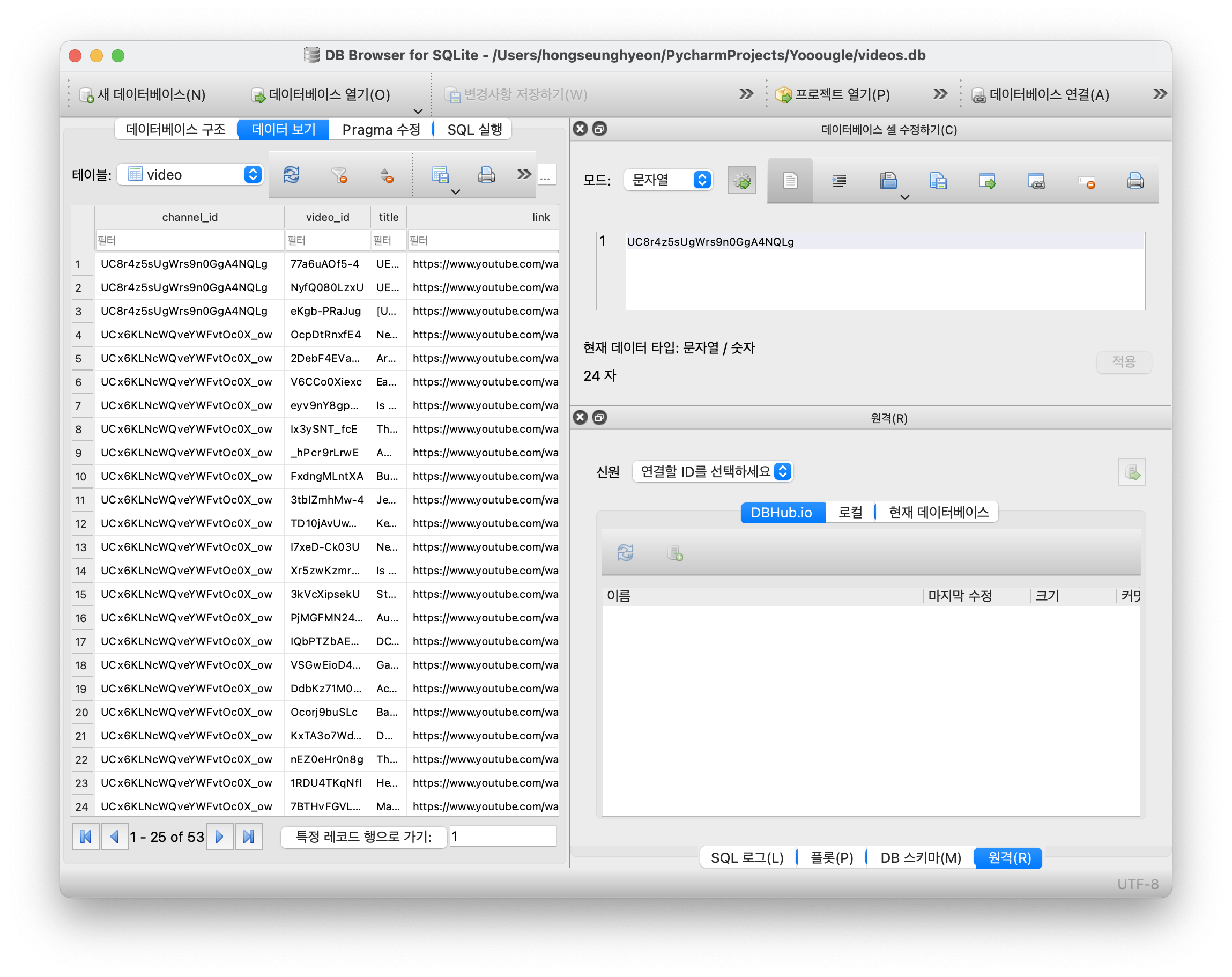
주석을 잘 활용하는 편...
고민한 점 : 테이블 스키마
두 버전 중 어떤 버전을 택해야할지 고민이 많았고, 각 방법의 장단점을 비교해서 autoincrement primary key 를 사용했다.
