You Only Look Bounding Box for Polyp Segmentation 예제 코드

WeakPolyp: You Only Look Bounding Box for Polyp Segmentation
Jun Wei, Yiwen Hu, Shuguang Cui, S.Kevin Zhou, Zhen
논문을 선정한 이유
- 데이터 부족으로 인한 문제를 M2B(Mask to Box) 변환 방법으로 labeling cost를 줄일 수 있는 방법을 제시.
- 흥미로운 접근 방법을 제시하였음.
Abstract

polyp bounding box annotations은 훨씬 저렴하고 접근성이 높다.
bounding box annotations을 이용하여 약하게(weak) train된 모델을 제안한다.
이러한 weak train을 완화하기 위해 scale consistency을 통한 예측의 변동을 줄인다.
plug-and-play model로, backborn으로 쉽게 porting할 수 있다.
Introduction
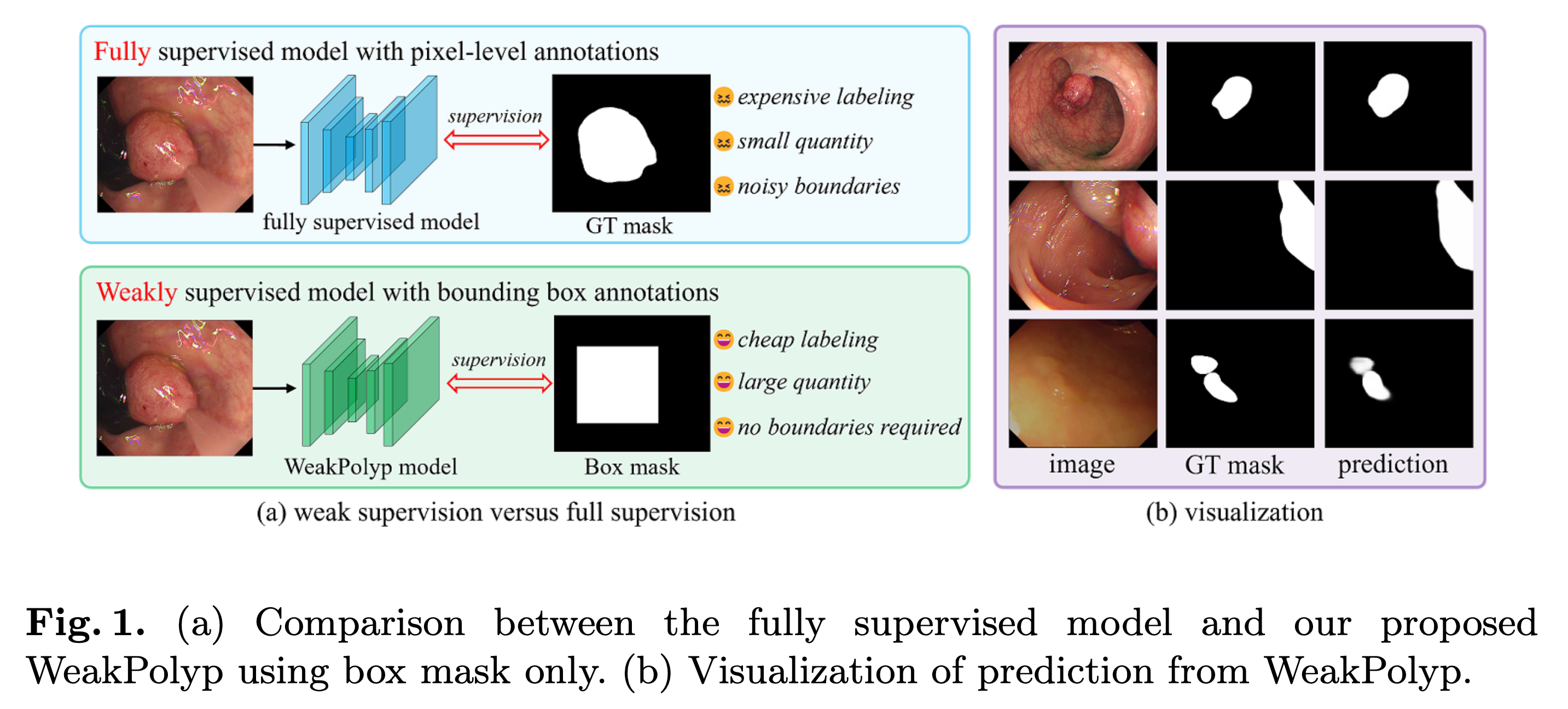
기존 모델과의 차이점
(Fully supervised model with pixel-level annotations)
기존 모델의 특징
- pixel-level annotations은 시간이 많이 걸리고 비용이 많이 든다.
