
SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo
다중 스케일 기능을 출력하는 새로운 계층 구조의 Transformer encoder로 구성되며, positional encoding이 필요하지 않으므로 훈련 셋과 테스트 셋의 해상도 차이를 극복할 수 있음.
SegFormer-B4는 64M 매개변수를 사용하여 ADE20K에서 약 50.3% mIoU를 달성. (이전 방법보다 약 2.2% 상승)
Semantic segmentation은 Computer vision의 기본 작업임.
이미지 수준이 아닌 픽셀별 카테고리 예측을 만들어 냄. 이를 통해 classification과 연관이 있다.
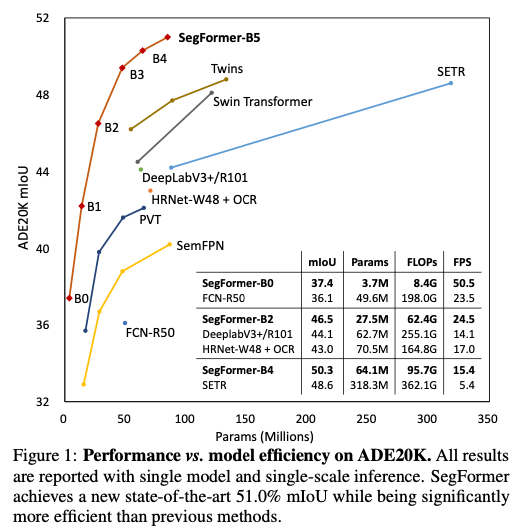
본 논문에 제공한 Params에 따른 ADE20K mIoU 그래프를 보면 초기 모델보다 약 10% 이상 증가한 것을 볼 수 있다.
classification과 semantic segmentation은 strong relation이 있어서 최근 semantic segmentation framework는 classification를 위해 사용되는 아키텍처의 변형된 모습이 보인다.
ViT의 등장
NLP에서 Transformer을 이용한 방법이 크게 성공하며 Dosovitskiy et al.은 최근 vision tasks에도 Transformer을 도입하기 위해 ViT(Vision Transformer)를 제안하였다.
Following the Transformer design in NLP, the authors split an image into multiple linearly embedded patches and feed them into a standard Transformer with positional embeddings (PE), leading to an impressive performance on ImageNet 출처
또한 Zheng et al.은 Semantic Segmentation에서 Transformer를 사용하기 위해 SETR을 제안하였다.
1. ViT는 single-scale low-resolution features를 사용하는데,
Single Scale (단일 스케일) 입력 데이터의 크기나 해상도가 모두 동일하게 유지되지만 다른 스케일의 정보는 누락되는 반면,
Multiscale (다중 스케일)에서는 입력 데이터의 다양한 크기 또는 스케일을 다루고, 출력된 특징 데이터에는 여러 스케일의 정보가 포함되기 때문에 limitations이 있다.
2. 큰 이미지에 대해서 computation cost가 높다.
위와 같은 한계를 해결하기 위해 Wang et.al은 PVT(pyramid vision Transformer)를 제안하였다.
semantic segmentation는 픽셀 간 분류를 수행하지만 여전히 computation cost가 높다.
ViT는 각 이미지를 토큰으로 나누어 다른 Transformer layers에 분류를 만들기 위해 전달한다. SERT은 특징 추출을 위한 백본으로 ViT를 선정하였고, 좋은 성능을 발휘하였지만, 효율성이 매우 낮기 때문에 real-time application에 적용하기 어렵다.
본 논문에서는 ViT와 아키텍처는 동일하지만 크기가 다른 MiT serise를 설계하여 MiT-(B0~B5)까지 성능과 크기에 맞춰진 모델을 제안한다. 단일 해상도 기능맵만 생성하는 ViT와 달리 CNN처럼 multi-level features를 생성한다.
encoder의 주요 computation bottleneck은 self-attentation layer이다.
위 함수의 시간복잡도는 이며, 큰 이미지는 사용할 수 없다.
이를 개선하기 위해 Recudtion ratio R을 도입하여
여기서 K는 축소할 시퀀스이고 K는 형태이며 Linear함수는 차원 텐서를 입력으로 받아 차원 텐서를 출력으로 생성하는 선형 레이어이다.
따라서 self-attentation 메커니즘은 에서 로 줄어든다.
Mix-FFN ViT는 위치 정보를 나타내기 위해 위치 인코딩을 사용하지만 resolution이 고정되어 있어서 테스트셋 해상도와 훈련 셋 해상도가 다를 경우 정확도가 떨어지는 경우가 많다.
따라서 data-driven PE인 Mix-FFN을 구현하여 위치 정보에 대한 제로 패딩 효과를 나타낸다.
All-MLP Decoder
- MiT 인코더의 다중 label 기능 는 channel dimention을 통합하기 위해 MLP 레이어를 거친다.
- 그런 다음 기능이 1/4로 up-sampling되고, 함께 연결(F)된다.
세번째로, 연결된 특징 F를 fuse하기 위해 MLP레이어가 선택된다. - F를 사용하기 위해 , , (범주 수) 해상도로 분할 마스크 M을 예측한다.
여기서 M은 예측된 마스크를 나나태고 Linear은 을 각각 입력 및 출력 벡터 차원으로 사용하는 선형 레이어를 나타낸다.
Effective Receptive Field Analysis
Simentic Segmentation은 컨텍스트 정보를 포함하기 위해 큰 receptive field를 유지해야 한다.
Powerful designs compared with SETR
SegFormer contains multiple more efficient and powerful designs compared with SETR:
• We only use ImageNet-1K for pre-training. ViT in SETR is pre-trained on larger ImageNet-22K.
5
• SegFormer’s encoder has a hierarchical architecture, which is smaller than ViT and can capture both high-resolution coarse and low-resolution fine features. In contrast, SETR’s ViT encoder can only generate single low-resolution feature map.
• We remove Positional Embedding in encoder, while SETR uses fixed shape Positional Embedding which decreases the accuracy when the resolution at inference differs from the training ones.
• Our MLP decoder is more compact and less computationally demanding than the one in SETR. This leads to a negligible computational overhead. In contrast, SETR requires heavy decoders with multiple 3×3 convolutions.
위치 인코딩이 필요 없는 hierarchical Transformer encoder와 All-MLP decoder를 포함하는 간단한 Segformer를 제시하였다.
복잡한 설계를 피해 효율성과 성능을 높인 좋은 예시가 되는 접근 방법이었다.