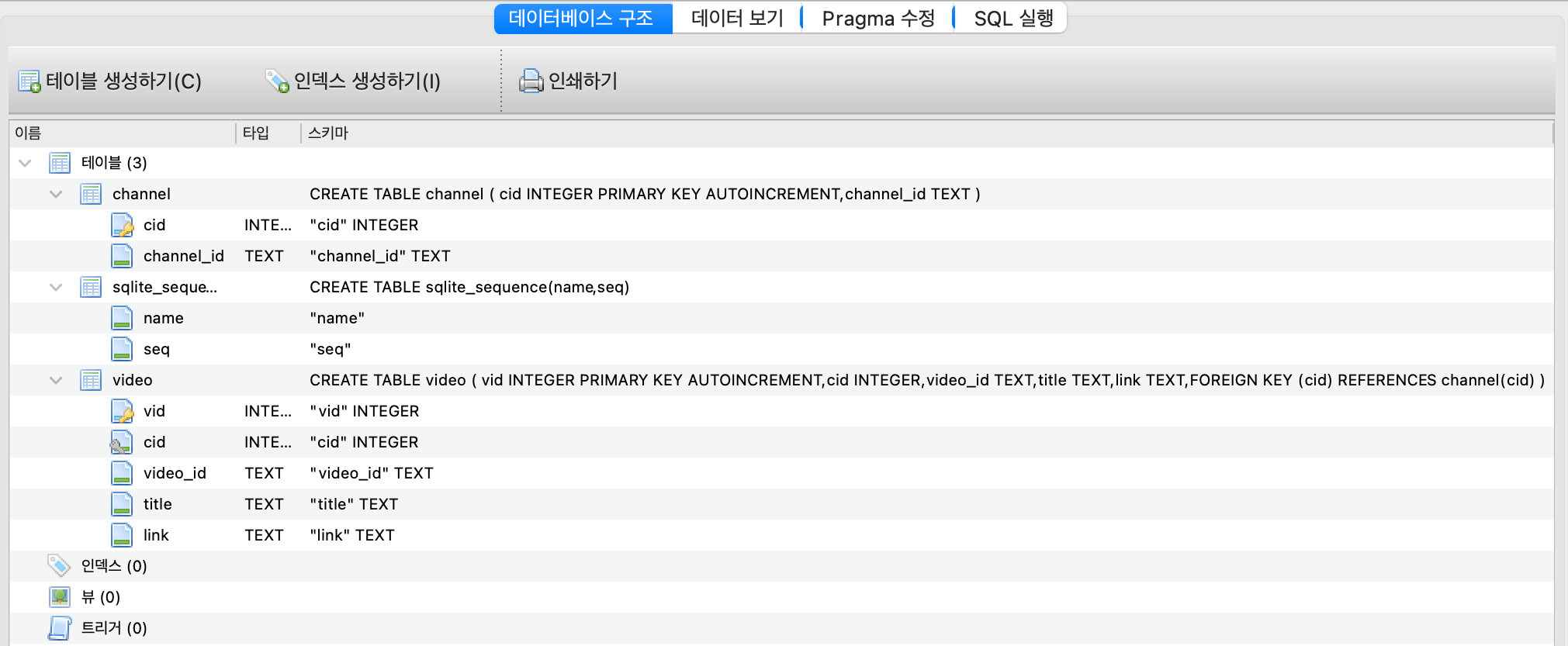
CREATE TABLE channel (
cid INTEGER PRIMARY KEY AUTOINCREMENT,
channel_id TEXT
);
CREATE TABLE video (
vid INTEGER PRIMARY KEY AUTOINCREMENT,
cid INTEGER,
video_id TEXT,
title TEXT,
link TEXT,
FOREIGN KEY (cid) REFERENCES channel(cid)
);첫 번째 방법 : autoincrement primary key 사용
고유 식별자가 필요할 때 사용되며, 일반적으로 편리하지만 모든 시나리오에 적합한 것은 아니라고 한다.
-
장점
-
간단한 데이터베이스 관리와 높은 쿼리 성능이다.
autoincrement정수형 키는 검색 및 정렬 시 빠른 성능을 제공한다. -
autoincrement을 설정하면 이전에 설정된 적이 있는 값이 다시 사용되는 것을 방지할 수 있다. -
또한 데이터 무결성이 보장된다.
cid와vid가 각각channel과video테이블의 자동 증가하는 정수형 기본 키로 설정되어 있어, 각 레코드의 고유성과 무결성을 보장한다. -
개발자가 수동으로 키 값을 관리할 필요가 없어 데이터베이스 관리가 간소화된다.