- 또한 많은 Polyp들은 분명한 경계를 가지고 있지 않기 때문에 주관적 noise를 도입한다.
따라서 이러한 한계를 해결하기 위해 일반화(Generalization)된 모델이 필요함.
본 모델(WeakPolyp)은 bounding box만을 학습하기 때문에 labeling cost를 크게 절감할 수 있다.
하지만 단순히 bounding box만을 train하는 것은 배경 noise가 너무 많다.
그럼에도 위 그림에서 볼 수 있듯이 Fully supervise model과 비슷한 성능을 가진다.
WeakPolyp:
You Only Look Bounding Box for Polyp Segmentation
Mask-To-Box(M2B) 변환과 Scale Consistency(SC) Loss를 사용한다.
M2B는 예측 마스크를 상자와 같은 마스크로 변환하는데 적용하고 train된다.
투영에서 많은 손실이 되므로 pixel-level의 train을 제공하기 위해 SC Loss를 이용하여,
By forcing feature alignment, it inhibits the excessive diversity of predictions, thus improving the model generalization.
모델이 특성 일치를 강제함으로써 예측의 다양성을 억제하고, 이를 통해 모델의 일반화 능력을 향상시키는 것이 중요하다.
특성 일치란 모델에서 학습된 특성(데이터의 중요한 부분)이 서로 비슷하게 유지되도록 하는 것을 의미한다.
Model Components
크게 segmentation(분할) phase와 supervision(감독) phase로 나뉜다
Res2Net을 backborn으로 이용하여 Input Image 에 대하여 Res2Net은 해상도 에서 4개의 features를 추출한다.
- 각 입력 이미지 에 대하여 and 로 두 가지 다른 스케일로 크기를 조정한다.
segmentation model로 보내어 두 개의 예측 마스크 과 를 얻는다.- 과 사이의 거리를 줄이기 위해