-
-
단점
-
매우 큰 데이터베이스에서는 자동 증가 키의 관리가 성능에 영향을 줄 수 있다.
-
삭제된 레코드의 키 값은 재사용되지 않으므로, 키 값이 시간이 지남에 따라 커질 수 있다.
-
키가 비즈니스 로직이나 데이터 내용과 관련이 없어 데이터의 의미를 직접적으로 파악하기 어렵다는 점이다.
-
CREATE TABLE channel (
channel_id TEXT PRIMARY KEY
);
CREATE TABLE video (
video_id TEXT PRIMARY KEY,
channel_id TEXT NOT NULL,
title TEXT NOT NULL,
link TEXT NOT NULL,
FOREIGN KEY (channel_id) REFERENCES channel(channel_id)
);두 번째 방법 : 텍스트 기반 primary key 사용
-
장점
- 데이터 간의 관계를 명확하게 나타내고, 데이터의 의미를 쉽게 이해할 수 있다는 장점이 있다.
-
단점
-
하지만 텍스트 기반 키는 정수형 키에 비해 데이터베이스 검색 및 정렬 작업에서 성능이 떨어질 수 있다. 텍스트는 처리 과정에서 더 많은 메모리를 사용하고, 정수보다 비교 속도가 느릴 수 있기 때문이다.
- 왜? 텍스트는 정수에 비해 더 많은 메모리를 사용한다. 특히, 긴 문자열은 더 많은 공간을 차지한다. 또한 문자열 비교 연산은 정수 비교 연산보다 느리다. 따라서 검색, 정렬 등의 데이터베이스 작업이 더 많은 시간을 소요할 수 있다.
-
고민한 점 : JOIN
JOIN은 두 표를 ‘옆으로 ‘ 이어 붙이는 연산이다. 정의하자면 “두 개 이상의 그리드를 (가로 방향으로) 연결해서 하나의 그리드처럼 만드는” 것이다. 테이블은 말 그대로 표이며, 두 개의 표를 옆으로 이어붙이는 것이라 이해하면 된다.
하지만 표가 그려진 두 장의 종이를 나란히 둔다고 해서 표가 결합하는 것은 아니다. 논리적으로 두 개의 표를 옆으로 이어붙이기 위해서는, 두 표가 이치에 맞게 연결되도록 하는 일종의 ‘접합점’ 이 필요하다. 이는 각 표의 행들이 연결될 수 있어야 함을 의미하는데, 보통은 공통적으로 가지고 있는 필드값을 그 접점으로 하게 된다.
예를 들어 발매된 음반의 정보를 담고 있는 albums라는 테이블과 수록곡이 등재된 tracks라는 테이블이 있다고 가정하자. tracks 테이블에는 각각의 트랙이 수록된 앨범 정보를 나타내는 album_id 라는 칼럼이 있고, 이 칼럼은 albums 테이블의 id 칼럼을 참조하는 외래 키(foreign key)로 설정되어 있다고 하자. (물론 JOIN을 위해서 꼭 외래키로 지정되어 있을 필요는 없다. 그저 공통된 값이 있으면 된다.) 그렇다면 tracks 테이블의 album_id 칼럼과 albums 테이블의 id 칼럼을 접합점으로 한다면, 두 테이블을 연결할 수 있다. 이렇게 연결된 테이블을 사용하면 특정한 노래에 대해서 노래가 수록된 앨범의 제목이나 앨범의 발매 년도 등, 앨범 관련한 정보를 함께 망라한 표를 얻게 된다.
💡 그러나 우리의 프로젝트에서 사용되는 테이블 2개에게는 그 접합점이 존재하지 않았다. 어떻게 해야할까?
-
SQLite3는 세 가지 조인 방식을 지원하고 있는데,INNER JOIN (또는 JOIN),LEFT OUTER JOIN (또는 LEFT JOIN),CROSS JOIN이 그것이다. SQLite는 기본적으로 RIGHT OUTER JOIN과 FULL OUTER JOIN을 직접 지원하지 않는다. 이러한 조인의 결과를 얻고자 할 때는 다른 방식(예: LEFT JOIN과 UNION의 조합)을 사용해야 한다.