SC Loss를 적용한다. - 과 를 M2B 적용하여 box-like masks 과 로 변환한다.
binary cross entropy(BCE) loss와Dice loss를 계산한다.
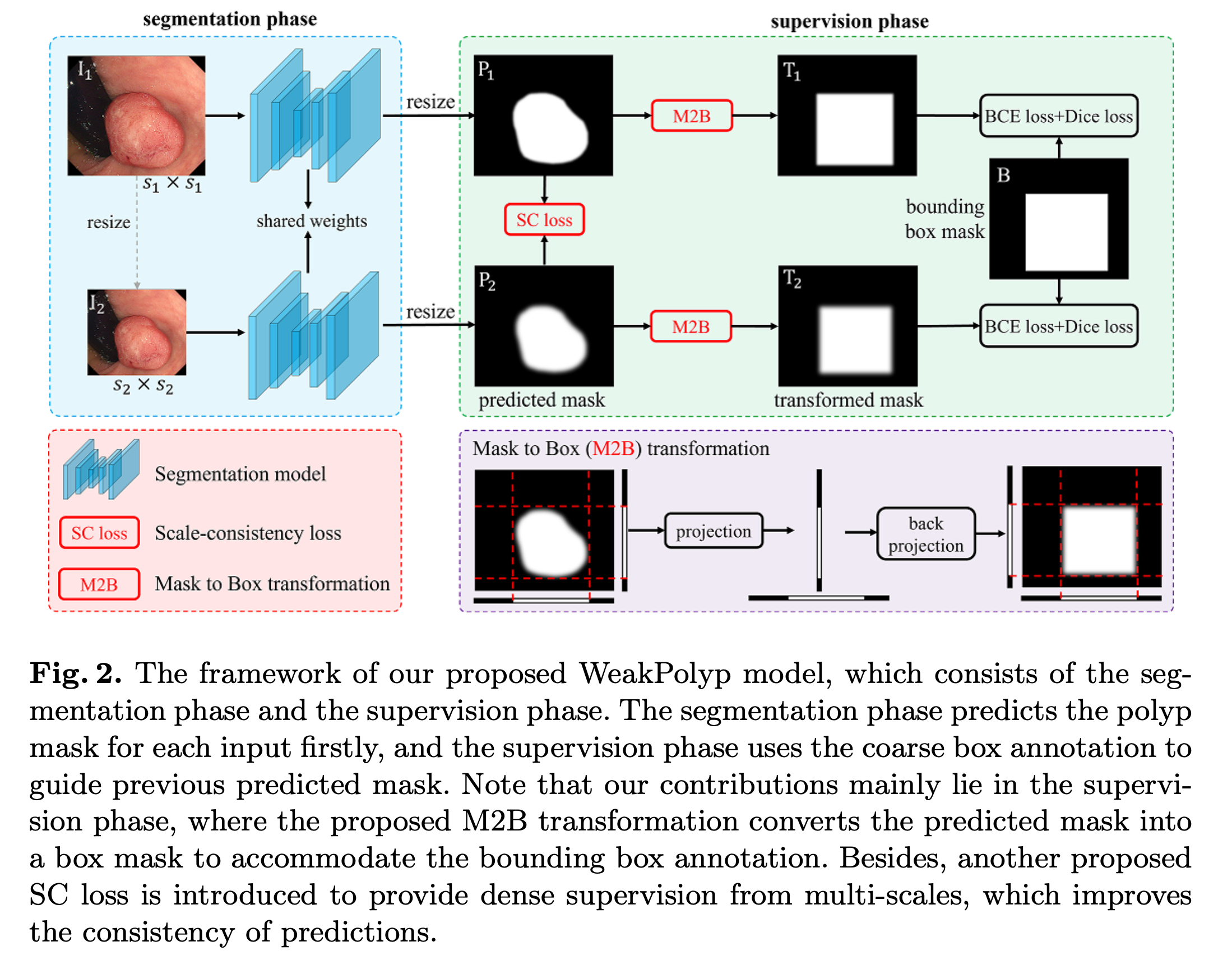
Mask-to-Box (M2B) Transformation
segmentation model에서 나온 결과값인 , 를 supervised하는 것은 일반화가 좋지 않다.
따라서 과 의 bounding box mask인 과 를 supervised한다.
M2B Transformation은 projection과 back-projection을 이용하여 구현한다.
Projection
예측된 마스크 가 주어지면 와 , 두 개의 벡터로 수평 및 수직으로 projection을 한다.
- average pooling대신 max pooling을 이용한다. 왜냐하면 Polyp의 형상 정보를 완전히 제거할 수 있기 때문이다.
- 프로젝션 후 와 에는 polyp의 위치와 범위만 저장된다.
Back-Projection
와 를 바탕으로 bounding box mask를 구성한다.
와 는 같은 크기의 과 로 반복되어 가장 최소값을 취한다.
repeat axis
repeat axis
min
각각 로 변환된다. 는 모두 같은 마스크이기 때문에 supervision loss인 BCE loss와 Dice loss를 계산한다.
단순 변환을 통해 M2B는 예측된 마스크가 polyp의 윤곽을 보존할 수 있다.
Scale Consistency (SC) Loss
의 대부분의 픽셀들이 Projection에서 무시되므로 는 물체 영역 내에서 픽셀 간의 거리를 줄이는 것을 목표로 한다.
이것은 물체의 예측이 유일하지 않은 상황에서 예측의 다양성을 줄이기 위한 추가적인 손실 함수이다.
따라서 과 를 결합하면 WeakPolyp 모델을 얻을 수 있다.
모델 구조를 변경하지 않고 단순히 Supervise loss를 대체하기 때문에 다른 모델로 porting할 수 있다.
또한 과 는 train 중에만 이용되기 때문에 모델의 속도에 영향을 미치지 않는다.