(보다 큰 규모의 다른 DBMS에서는RIGHT JOIN이나OUTER JOIN,FULL OUTER JOIN등의 옵션도 지원하는 경우가 있다)-
INNER JOIN은 가장 흔하게 쓰이는 JOIN 방식으로 두 개의 테이블이 공통된 칼럼을 가지고 있고, 해당 칼럼의 값이 같은 레코드끼리 연결한다. 이 때 두 그리드가 연결된 결과는 맞물리는 칼럼에 대한 교집합과 비슷하다. 만약 트랙 테이블의 데이터 중 앨범값이 앨범 테이블에 없거나, 반대로 앨범 테이블에는 있지만, 그 수록곡이 트랙 테이블에 없다면 이런 데이터들은 결과에서 제외된다. -
LEFT JOIN은 말 그대로 접합부의 왼쪽 그리드를 기준으로 삼는 JOIN 방식이다. 따라서 INNER JOIN과는 달리 일치하는 값이 없는 경우라도 접합점의 왼쪽에 있는 테이블의 행은 알 수 없는 값을 모두 NULL로 채워서 결과를 만든다. 따라서 기준이 되는 테이블에서는 누락되는 행 없이 결과를 조회할 수 있다. -
CROSS JOIN의 결과는 매우 크고 관리하기 어려울 수 있으므로, 이 방법을 사용할 때는 주의가 필요하다. 한 테이블의 모든 행과 다른 테이블의 모든 행을 조합하므로 결과 세트가 매우 클 수 있으며, 데이터 간에 실제 관계가 없기 때문에 유용한 정보를 제공하지 않을 수도 있다.
-
-
JOIN을 사용하지 않는다면..? 데이터베이스 쿼리가 아닌, 애플리케이션 로직에서 두 데이터 세트를 별도로 처리하고, 필요한 정보를 결합하여 사용한다. 예를 들어, Python에서 두 데이터 세트를 딕셔너리나 리스트로 가져온 후, 프로그램에서 로직을 적용하여 결합할 수 있다. -
인공키를 사용한다면..? 데이터 무결성을 유지하기 어려울 수 있다. 두 테이블 간에 실제 관계가 없는데 관계를 강제로 만들어내면, 오류가 발생하기 쉽고 데이터 무결성을 보장하기 어려워진다.
💡 즉 어떠한 형태로든
JOIN연산을 하려면 공통 필드가 있어야 한다.
######### 사용자로부터 입력받은 channel_id로, video 테이블과 channel 테이블 JOIN #########
def innerjoin_videos_by_channel_id(channel_id):
with sqlite3.connect('videos.db') as connect:
cursor = connect.cursor()
cursor.execute("SELECT cid FROM channel WHERE channel_id = ?", (channel_id,))
channel_cid = cursor.fetchone()
if channel_cid:
query = """
SELECT video.vid, video.video_id, video.title, video.link
FROM video
INNER JOIN channel ON video.cid = channel.cid
WHERE channel.cid = ?
"""
cursor.execute(query, (channel_cid[0],))
rows = cursor.fetchall()
# JSON 파일에 저장할 비디오 정보 생성
video_info = [{"channel_id": row[0], "video_id": row[1], "title": row[2], "link": row[3]} for row in rows]
# 결과를 JSON 파일로 저장
channel_info = {
"channel_id": channel_id,
"videos": video_info
}
with open(f'info_{channel_id}.json', 'w', encoding='utf-8') as f:
json.dump(channel_info, f, indent=4, ensure_ascii=False)
print(f"채널 ID와 각 동영상의 정보가 'info_{channel_id}.json' 파일로 저장되었습니다.")
# 함수 반환 값은 비디오 링크만 포함하는 리스트
return [row[3] for row in rows]고민한 점 : 중복 check
check_channel_id_in_tables() 에서 체크한다.