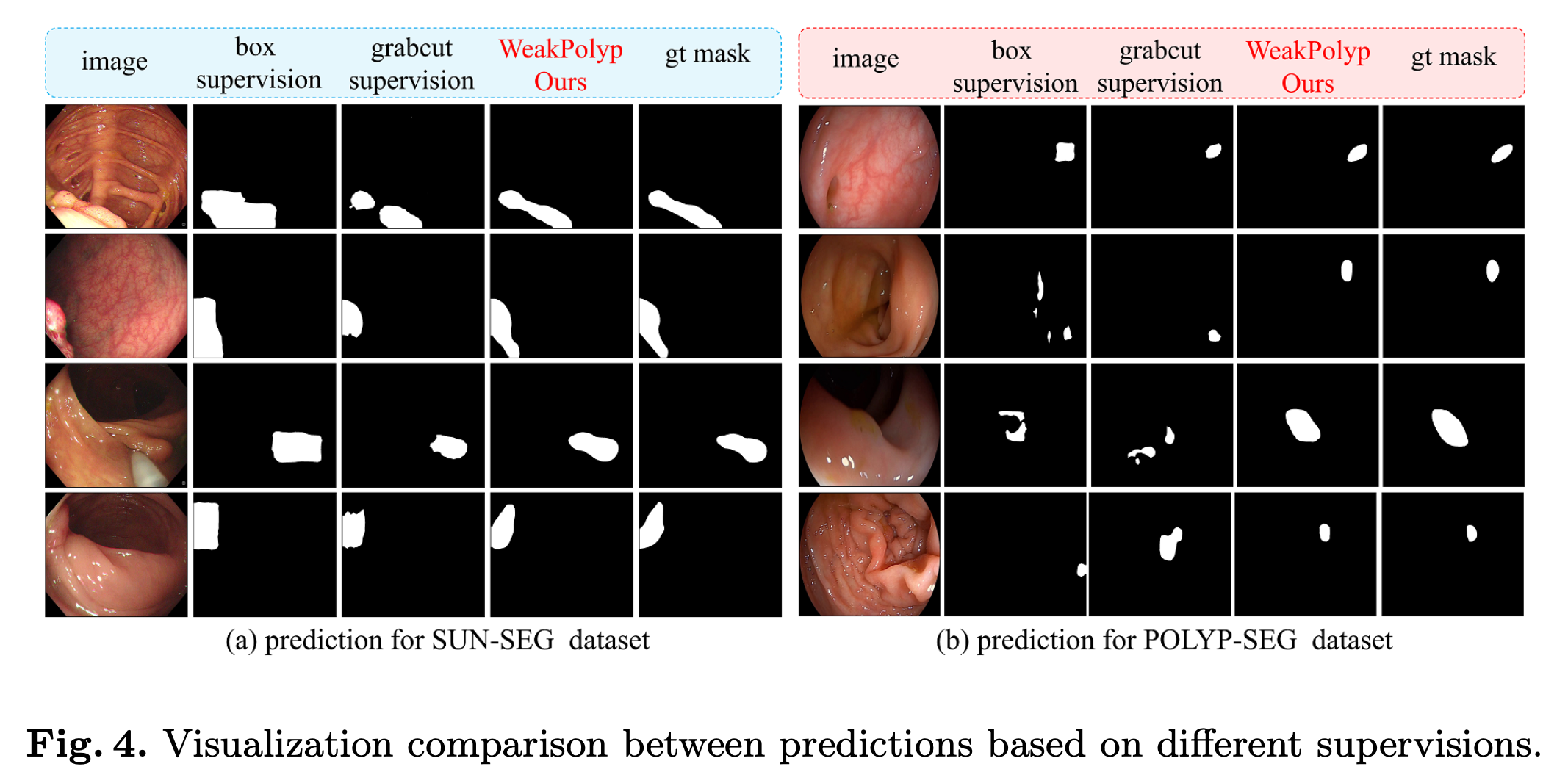
- WeakPolyp는 PyTorch를 사용하여 구현되고, 모든 이미지는 352 * 352로 균일하게 조정된다.
- 전체 성능 순서는 gt > WeakPolyp > box > gradcut이고, WeakPolyp는 box mask로 supervised된 모델보다 성능이 뛰어나다.
- 이유는 annotations box-shape bias에 영향을 받지 않기 때문이다.
pixel-level의 noise가 많으면 Fully supervised model의 성능을 뛰어넘기도 한다.
결론
pixel-level의 annotation의 subjective noise labels를 피할 수 있고, 레이블링에 대한 모델의 의존성을 더욱 줄일 수 있다.