# app.py
app = Flask(__name__)
app.config['SECRET_KEY'] = '~' # CSRF 보호를 위한 비밀 키 설정
@app.route('/', methods=['GET', 'POST'])
def index():
videos_list_result = []
channel_id = ''
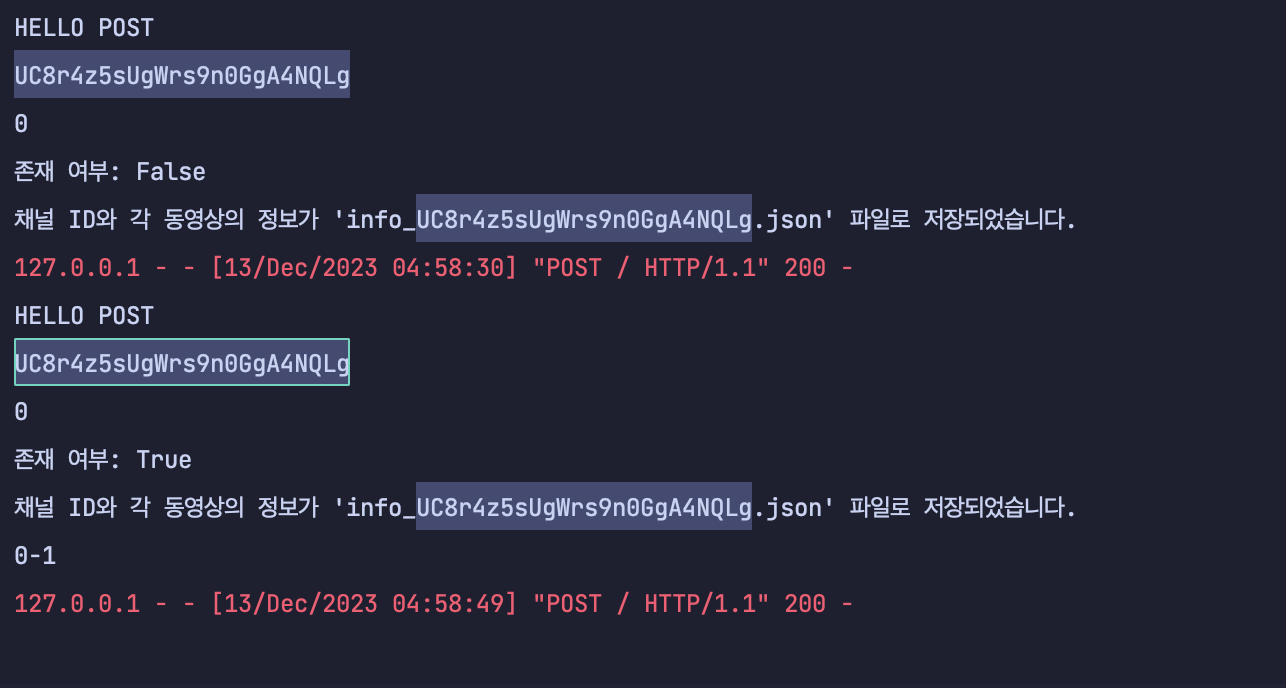
if request.method == 'POST':
print('HELLO POST')
channel_id = request.form['channel_id']
if channel_id != '':
print(channel_id)
exists = videos_db_query.check_channel_id_in_tables(channel_id)
print("0")
if exists is True:
print(f"존재 여부: {exists}")
# db 에서 video_link를 모두 불러와서 videos_list_result 에 저장, db에서 해당 video의 정보를 json 파일 저장
videos_list_result = videos_db_query.innerjoin_videos_by_channel_id(channel_id)
print("0-1")
elif exists is False:
print(f"존재 여부: {exists}")
videos_list_result = main.get_channel_videos_and_save(channel_id)
return render_template('index.html', videos=videos_list_result, channel_id=channel_id)
# videos_db_query.py
######### 사용자로부터 입력받은 channel_id로, video 테이블과 channel 테이블 존재 여부 확인 #########
def check_channel_id_in_tables(channel_id):
with sqlite3.connect('videos.db') as connect:
cursor = connect.cursor()
cursor.execute("SELECT cid FROM channel WHERE channel_id = ?", (channel_id,))
channel_cid = cursor.fetchone()
if channel_cid:
cursor.execute("SELECT EXISTS (SELECT 1 FROM video WHERE cid = ?)", (channel_cid[0],))
return cursor.fetchone()[0] == 1
return False